 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLa Leaderboard: A Large Language Model Leaderboard for Spanish Varieties and Languages of Spain and Latin America
Jul 01, 2025Leaderboards showcase the current capabilities and limitations of Large Language Models (LLMs). To motivate the development of LLMs that represent the linguistic and cultural diversity of the Spanish-speaking community, we present La Leaderboard, the first open-source leaderboard to evaluate generative LLMs in languages and language varieties of Spain and Latin America. La Leaderboard is a community-driven project that aims to establish an evaluation standard for everyone interested in developing LLMs for the Spanish-speaking community. This initial version combines 66 datasets in Basque, Catalan, Galician, and different Spanish varieties, showcasing the evaluation results of 50 models. To encourage community-driven development of leaderboards in other languages, we explain our methodology, including guidance on selecting the most suitable evaluation setup for each downstream task. In particular, we provide a rationale for using fewer few-shot examples than typically found in the literature, aiming to reduce environmental impact and facilitate access to reproducible results for a broader research community.
RETUYT-INCO at BEA 2025 Shared Task: How Far Can Lightweight Models Go in AI-powered Tutor Evaluation?
Jun 12, 2025



In this paper, we present the RETUYT-INCO participation at the BEA 2025 shared task. Our participation was characterized by the decision of using relatively small models, with fewer than 1B parameters. This self-imposed restriction tries to represent the conditions in which many research labs or institutions are in the Global South, where computational power is not easily accessible due to its prohibitive cost. Even under this restrictive self-imposed setting, our models managed to stay competitive with the rest of teams that participated in the shared task. According to the $exact\ F_1$ scores published by the organizers, the performance gaps between our models and the winners were as follows: $6.46$ in Track 1; $10.24$ in Track 2; $7.85$ in Track 3; $9.56$ in Track 4; and $13.13$ in Track 5. Considering that the minimum difference with a winner team is $6.46$ points -- and the maximum difference is $13.13$ -- according to the $exact\ F_1$ score, we find that models with a size smaller than 1B parameters are competitive for these tasks, all of which can be run on computers with a low-budget GPU or even without a GPU.
A Platform for Generating Educational Activities to Teach English as a Second Language
Apr 28, 2025



We present a platform for the generation of educational activities oriented to teaching English as a foreign language. The different activities -- games and language practice exercises -- are strongly based on Natural Language Processing techniques. The platform offers the possibility of playing out-of-the-box games, generated from resources created semi-automatically and then manually curated. It can also generate games or exercises of greater complexity from texts entered by teachers, providing a stage of review and edition of the generated content before use. As a way of expanding the variety of activities in the platform, we are currently experimenting with image and text generation. In order to integrate them and improve the performance of other neural tools already integrated, we are working on migrating the platform to a more powerful server. In this paper we describe the development of our platform and its deployment for end users, discussing the challenges faced and how we overcame them, and also detail our future work plans.
PAYADOR: A Minimalist Approach to Grounding Language Models on Structured Data for Interactive Storytelling and Role-playing Games
Apr 09, 2025Every time an Interactive Storytelling (IS) system gets a player input, it is facing the world-update problem. Classical approaches to this problem consist in mapping that input to known preprogrammed actions, what can severely constrain the free will of the player. When the expected experience has a strong focus on improvisation, like in Role-playing Games (RPGs), this problem is critical. In this paper we present PAYADOR, a different approach that focuses on predicting the outcomes of the actions instead of representing the actions themselves. To implement this approach, we ground a Large Language Model to a minimal representation of the fictional world, obtaining promising results. We make this contribution open-source, so it can be adapted and used for other related research on unleashing the co-creativity power of RPGs.
* Presented at the 15th International Conference on Computational Creativity (ICCC'24)
Skill Check: Some Considerations on the Evaluation of Gamemastering Models for Role-playing Games
Sep 30, 2023



In role-playing games a Game Master (GM) is the player in charge of the game, who must design the challenges the players face and narrate the outcomes of their actions. In this work we discuss some challenges to model GMs from an Interactive Storytelling and Natural Language Processing perspective. Following those challenges we propose three test categories to evaluate such dialogue systems, and we use them to test ChatGPT, Bard and OpenAssistant as out-of-the-box GMs.
Overview of GUA-SPA at IberLEF 2023: Guarani-Spanish Code Switching Analysis
Sep 12, 2023


We present the first shared task for detecting and analyzing code-switching in Guarani and Spanish, GUA-SPA at IberLEF 2023. The challenge consisted of three tasks: identifying the language of a token, NER, and a novel task of classifying the way a Spanish span is used in the code-switched context. We annotated a corpus of 1500 texts extracted from news articles and tweets, around 25 thousand tokens, with the information for the tasks. Three teams took part in the evaluation phase, obtaining in general good results for Task 1, and more mixed results for Tasks 2 and 3.
Meeting the Needs of Low-Resource Languages: The Value of Automatic Alignments via Pretrained Models
Feb 15, 2023Large multilingual models have inspired a new class of word alignment methods, which work well for the model's pretraining languages. However, the languages most in need of automatic alignment are low-resource and, thus, not typically included in the pretraining data. In this work, we ask: How do modern aligners perform on unseen languages, and are they better than traditional methods? We contribute gold-standard alignments for Bribri--Spanish, Guarani--Spanish, Quechua--Spanish, and Shipibo-Konibo--Spanish. With these, we evaluate state-of-the-art aligners with and without model adaptation to the target language. Finally, we also evaluate the resulting alignments extrinsically through two downstream tasks: named entity recognition and part-of-speech tagging. We find that although transformer-based methods generally outperform traditional models, the two classes of approach remain competitive with each other.
Don't Take it Personally: Analyzing Gender and Age Differences in Ratings of Online Humor
Aug 23, 2022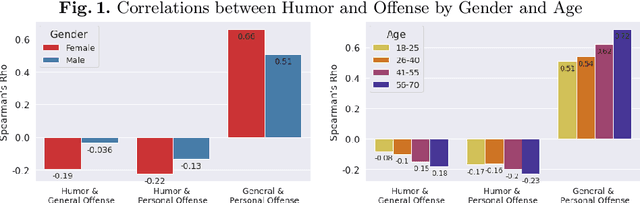

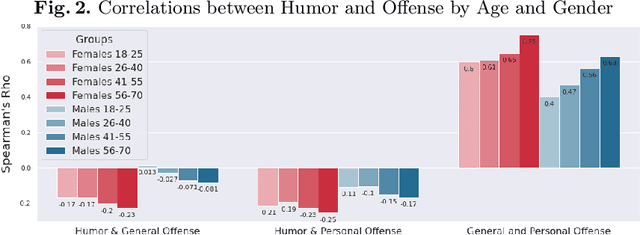

Computational humor detection systems rarely model the subjectivity of humor responses, or consider alternative reactions to humor - namely offense. We analyzed a large dataset of humor and offense ratings by male and female annotators of different age groups. We find that women link these two concepts more strongly than men, and they tend to give lower humor ratings and higher offense scores. We also find that the correlation between humor and offense increases with age. Although there were no gender or age differences in humor detection, women and older annotators signalled that they did not understand joke texts more often than men. We discuss implications for computational humor detection and downstream tasks.
AmericasNLI: Evaluating Zero-shot Natural Language Understanding of Pretrained Multilingual Models in Truly Low-resource Languages
Apr 18, 2021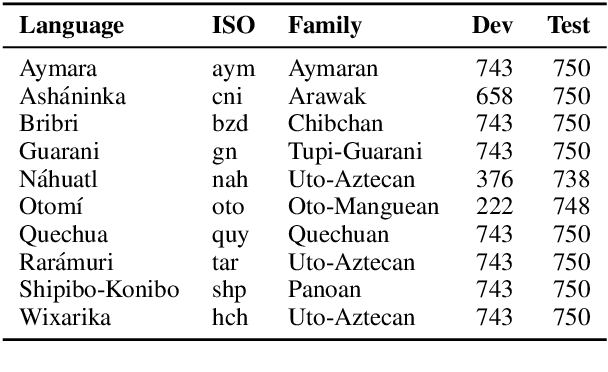
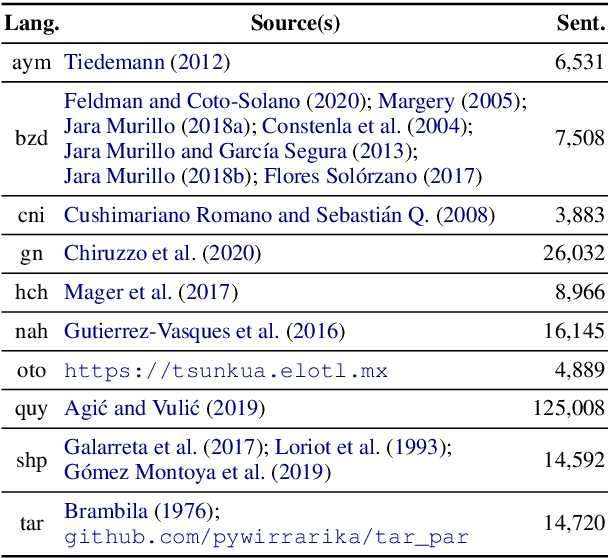
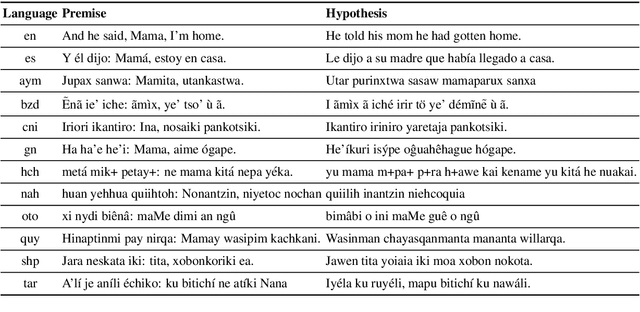

Pretrained multilingual models are able to perform cross-lingual transfer in a zero-shot setting, even for languages unseen during pretraining. However, prior work evaluating performance on unseen languages has largely been limited to low-level, syntactic tasks, and it remains unclear if zero-shot learning of high-level, semantic tasks is possible for unseen languages. To explore this question, we present AmericasNLI, an extension of XNLI (Conneau et al., 2018) to 10 indigenous languages of the Americas. We conduct experiments with XLM-R, testing multiple zero-shot and translation-based approaches. Additionally, we explore model adaptation via continued pretraining and provide an analysis of the dataset by considering hypothesis-only models. We find that XLM-R's zero-shot performance is poor for all 10 languages, with an average performance of 38.62%. Continued pretraining offers improvements, with an average accuracy of 44.05%. Surprisingly, training on poorly translated data by far outperforms all other methods with an accuracy of 48.72%.
A Crowd-Annotated Spanish Corpus for Humor Analysis
Jul 19, 2018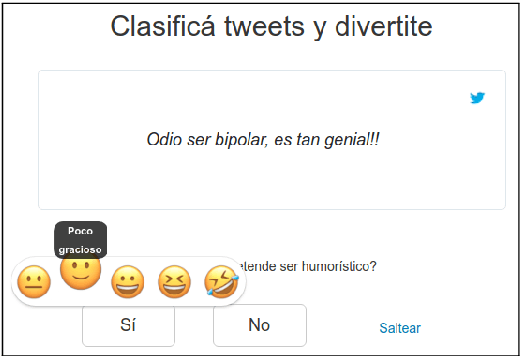
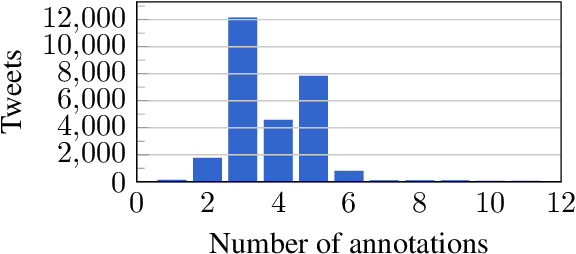
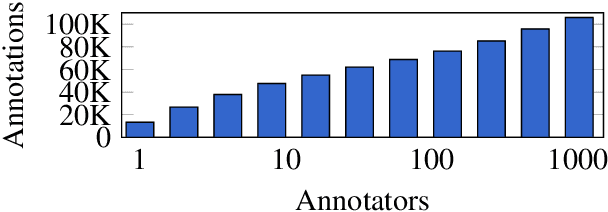
Computational Humor involves several tasks, such as humor recognition, humor generation, and humor scoring, for which it is useful to have human-curated data. In this work we present a corpus of 27,000 tweets written in Spanish and crowd-annotated by their humor value and funniness score, with about four annotations per tweet, tagged by 1,300 people over the Internet. It is equally divided between tweets coming from humorous and non-humorous accounts. The inter-annotator agreement Krippendorff's alpha value is 0.5710. The dataset is available for general use and can serve as a basis for humor detection and as a first step to tackle subjectivity.