 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoccerNet 2025 Challenges Results
Aug 26, 2025The SoccerNet 2025 Challenges mark the fifth annual edition of the SoccerNet open benchmarking effort, dedicated to advancing computer vision research in football video understanding. This year's challenges span four vision-based tasks: (1) Team Ball Action Spotting, focused on detecting ball-related actions in football broadcasts and assigning actions to teams; (2) Monocular Depth Estimation, targeting the recovery of scene geometry from single-camera broadcast clips through relative depth estimation for each pixel; (3) Multi-View Foul Recognition, requiring the analysis of multiple synchronized camera views to classify fouls and their severity; and (4) Game State Reconstruction, aimed at localizing and identifying all players from a broadcast video to reconstruct the game state on a 2D top-view of the field. Across all tasks, participants were provided with large-scale annotated datasets, unified evaluation protocols, and strong baselines as starting points. This report presents the results of each challenge, highlights the top-performing solutions, and provides insights into the progress made by the community. The SoccerNet Challenges continue to serve as a driving force for reproducible, open research at the intersection of computer vision, artificial intelligence, and sports. Detailed information about the tasks, challenges, and leaderboards can be found at https://www.soccer-net.org, with baselines and development kits available at https://github.com/SoccerNet.
SoccerNet 2024 Challenges Results
Sep 16, 2024



The SoccerNet 2024 challenges represent the fourth annual video understanding challenges organized by the SoccerNet team. These challenges aim to advance research across multiple themes in football, including broadcast video understanding, field understanding, and player understanding. This year, the challenges encompass four vision-based tasks. (1) Ball Action Spotting, focusing on precisely localizing when and which soccer actions related to the ball occur, (2) Dense Video Captioning, focusing on describing the broadcast with natural language and anchored timestamps, (3) Multi-View Foul Recognition, a novel task focusing on analyzing multiple viewpoints of a potential foul incident to classify whether a foul occurred and assess its severity, (4) Game State Reconstruction, another novel task focusing on reconstructing the game state from broadcast videos onto a 2D top-view map of the field. Detailed information about the tasks, challenges, and leaderboards can be found at https://www.soccer-net.org, with baselines and development kits available at https://github.com/SoccerNet.
Basketball-SORT: An Association Method for Complex Multi-object Occlusion Problems in Basketball Multi-object Tracking
Jun 28, 2024Recent deep learning-based object detection approaches have led to significant progress in multi-object tracking (MOT) algorithms. The current MOT methods mainly focus on pedestrian or vehicle scenes, but basketball sports scenes are usually accompanied by three or more object occlusion problems with similar appearances and high-intensity complex motions, which we call complex multi-object occlusion (CMOO). Here, we propose an online and robust MOT approach, named Basketball-SORT, which focuses on the CMOO problems in basketball videos. To overcome the CMOO problem, instead of using the intersection-over-union-based (IoU-based) approach, we use the trajectories of neighboring frames based on the projected positions of the players. Our method designs the basketball game restriction (BGR) and reacquiring Long-Lost IDs (RLLI) based on the characteristics of basketball scenes, and we also solve the occlusion problem based on the player trajectories and appearance features. Experimental results show that our method achieves a Higher Order Tracking Accuracy (HOTA) score of 63.48$\%$ on the basketball fixed video dataset and outperforms other recent popular approaches. Overall, our approach solved the CMOO problem more effectively than recent MOT algorithms.
TeamTrack: A Dataset for Multi-Sport Multi-Object Tracking in Full-pitch Videos
Apr 22, 2024



Multi-object tracking (MOT) is a critical and challenging task in computer vision, particularly in situations involving objects with similar appearances but diverse movements, as seen in team sports. Current methods, largely reliant on object detection and appearance, often fail to track targets in such complex scenarios accurately. This limitation is further exacerbated by the lack of comprehensive and diverse datasets covering the full view of sports pitches. Addressing these issues, we introduce TeamTrack, a pioneering benchmark dataset specifically designed for MOT in sports. TeamTrack is an extensive collection of full-pitch video data from various sports, including soccer, basketball, and handball. Furthermore, we perform a comprehensive analysis and benchmarking effort to underscore TeamTrack's utility and potential impact. Our work signifies a crucial step forward, promising to elevate the precision and effectiveness of MOT in complex, dynamic settings such as team sports. The dataset, project code and competition is released at: https://atomscott.github.io/TeamTrack/.
SoccerNet 2023 Challenges Results
Sep 12, 2023



The SoccerNet 2023 challenges were the third annual video understanding challenges organized by the SoccerNet team. For this third edition, the challenges were composed of seven vision-based tasks split into three main themes. The first theme, broadcast video understanding, is composed of three high-level tasks related to describing events occurring in the video broadcasts: (1) action spotting, focusing on retrieving all timestamps related to global actions in soccer, (2) ball action spotting, focusing on retrieving all timestamps related to the soccer ball change of state, and (3) dense video captioning, focusing on describing the broadcast with natural language and anchored timestamps. The second theme, field understanding, relates to the single task of (4) camera calibration, focusing on retrieving the intrinsic and extrinsic camera parameters from images. The third and last theme, player understanding, is composed of three low-level tasks related to extracting information about the players: (5) re-identification, focusing on retrieving the same players across multiple views, (6) multiple object tracking, focusing on tracking players and the ball through unedited video streams, and (7) jersey number recognition, focusing on recognizing the jersey number of players from tracklets. Compared to the previous editions of the SoccerNet challenges, tasks (2-3-7) are novel, including new annotations and data, task (4) was enhanced with more data and annotations, and task (6) now focuses on end-to-end approaches. More information on the tasks, challenges, and leaderboards are available on https://www.soccer-net.org. Baselines and development kits can be found on https://github.com/SoccerNet.
Adaptive action supervision in reinforcement learning from real-world multi-agent demonstrations
May 22, 2023



Modeling of real-world biological multi-agents is a fundamental problem in various scientific and engineering fields. Reinforcement learning (RL) is a powerful framework to generate flexible and diverse behaviors in cyberspace; however, when modeling real-world biological multi-agents, there is a domain gap between behaviors in the source (i.e., real-world data) and the target (i.e., cyberspace for RL), and the source environment parameters are usually unknown. In this paper, we propose a method for adaptive action supervision in RL from real-world demonstrations in multi-agent scenarios. We adopt an approach that combines RL and supervised learning by selecting actions of demonstrations in RL based on the minimum distance of dynamic time warping for utilizing the information of the unknown source dynamics. This approach can be easily applied to many existing neural network architectures and provide us with an RL model balanced between reproducibility as imitation and generalization ability to obtain rewards in cyberspace. In the experiments, using chase-and-escape and football tasks with the different dynamics between the unknown source and target environments, we show that our approach achieved a balance between the reproducibility and the generalization ability compared with the baselines. In particular, we used the tracking data of professional football players as expert demonstrations in football and show successful performances despite the larger gap between behaviors in the source and target environments than the chase-and-escape task.
How does AI play football? An analysis of RL and real-world football strategies
Nov 24, 2021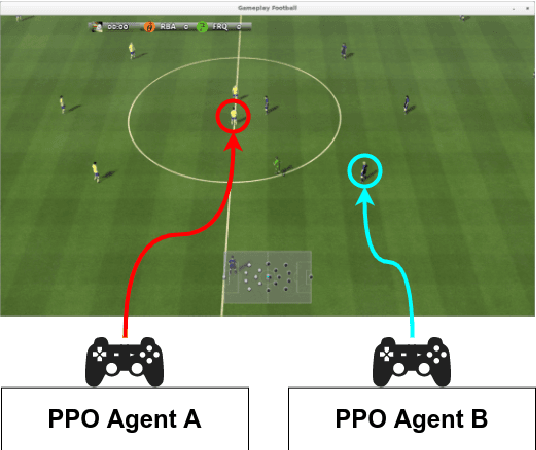

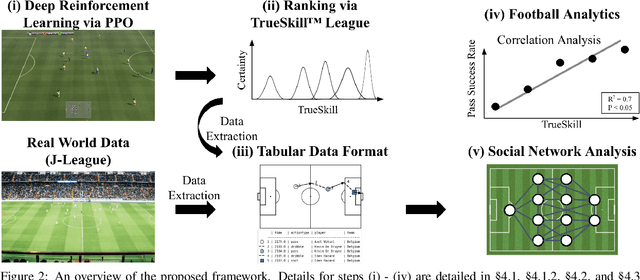
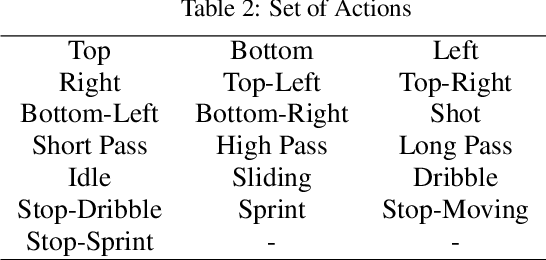
Recent advances in reinforcement learning (RL) have made it possible to develop sophisticated agents that excel in a wide range of applications. Simulations using such agents can provide valuable information in scenarios that are difficult to scientifically experiment in the real world. In this paper, we examine the play-style characteristics of football RL agents and uncover how strategies may develop during training. The learnt strategies are then compared with those of real football players. We explore what can be learnt from the use of simulated environments by using aggregated statistics and social network analysis (SNA). As a result, we found that (1) there are strong correlations between the competitiveness of an agent and various SNA metrics and (2) aspects of the RL agents play style become similar to real world footballers as the agent becomes more competitive. We discuss further advances that may be necessary to improve our understanding necessary to fully utilise RL for the analysis of football.