 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Trade-Offs in Decentralized Multi-Antenna Architectures: Sparse Combining Modules for WAX Decomposition
Sep 08, 2023
With the increase in the number of antennas at base stations (BSs), centralized multi-antenna architectures have encountered scalability problems from excessive interconnection bandwidth to the central processing unit (CPU), as well as increased processing complexity. Thus, research efforts have been directed towards finding decentralized receiver architectures where a part of the processing is performed at the antenna end (or close to it). A recent paper put forth an information-lossless trade-off between level of decentralization (inputs to CPU) and decentralized processing complexity (multiplications per antenna). This trade-off was obtained by studying a newly defined matrix decomposition--the WAX decomposition--which is directly related to the information-lossless processing that should to be applied in a general framework to exploit the trade-off. {The general framework consists of three stages: a set of decentralized filters, a linear combining module, and a processing matrix applied at the CPU; these three stages are linear transformations which can be identified with the three constituent matrices of the WAX decomposition. The previous work was unable to provide explicit constructions for linear combining modules which are valid for WAX decomposition, while it remarked the importance of these modules being sparse with 1s and 0s so they could be efficiently implemented using hardware accelerators.} In this work we present a number of constructions, as well as possible variations of them, for effectively defining linear combining modules which can be used in the WAX decomposition. Furthermore, we show how these structures facilitate decentralized calculation of the WAX decomposition for applying information-lossless processing in architectures with an arbitrary level of decentralization.
* 16 pages, 6 figures, accepted for publication at IEEE Transactions on Signal Processing
Few-Shot Personalized Saliency Prediction Using Tensor Regression for Preserving Structural Global Information
Jul 06, 2023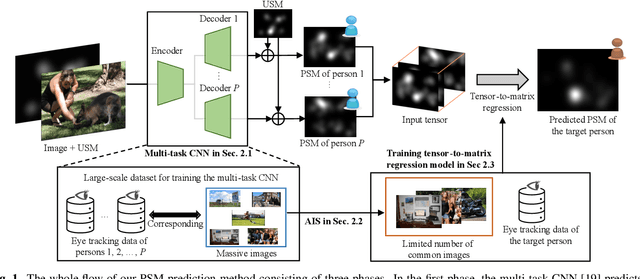
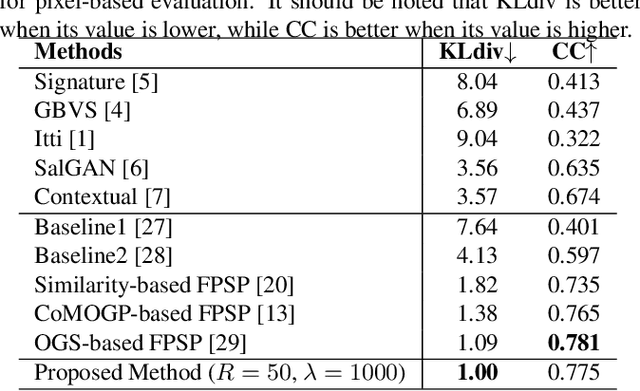
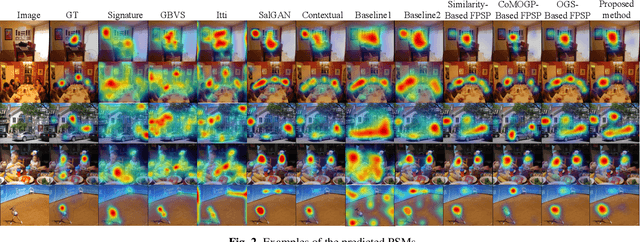
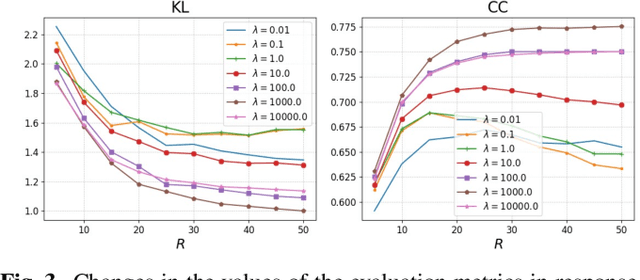
This paper presents a few-shot personalized saliency prediction using tensor-to-matrix regression for preserving the structural global information of personalized saliency maps (PSMs). In contrast to a general saliency map, a PSM has been great potential since its map indicates the person-specific visual attention that is useful for obtaining individual visual preferences from heterogeneity of gazed areas. The PSM prediction is needed for acquiring the PSM for the unseen image, but its prediction is still a challenging task due to the complexity of individual gaze patterns. For recognizing individual gaze patterns from the limited amount of eye-tracking data, the previous methods adopt the similarity of gaze tendency between persons. However, in the previous methods, the PSMs are vectorized for the prediction model. In this way, the structural global information of the PSMs corresponding to the image is ignored. For automatically revealing the relationship between PSMs, we focus on the tensor-based regression model that can preserve the structural information of PSMs, and realize the improvement of the prediction accuracy. In the experimental results, we confirm the proposed method including the tensor-based regression outperforms the comparative methods.
SoccerNet 2023 Challenges Results
Sep 12, 2023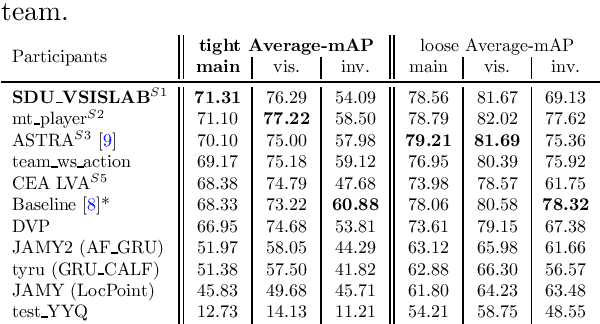
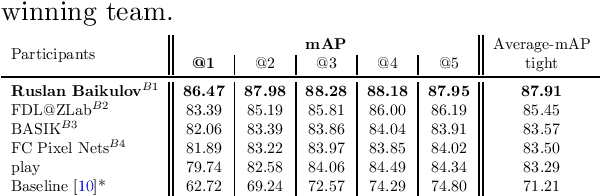
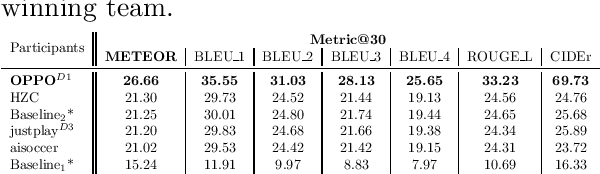
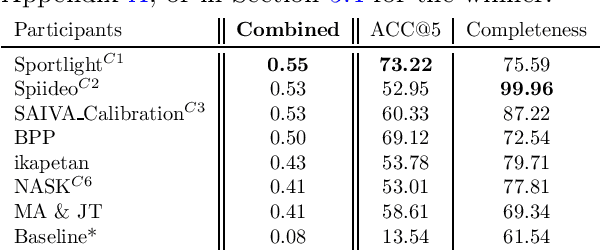
The SoccerNet 2023 challenges were the third annual video understanding challenges organized by the SoccerNet team. For this third edition, the challenges were composed of seven vision-based tasks split into three main themes. The first theme, broadcast video understanding, is composed of three high-level tasks related to describing events occurring in the video broadcasts: (1) action spotting, focusing on retrieving all timestamps related to global actions in soccer, (2) ball action spotting, focusing on retrieving all timestamps related to the soccer ball change of state, and (3) dense video captioning, focusing on describing the broadcast with natural language and anchored timestamps. The second theme, field understanding, relates to the single task of (4) camera calibration, focusing on retrieving the intrinsic and extrinsic camera parameters from images. The third and last theme, player understanding, is composed of three low-level tasks related to extracting information about the players: (5) re-identification, focusing on retrieving the same players across multiple views, (6) multiple object tracking, focusing on tracking players and the ball through unedited video streams, and (7) jersey number recognition, focusing on recognizing the jersey number of players from tracklets. Compared to the previous editions of the SoccerNet challenges, tasks (2-3-7) are novel, including new annotations and data, task (4) was enhanced with more data and annotations, and task (6) now focuses on end-to-end approaches. More information on the tasks, challenges, and leaderboards are available on https://www.soccer-net.org. Baselines and development kits can be found on https://github.com/SoccerNet.
Introducing Shape Prior Module in Diffusion Model for Medical Image Segmentation
Sep 12, 2023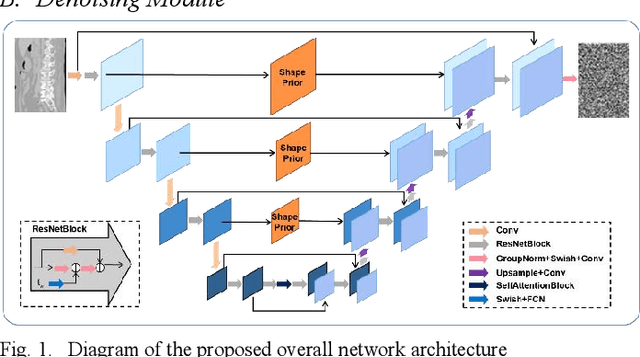
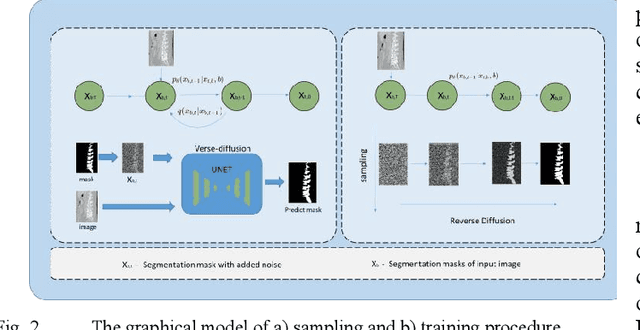

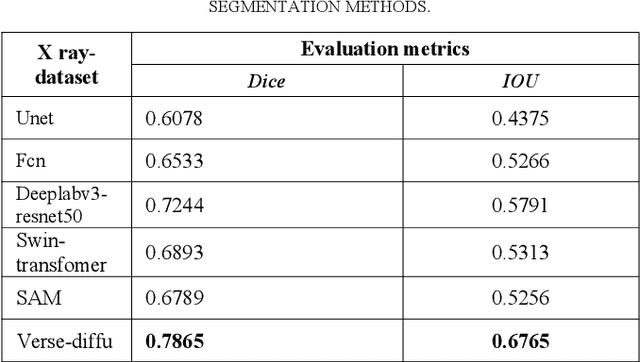
Medical image segmentation is critical for diagnosing and treating spinal disorders. However, the presence of high noise, ambiguity, and uncertainty makes this task highly challenging. Factors such as unclear anatomical boundaries, inter-class similarities, and irrational annotations contribute to this challenge. Achieving both accurate and diverse segmentation templates is essential to support radiologists in clinical practice. In recent years, denoising diffusion probabilistic modeling (DDPM) has emerged as a prominent research topic in computer vision. It has demonstrated effectiveness in various vision tasks, including image deblurring, super-resolution, anomaly detection, and even semantic representation generation at the pixel level. Despite the robustness of existing diffusion models in visual generation tasks, they still struggle with discrete masks and their various effects. To address the need for accurate and diverse spine medical image segmentation templates, we propose an end-to-end framework called VerseDiff-UNet, which leverages the denoising diffusion probabilistic model (DDPM). Our approach integrates the diffusion model into a standard U-shaped architecture. At each step, we combine the noise-added image with the labeled mask to guide the diffusion direction accurately towards the target region. Furthermore, to capture specific anatomical a priori information in medical images, we incorporate a shape a priori module. This module efficiently extracts structural semantic information from the input spine images. We evaluate our method on a single dataset of spine images acquired through X-ray imaging. Our results demonstrate that VerseDiff-UNet significantly outperforms other state-of-the-art methods in terms of accuracy while preserving the natural features and variations of anatomy.
Multi-dimensional Fusion and Consistency for Semi-supervised Medical Image Segmentation
Sep 12, 2023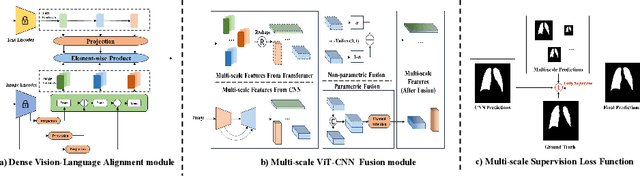
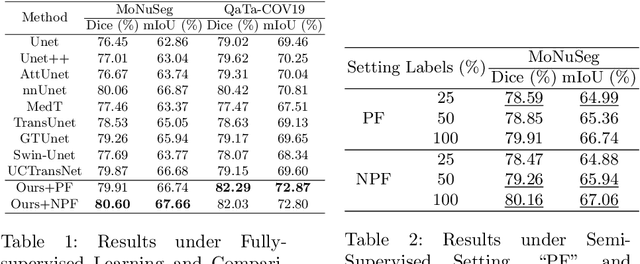
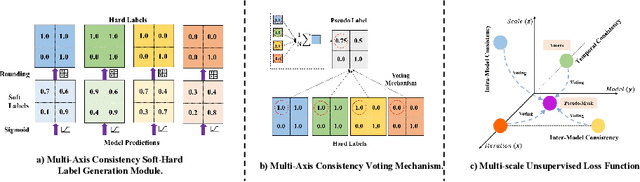
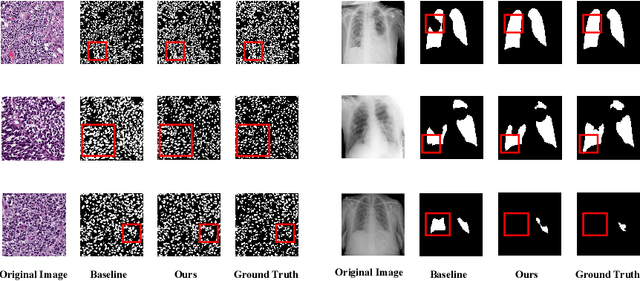
In this paper, we introduce a novel semi-supervised learning framework tailored for medical image segmentation. Central to our approach is the innovative Multi-scale Text-aware ViT-CNN Fusion scheme. This scheme adeptly combines the strengths of both ViTs and CNNs, capitalizing on the unique advantages of both architectures as well as the complementary information in vision-language modalities. Further enriching our framework, we propose the Multi-Axis Consistency framework for generating robust pseudo labels, thereby enhancing the semi-supervised learning process. Our extensive experiments on several widely-used datasets unequivocally demonstrate the efficacy of our approach.
Overview of GUA-SPA at IberLEF 2023: Guarani-Spanish Code Switching Analysis
Sep 12, 2023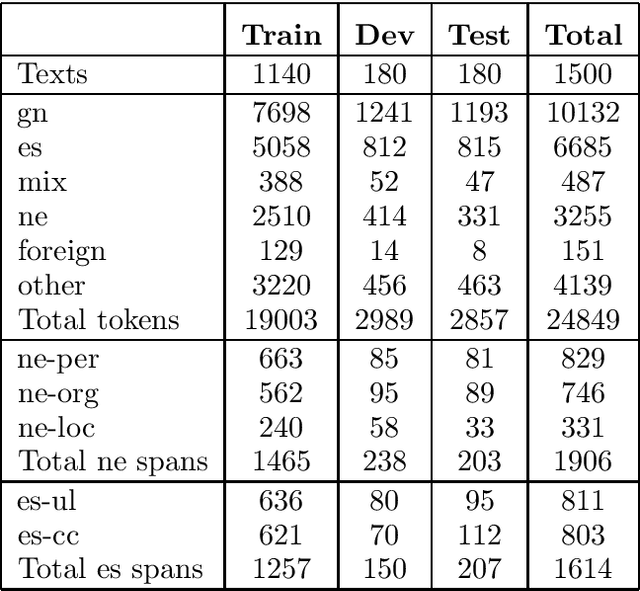
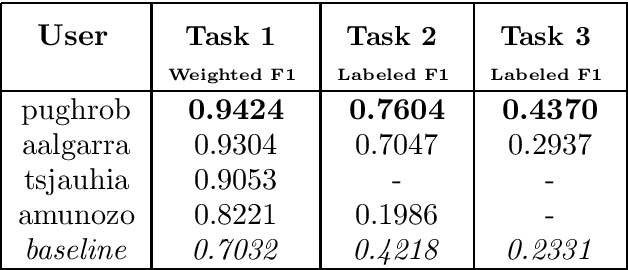
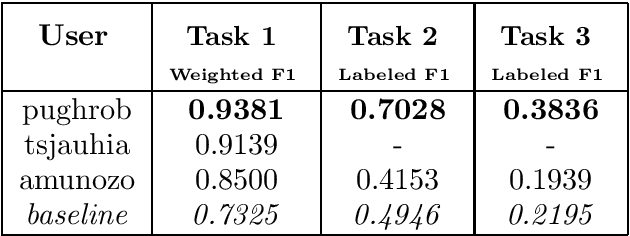
We present the first shared task for detecting and analyzing code-switching in Guarani and Spanish, GUA-SPA at IberLEF 2023. The challenge consisted of three tasks: identifying the language of a token, NER, and a novel task of classifying the way a Spanish span is used in the code-switched context. We annotated a corpus of 1500 texts extracted from news articles and tweets, around 25 thousand tokens, with the information for the tasks. Three teams took part in the evaluation phase, obtaining in general good results for Task 1, and more mixed results for Tasks 2 and 3.
Muti-Stage Hierarchical Food Classification
Sep 03, 2023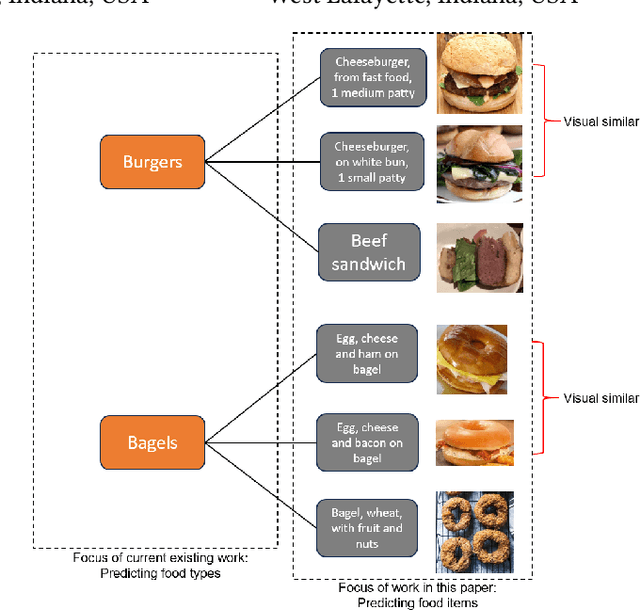
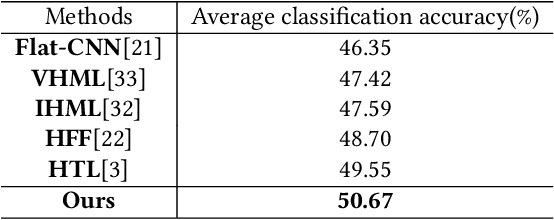
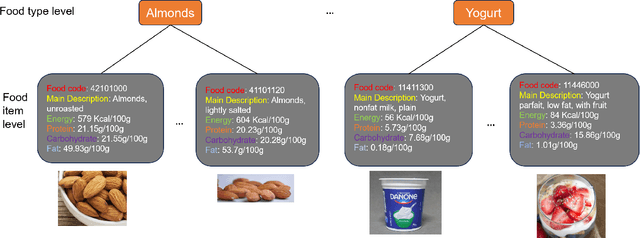
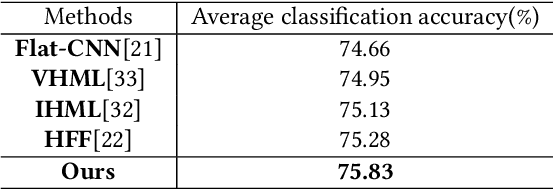
Food image classification serves as a fundamental and critical step in image-based dietary assessment, facilitating nutrient intake analysis from captured food images. However, existing works in food classification predominantly focuses on predicting 'food types', which do not contain direct nutritional composition information. This limitation arises from the inherent discrepancies in nutrition databases, which are tasked with associating each 'food item' with its respective information. Therefore, in this work we aim to classify food items to align with nutrition database. To this end, we first introduce VFN-nutrient dataset by annotating each food image in VFN with a food item that includes nutritional composition information. Such annotation of food items, being more discriminative than food types, creates a hierarchical structure within the dataset. However, since the food item annotations are solely based on nutritional composition information, they do not always show visual relations with each other, which poses significant challenges when applying deep learning-based techniques for classification. To address this issue, we then propose a multi-stage hierarchical framework for food item classification by iteratively clustering and merging food items during the training process, which allows the deep model to extract image features that are discriminative across labels. Our method is evaluated on VFN-nutrient dataset and achieve promising results compared with existing work in terms of both food type and food item classification.
Deep Learning Meets Swarm Intelligence for UAV-Assisted IoT Coverage in Massive MIMO
Sep 21, 2023This study considers a UAV-assisted multi-user massive multiple-input multiple-output (MU-mMIMO) systems, where a decode-and-forward (DF) relay in the form of an unmanned aerial vehicle (UAV) facilitates the transmission of multiple data streams from a base station (BS) to multiple Internet-of-Things (IoT) users. A joint optimization problem of hybrid beamforming (HBF), UAV relay positioning, and power allocation (PA) to multiple IoT users to maximize the total achievable rate (AR) is investigated. The study adopts a geometry-based millimeter-wave (mmWave) channel model for both links and proposes three different swarm intelligence (SI)-based algorithmic solutions to optimize: 1) UAV location with equal PA; 2) PA with fixed UAV location; and 3) joint PA with UAV deployment. The radio frequency (RF) stages are designed to reduce the number of RF chains based on the slow time-varying angular information, while the baseband (BB) stages are designed using the reduced-dimension effective channel matrices. Then, a novel deep learning (DL)-based low-complexity joint hybrid beamforming, UAV location and power allocation optimization scheme (J-HBF-DLLPA) is proposed via fully-connected deep neural network (DNN), consisting of an offline training phase, and an online prediction of UAV location and optimal power values for maximizing the AR. The illustrative results show that the proposed algorithmic solutions can attain higher capacity and reduce average delay for delay-constrained transmissions in a UAV-assisted MU-mMIMO IoT systems. Additionally, the proposed J-HBF-DLLPA can closely approach the optimal capacity while significantly reducing the runtime by 99%, which makes the DL-based solution a promising implementation for real-time online applications in UAV-assisted MU-mMIMO IoT systems.
Target-aware Bi-Transformer for Few-shot Segmentation
Sep 18, 2023Traditional semantic segmentation tasks require a large number of labels and are difficult to identify unlearned categories. Few-shot semantic segmentation (FSS) aims to use limited labeled support images to identify the segmentation of new classes of objects, which is very practical in the real world. Previous researches were primarily based on prototypes or correlations. Due to colors, textures, and styles are similar in the same image, we argue that the query image can be regarded as its own support image. In this paper, we proposed the Target-aware Bi-Transformer Network (TBTNet) to equivalent treat of support images and query image. A vigorous Target-aware Transformer Layer (TTL) also be designed to distill correlations and force the model to focus on foreground information. It treats the hypercorrelation as a feature, resulting a significant reduction in the number of feature channels. Benefit from this characteristic, our model is the lightest up to now with only 0.4M learnable parameters. Futhermore, TBTNet converges in only 10% to 25% of the training epochs compared to traditional methods. The excellent performance on standard FSS benchmarks of PASCAL-5i and COCO-20i proves the efficiency of our method. Extensive ablation studies were also carried out to evaluate the effectiveness of Bi-Transformer architecture and TTL.
Multi-user beamforming in RIS-aided communications and experimental validations
Sep 18, 2023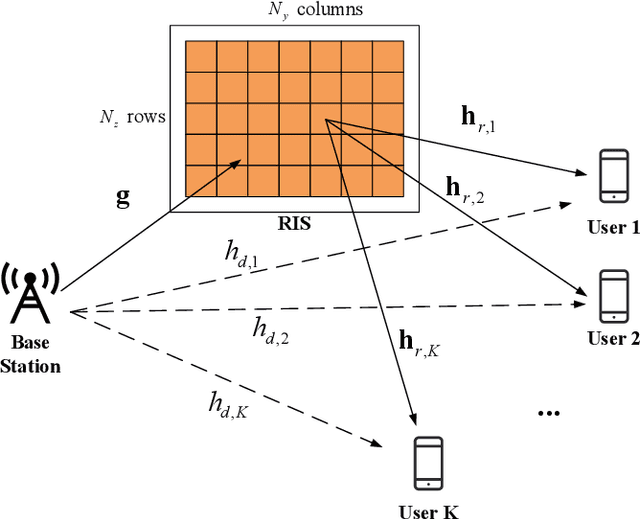
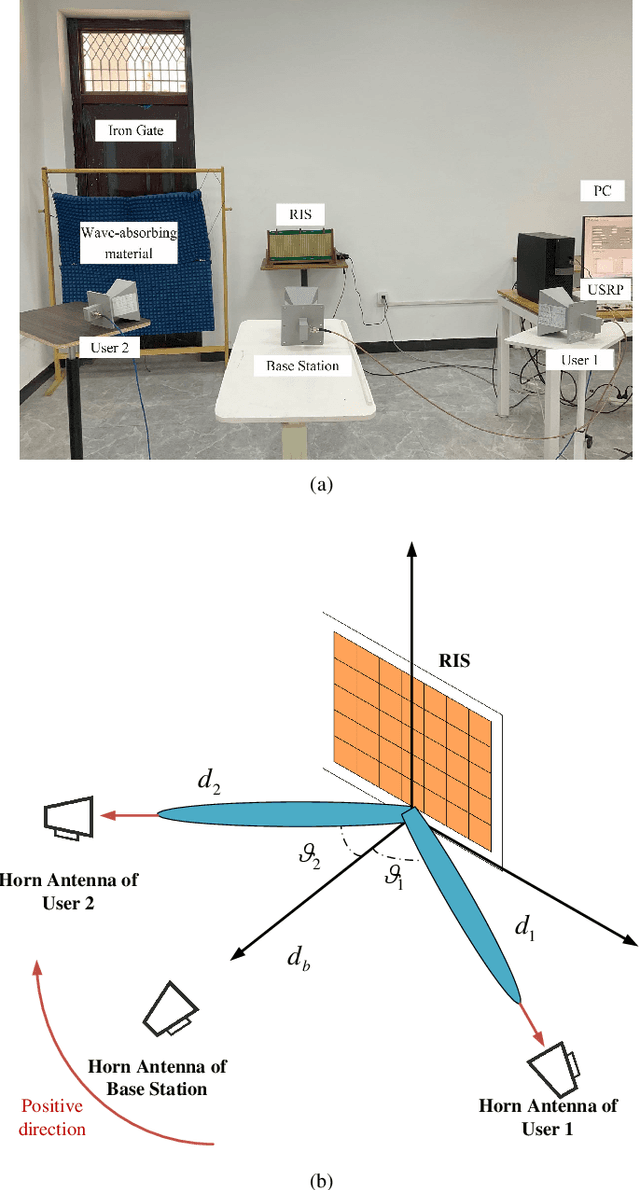
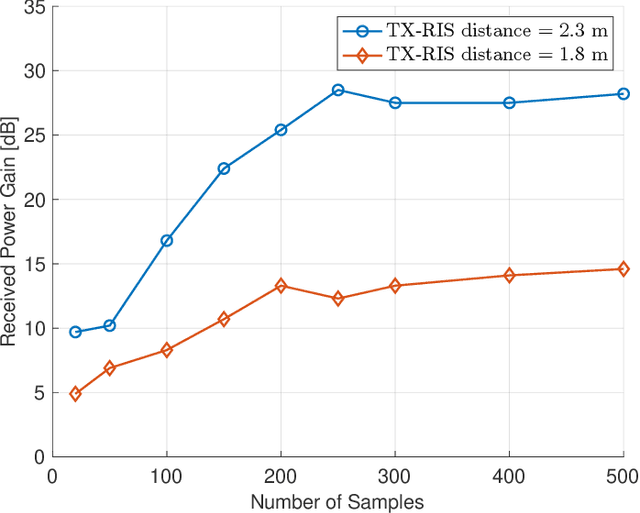
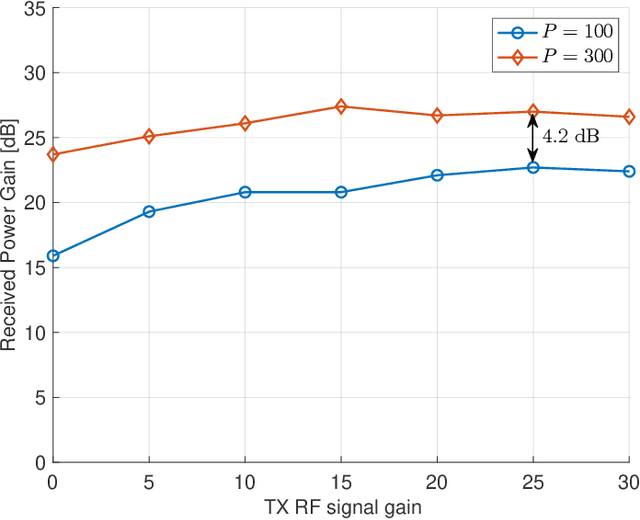
Reconfigurable intelligent surface (RIS) is a promising technology for future wireless communications due to its capability of optimizing the propagation environments. Nevertheless, in literature, there are few prototypes serving multiple users. In this paper, we propose a whole flow of channel estimation and beamforming design for RIS, and set up an RIS-aided multi-user system for experimental validations. Specifically, we combine a channel sparsification step with generalized approximate message passing (GAMP) algorithm, and propose to generate the measurement matrix as Rademacher distribution to obtain the channel state information (CSI). To generate the reflection coefficients with the aim of maximizing the spectral efficiency, we propose a quadratic transform-based low-rank multi-user beamforming (QTLM) algorithm. Our proposed algorithms exploit the sparsity and low-rank properties of the channel, which has the advantages of light calculation and fast convergence. Based on the universal software radio peripheral devices, we built a complete testbed working at 5.8GHz and implemented all the proposed algorithms to verify the possibility of RIS assisting multi-user systems. Experimental results show that the system has obtained an average spectral efficiency increase of 13.48bps/Hz, with respective received power gains of 26.6dB and 17.5dB for two users, compared with the case when RIS is powered-off.