 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearnable Motion-Focused Tokenization for Effective and Efficient Video Unsupervised Domain Adaptation
Apr 10, 2026Video Unsupervised Domain Adaptation (VUDA) poses a significant challenge in action recognition, requiring the adaptation of a model from a labeled source domain to an unlabeled target domain. Despite recent advances, existing VUDA methods often fall short of fully supervised performance, a key reason being the prevalence of static and uninformative backgrounds that exacerbate domain shifts. Additionally, prior approaches largely overlook computational efficiency, limiting real-world adoption. To address these issues, we propose Learnable Motion-Focused Tokenization (LMFT) for VUDA. LMFT tokenizes video frames into patch tokens and learns to discard low-motion, redundant tokens, primarily corresponding to background regions, while retaining motion-rich, action-relevant tokens for adaptation. Extensive experiments on three standard VUDA benchmarks across 21 domain adaptation settings show that our VUDA framework with LMFT achieves state-of-the-art performance while significantly reducing computational overhead. LMFT thus enables VUDA that is both effective and computationally efficient.
HiTSR: A Hierarchical Transformer for Reference-based Super-Resolution
Aug 30, 2024



In this paper, we propose HiTSR, a hierarchical transformer model for reference-based image super-resolution, which enhances low-resolution input images by learning matching correspondences from high-resolution reference images. Diverging from existing multi-network, multi-stage approaches, we streamline the architecture and training pipeline by incorporating the double attention block from GAN literature. Processing two visual streams independently, we fuse self-attention and cross-attention blocks through a gating attention strategy. The model integrates a squeeze-and-excitation module to capture global context from the input images, facilitating long-range spatial interactions within window-based attention blocks. Long skip connections between shallow and deep layers further enhance information flow. Our model demonstrates superior performance across three datasets including SUN80, Urban100, and Manga109. Specifically, on the SUN80 dataset, our model achieves PSNR/SSIM values of 30.24/0.821. These results underscore the effectiveness of attention mechanisms in reference-based image super-resolution. The transformer-based model attains state-of-the-art results without the need for purpose-built subnetworks, knowledge distillation, or multi-stage training, emphasizing the potency of attention in meeting reference-based image super-resolution requirements.
DVOS: Self-Supervised Dense-Pattern Video Object Segmentation
Jun 07, 2024



Video object segmentation approaches primarily rely on large-scale pixel-accurate human-annotated datasets for model development. In Dense Video Object Segmentation (DVOS) scenarios, each video frame encompasses hundreds of small, dense, and partially occluded objects. Accordingly, the labor-intensive manual annotation of even a single frame often takes hours, which hinders the development of DVOS for many applications. Furthermore, in videos with dense patterns, following a large number of objects that move in different directions poses additional challenges. To address these challenges, we proposed a semi-self-supervised spatiotemporal approach for DVOS utilizing a diffusion-based method through multi-task learning. Emulating real videos' optical flow and simulating their motion, we developed a methodology to synthesize computationally annotated videos that can be used for training DVOS models; The model performance was further improved by utilizing weakly labeled (computationally generated but imprecise) data. To demonstrate the utility and efficacy of the proposed approach, we developed DVOS models for wheat head segmentation of handheld and drone-captured videos, capturing wheat crops in fields of different locations across various growth stages, spanning from heading to maturity. Despite using only a few manually annotated video frames, the proposed approach yielded high-performing models, achieving a Dice score of 0.82 when tested on a drone-captured external test set. While we showed the efficacy of the proposed approach for wheat head segmentation, its application can be extended to other crops or DVOS in other domains, such as crowd analysis or microscopic image analysis.
DARTS: Double Attention Reference-based Transformer for Super-resolution
Jul 17, 2023



We present DARTS, a transformer model for reference-based image super-resolution. DARTS learns joint representations of two image distributions to enhance the content of low-resolution input images through matching correspondences learned from high-resolution reference images. Current state-of-the-art techniques in reference-based image super-resolution are based on a multi-network, multi-stage architecture. In this work, we adapt the double attention block from the GAN literature, processing the two visual streams separately and combining self-attention and cross-attention blocks through a gating attention strategy. Our work demonstrates how the attention mechanism can be adapted for the particular requirements of reference-based image super-resolution, significantly simplifying the architecture and training pipeline. We show that our transformer-based model performs competitively with state-of-the-art models, while maintaining a simpler overall architecture and training process. In particular, we obtain state-of-the-art on the SUN80 dataset, with a PSNR/SSIM of 29.83 / .809. These results show that attention alone is sufficient for the RSR task, without multiple purpose-built subnetworks, knowledge distillation, or multi-stage training.
Extending the WILDS Benchmark for Unsupervised Adaptation
Dec 09, 2021

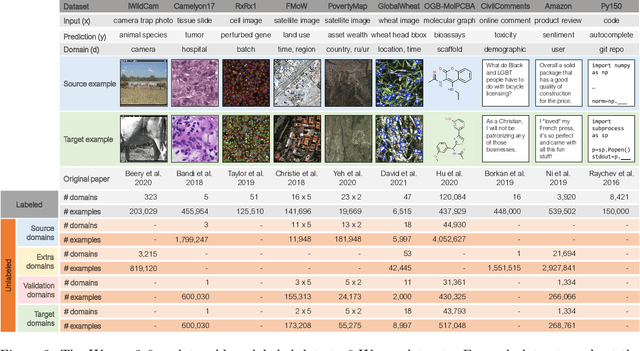
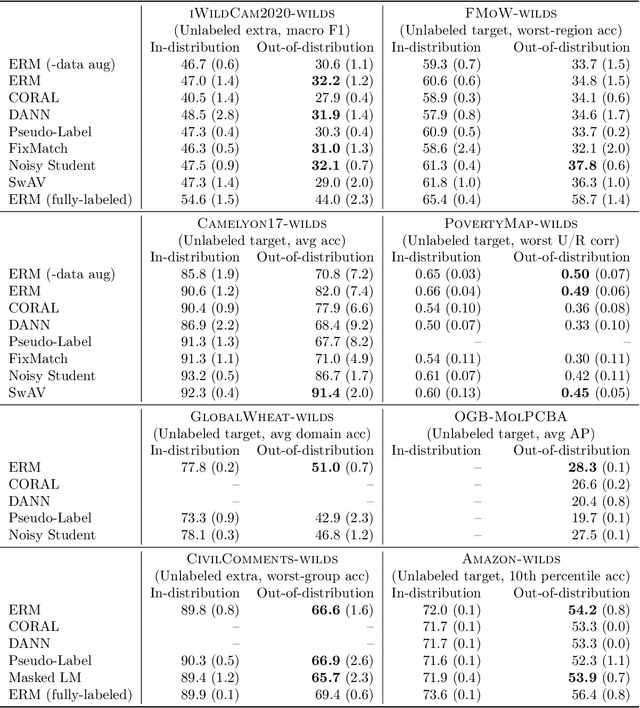
Machine learning systems deployed in the wild are often trained on a source distribution but deployed on a different target distribution. Unlabeled data can be a powerful point of leverage for mitigating these distribution shifts, as it is frequently much more available than labeled data. However, existing distribution shift benchmarks for unlabeled data do not reflect the breadth of scenarios that arise in real-world applications. In this work, we present the WILDS 2.0 update, which extends 8 of the 10 datasets in the WILDS benchmark of distribution shifts to include curated unlabeled data that would be realistically obtainable in deployment. To maintain consistency, the labeled training, validation, and test sets, as well as the evaluation metrics, are exactly the same as in the original WILDS benchmark. These datasets span a wide range of applications (from histology to wildlife conservation), tasks (classification, regression, and detection), and modalities (photos, satellite images, microscope slides, text, molecular graphs). We systematically benchmark state-of-the-art methods that leverage unlabeled data, including domain-invariant, self-training, and self-supervised methods, and show that their success on WILDS 2.0 is limited. To facilitate method development and evaluation, we provide an open-source package that automates data loading and contains all of the model architectures and methods used in this paper. Code and leaderboards are available at https://wilds.stanford.edu.
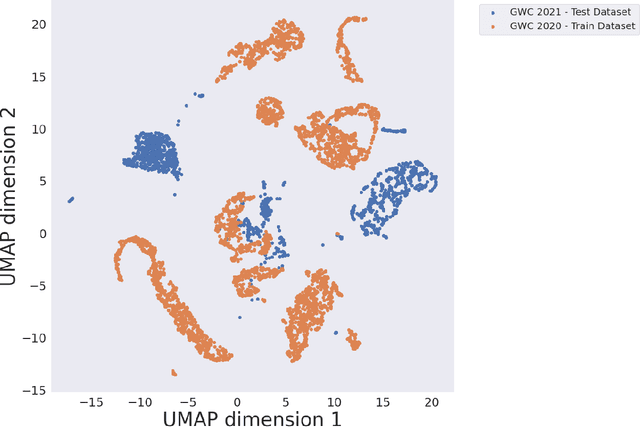
Global Wheat Head Dataset 2021: more diversity to improve the benchmarking of wheat head localization methods
Jun 03, 2021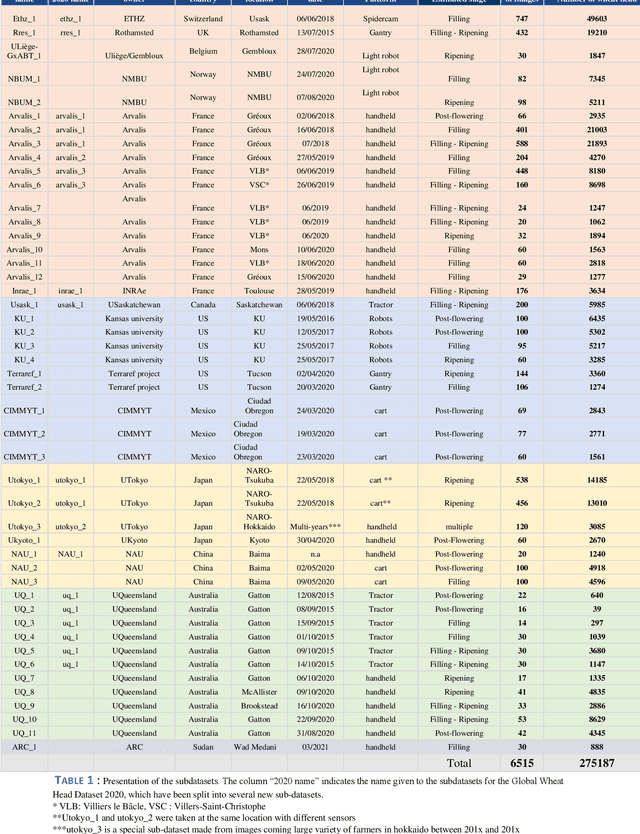
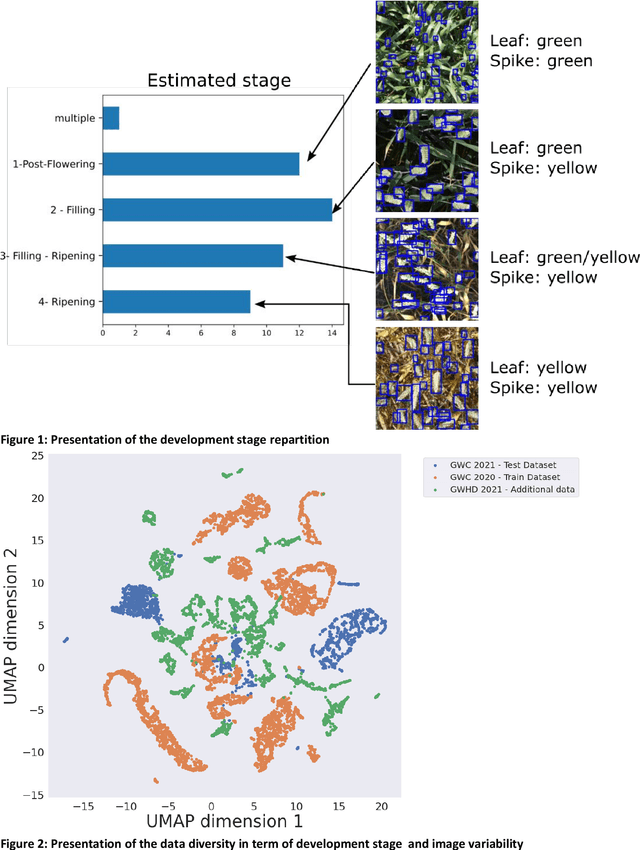
The Global Wheat Head Detection (GWHD) dataset was created in 2020 and has assembled 193,634 labelled wheat heads from 4,700 RGB images acquired from various acquisition platforms and 7 countries/institutions. With an associated competition hosted in Kaggle, GWHD has successfully attracted attention from both the computer vision and agricultural science communities. From this first experience in 2020, a few avenues for improvements have been identified, especially from the perspective of data size, head diversity and label reliability. To address these issues, the 2020 dataset has been reexamined, relabeled, and augmented by adding 1,722 images from 5 additional countries, allowing for 81,553 additional wheat heads to be added. We now release a new version of the Global Wheat Head Detection (GWHD) dataset in 2021, which is bigger, more diverse, and less noisy than the 2020 version. The GWHD 2021 is now publicly available at http://www.global-wheat.com/ and a new data challenge has been organized on AIcrowd to make use of this updated dataset.
Global Wheat Challenge 2020: Analysis of the competition design and winning models
May 13, 2021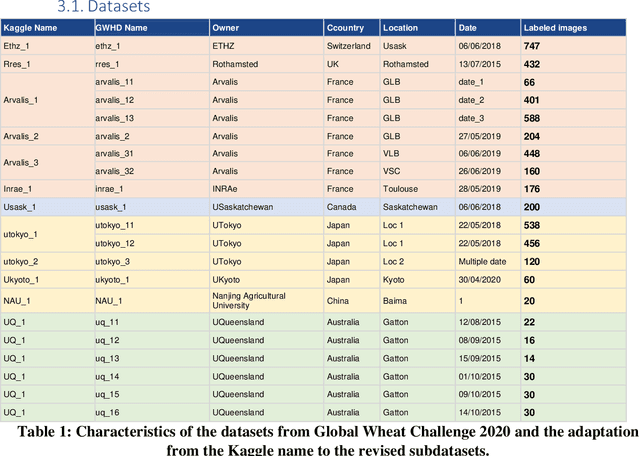

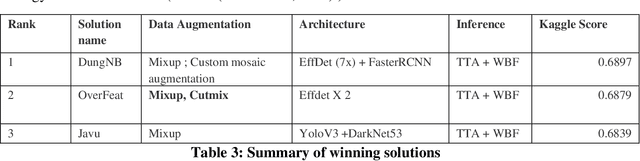
Data competitions have become a popular approach to crowdsource new data analysis methods for general and specialized data science problems. In plant phenotyping, data competitions have a rich history, and new outdoor field datasets have potential for new data competitions. We developed the Global Wheat Challenge as a generalization competition to see if solutions for wheat head detection from field images would work in different regions around the world. In this paper, we analyze the winning challenge solutions in terms of their robustness and the relative importance of model and data augmentation design decisions. We found that the design of the competition influence the selection of winning solutions and provide recommendations for future competitions in an attempt to garner more robust winning solutions.
Pruning Convolutional Filters using Batch Bridgeout
Sep 23, 2020

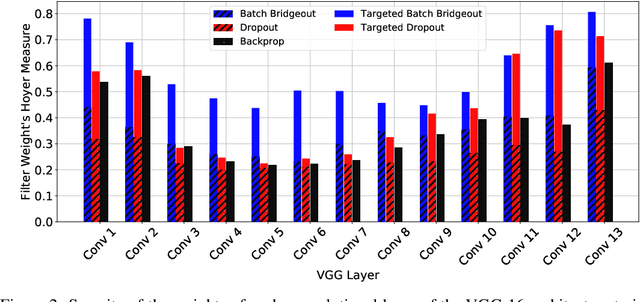
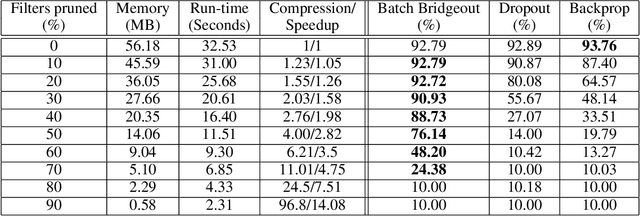
State-of-the-art computer vision models are rapidly increasing in capacity, where the number of parameters far exceeds the number required to fit the training set. This results in better optimization and generalization performance. However, the huge size of contemporary models results in large inference costs and limits their use on resource-limited devices. In order to reduce inference costs, convolutional filters in trained neural networks could be pruned to reduce the run-time memory and computational requirements during inference. However, severe post-training pruning results in degraded performance if the training algorithm results in dense weight vectors. We propose the use of Batch Bridgeout, a sparsity inducing stochastic regularization scheme, to train neural networks so that they could be pruned efficiently with minimal degradation in performance. We evaluate the proposed method on common computer vision models VGGNet, ResNet, and Wide-ResNet on the CIFAR image classification task. For all the networks, experimental results show that Batch Bridgeout trained networks achieve higher accuracy across a wide range of pruning intensities compared to Dropout and weight decay regularization.
Unsupervised Domain Adaptation For Plant Organ Counting
Sep 02, 2020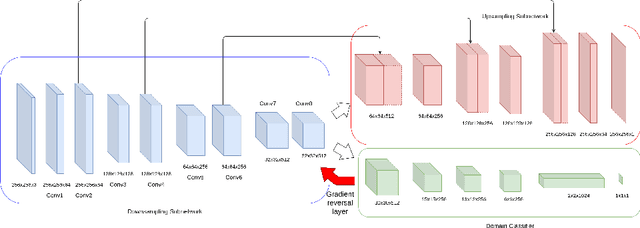
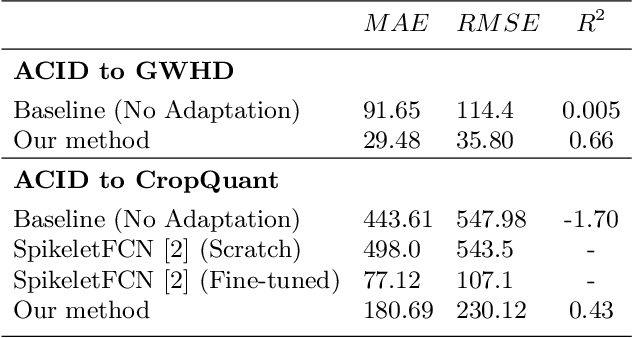

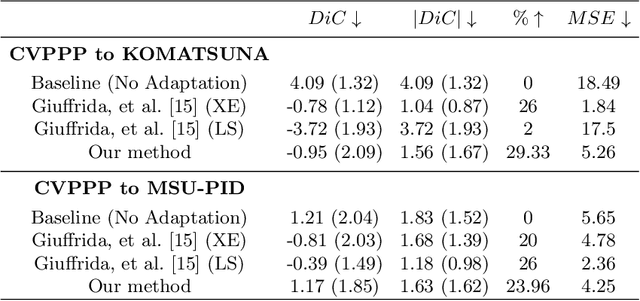
Supervised learning is often used to count objects in images, but for counting small, densely located objects, the required image annotations are burdensome to collect. Counting plant organs for image-based plant phenotyping falls within this category. Object counting in plant images is further challenged by having plant image datasets with significant domain shift due to different experimental conditions, e.g. applying an annotated dataset of indoor plant images for use on outdoor images, or on a different plant species. In this paper, we propose a domain-adversarial learning approach for domain adaptation of density map estimation for the purposes of object counting. The approach does not assume perfectly aligned distributions between the source and target datasets, which makes it more broadly applicable within general object counting and plant organ counting tasks. Evaluation on two diverse object counting tasks (wheat spikelets, leaves) demonstrates consistent performance on the target datasets across different classes of domain shift: from indoor-to-outdoor images and from species-to-species adaptation.
AutoCount: Unsupervised Segmentation and Counting of Organs in Field Images
Jul 17, 2020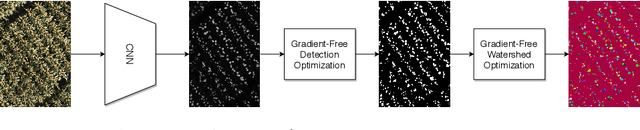

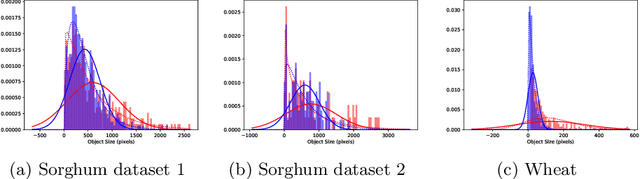

Counting plant organs such as heads or tassels from outdoor imagery is a popular benchmark computer vision task in plant phenotyping, which has been previously investigated in the literature using state-of-the-art supervised deep learning techniques. However, the annotation of organs in field images is time-consuming and prone to errors. In this paper, we propose a fully unsupervised technique for counting dense objects such as plant organs. We use a convolutional network-based unsupervised segmentation method followed by two post-hoc optimization steps. The proposed technique is shown to provide competitive counting performance on a range of organ counting tasks in sorghum (S. bicolor) and wheat (T. aestivum) with no dataset-dependent tuning or modifications.