 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNo True State-of-the-Art? OOD Detection Methods are Inconsistent across Datasets
Paper and Code
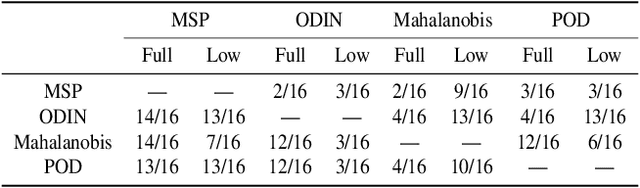
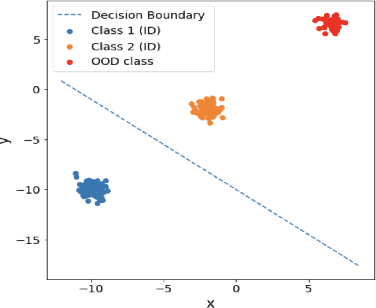
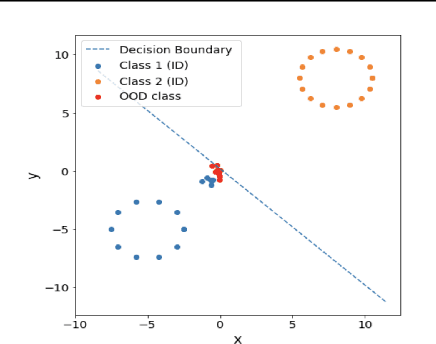
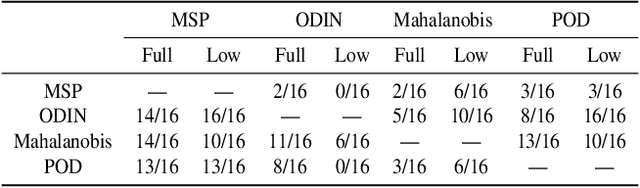
Out-of-distribution detection is an important component of reliable ML systems. Prior literature has proposed various methods (e.g., MSP (Hendrycks & Gimpel, 2017), ODIN (Liang et al., 2018), Mahalanobis (Lee et al., 2018)), claiming they are state-of-the-art by showing they outperform previous methods on a selected set of in-distribution (ID) and out-of-distribution (OOD) datasets. In this work, we show that none of these methods are inherently better at OOD detection than others on a standardized set of 16 (ID, OOD) pairs. We give possible explanations for these inconsistencies with simple toy datasets where whether one method outperforms another depends on the structure of the ID and OOD datasets in question. Finally, we show that a method outperforming another on a certain (ID, OOD) pair may not do so in a low-data regime. In the low-data regime, we propose a distance-based method, Pairwise OOD detection (POD), which is based on Siamese networks and improves over Mahalanobis by sidestepping the expensive covariance estimation step. Our results suggest that the OOD detection problem may be too broad, and we should consider more specific structures for leverage.