 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructure-aware Knowledge-guided Heterogeneous Mamba for Zygomaticomaxillary Suture Assessment
Jun 15, 2026The Zygomaticomaxillary Suture is a key circummaxillary structure that connects the zygomatic bone and the maxilla, which serves as a primary site of resistance during maxillary advancement, and its maturation status directly influences the timing and efficacy of orthopedic interventions. However, accurate staging of ZMS maturation remains challenging due to subtle high-frequency transitions in suture lines and the global semantic ambiguity between adjacent stages. To address this, we present the first public ZMS dataset, comprising 3,790 ZMS images covering the entire age range from 4 to 24 years. Based on this dataset, we propose SKMamba, a Structure-aware and Knowledge-guided Mamba-based multi-modal framework for automated ZMS maturation assessment. SKMamba adopts a decoupled dual-path architecture that mimics the hierarchical diagnostic process used by experienced orthodontists. We first introduce an Implicit Edge Extractor (IEE), which leverages structural pre-training to reduce trabecular noise and accentuate sutural boundaries. Complementarily, a Cross-Modal Semantic Alignment (CSA) module is designed to incorporate anatomical descriptions from a large language model (LLM). This module helps align local morphological cues with global semantic descriptions while ensuring that objective morphological evidence remains the primary basis for decisions. Extensive experiments on our ZMS dataset demonstrate that SKMamba achieves state-of-the-art performance compared to existing methods. Code is available at https://github.com/galaxygxq1116/SKMamba.
Adaptive Texture-aware Masking for Self-Supervised Learning in 3D Dental CBCT Analysis
May 03, 2026Cone Beam Computed Tomography (CBCT) is pivotal for 3D diagnostic imaging in dentistry. However, the development of robust AI models for volumetric analysis is often constrained by the scarcity of large, annotated datasets. Self-supervised learning (SSL), particularly Masked Image Modeling (MIM), offers a promising pathway to leverage unlabeled data. A limitation of standard MIM is its reliance on random masking, which fails to prioritize diagnostically critical regions in dental CBCT volumes, such as subtle pathological changes and intricate anatomical boundaries. To address this, we propose ATMask, a novel adaptive masking strategy. Instead of applying random masks or employing computationally intensive attention modules, ATMask computes an inter-slice texture variation map to identify regions with high structural or textural complexity. These high-variation areas are then selectively masked during pre-training, compelling the model to learn richer contextual representations essential for inferring complex 3D morphological transitions. Furthermore, we contribute the first large-scale CBCT dataset, curated from both public and private sources, comprising 6,314 scans, for the dental AI model pretraining. Extensive experiments on three downstream dental CBCT tasks demonstrate that our ATMask enables more data-efficient and powerful representation learning than standard random masking and other advanced SSL baselines. The dataset and code will be released.
Caries DETR: Tooth Structure-aware Prior and Lesion-aware Dynamic Loss Refinement for DETR Based Caries Detection
Apr 26, 2026As dental caries appear as subtle, low-contrast lesions in intraoral imaging, existing deep learning models face significant challenges in the early detection of caries. While recent Transformer-based detectors have shown promising results in natural images, they often fail to capture the domain-specific anatomical priors crucial for dental caries detection. In this paper, we propose Caries-DETR, a specialized Transformer framework for caries detection in intraoral images. A Tooth Structure-aware Query Initialization (TSQI) is designed, leveraging large-scale intraoral photograph pre-training and a structure perception branch (SPB) to integrate high-frequency structural priors, guiding the model to focus on anatomically significant lesion areas. Furthermore, we design a Lesion-aware Dynamic Loss Refinement (LDLR) to implement quality-driven hard mining through adaptive loss reweighting based on lesion size, anatomical relevance, and prediction quality, optimizing detection for subtle lesions. Extensive experiments on two public datasets (i.e., AlphaDent and DentalAI) demonstrate that Caries-DETR achieves a state-of-the-art performance compared to existing methods and exhibits good generalization and robustness. Code and data at https://github.com/XuefenLiu-SZU/Caries-DETR}{https://github.com/XuefenLiu-SZU/Caries-DETR.
Text-Conditioned Multi-Expert Regression Framework for Fully Automated Multi-Abutment Design
Apr 10, 2026Dental implant abutments serve as the geometric and biomechanical interface between the implant fixture and the prosthetic crown, yet their design relies heavily on manual effort and is time-consuming. Although deep neural networks have been proposed to assist dentists in designing abutments, most existing approaches remain largely manual or semi-automated, requiring substantial clinician intervention and lacking scalability in multi-abutment scenarios. To address these limitations, we propose TEMAD, a fully automated, text-conditioned multi-expert architecture for multi-abutment design. This framework integrates implant site localization and implant system, compatible abutment parameter regression into a unified pipeline. Specifically, we introduce an Implant Site Identification Network (ISIN) to automatically localize implant sites and provide this information to the subsequent multi-abutment regression network. We further design a Tooth-Conditioned Feature-wise Linear Modulation (TC-FiLM) module, which adaptively calibrates mesh representations using tooth embeddings to enable position-specific feature modulation. Additionally, a System-Prompted Mixture-of-Experts (SPMoE) mechanism leverages implant system prompts to guide expert selection, ensuring system-aware regression. Extensive experiments on a large-scale abutment design dataset show that TEMAD achieves state-of-the-art performance compared to existing methods, particularly in multi-abutment settings, validating its effectiveness for fully automated dental implant planning.
DinoDental: Benchmarking DINOv3 as a Unified Vision Encoder for Dental Image Analysis
Mar 30, 2026The scarcity and high cost of expert annotations in dental imaging present a significant challenge for the development of AI in dentistry. DINOv3, a state-of-the-art, self-supervised vision foundation model pre-trained on 1.7 billion images, offers a promising pathway to mitigate this issue. However, its reliability when transferred to the dental domain, with its unique imaging characteristics and clinical subtleties, remains unclear. To address this, we introduce DinoDental, a unified benchmark designed to systematically evaluate whether DINOv3 can serve as a reliable, off-the-shelf encoder for comprehensive dental image analysis without requiring domain-specific pre-training. Constructed from multiple public datasets, DinoDental covers a wide range of tasks, including classification, detection, and instance segmentation on both panoramic radiographs and intraoral photographs. We further analyze the model's transfer performance by scaling its size and input resolution, and by comparing different adaptation strategies, including frozen features, full fine-tuning, and the parameter-efficient Low-Rank Adaptation (LoRA) method. Our experiments show that DINOv3 can serve as a strong unified encoder for dental image analysis across both panoramic radiographs and intraoral photographs, remaining competitive across tasks while showing particularly clear advantages for intraoral image understanding and boundary-sensitive dense prediction. Collectively, DinoDental provides a systematic framework for comprehensively evaluating DINOv3 in dental analysis, establishing a foundational benchmark to guide efficient and effective model selection and adaptation for the dental AI community.
RegFreeNet: A Registration-Free Network for CBCT-based 3D Dental Implant Planning
Jan 21, 2026As the commercial surgical guide design software usually does not support the export of implant position for pre-implantation data, existing methods have to scan the post-implantation data and map the implant to pre-implantation space to get the label of implant position for training. Such a process is time-consuming and heavily relies on the accuracy of registration algorithm. Moreover, not all hospitals have paired CBCT data, limitting the construction of multi-center dataset. Inspired by the way dentists determine the implant position based on the neighboring tooth texture, we found that even if the implant area is masked, it will not affect the determination of the implant position. Therefore, we propose to mask the implants in the post-implantation data so that any CBCT containing the implants can be used as training data. This paradigm enables us to discard the registration process and makes it possible to construct a large-scale multi-center implant dataset. On this basis, we proposes ImplantFairy, a comprehensive, publicly accessible dental implant dataset with voxel-level 3D annotations of 1622 CBCT data. Furthermore, according to the area variation characteristics of the tooth's spatial structure and the slope information of the implant, we designed a slope-aware implant position prediction network. Specifically, a neighboring distance perception (NDP) module is designed to adaptively extract tooth area variation features, and an implant slope prediction branch assists the network in learning more robust features through additional implant supervision information. Extensive experiments conducted on ImplantFairy and two public dataset demonstrate that the proposed RegFreeNet achieves the state-of-the-art performance.
X-ray Insights Unleashed: Pioneering the Enhancement of Multi-Label Long-Tail Data
Dec 24, 2025Long-tailed pulmonary anomalies in chest radiography present formidable diagnostic challenges. Despite the recent strides in diffusion-based methods for enhancing the representation of tailed lesions, the paucity of rare lesion exemplars curtails the generative capabilities of these approaches, thereby leaving the diagnostic precision less than optimal. In this paper, we propose a novel data synthesis pipeline designed to augment tail lesions utilizing a copious supply of conventional normal X-rays. Specifically, a sufficient quantity of normal samples is amassed to train a diffusion model capable of generating normal X-ray images. This pre-trained diffusion model is subsequently utilized to inpaint the head lesions present in the diseased X-rays, thereby preserving the tail classes as augmented training data. Additionally, we propose the integration of a Large Language Model Knowledge Guidance (LKG) module alongside a Progressive Incremental Learning (PIL) strategy to stabilize the inpainting fine-tuning process. Comprehensive evaluations conducted on the public lung datasets MIMIC and CheXpert demonstrate that the proposed method sets a new benchmark in performance.
SSA3D: Text-Conditioned Assisted Self-Supervised Framework for Automatic Dental Abutment Design
Dec 12, 2025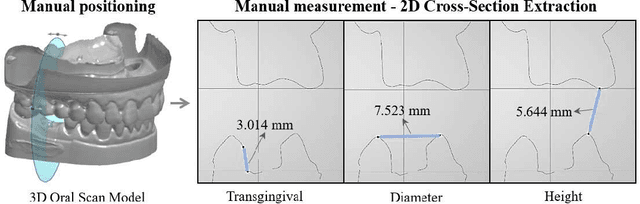
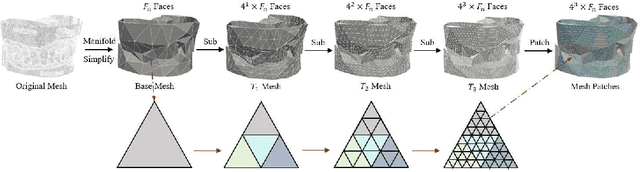
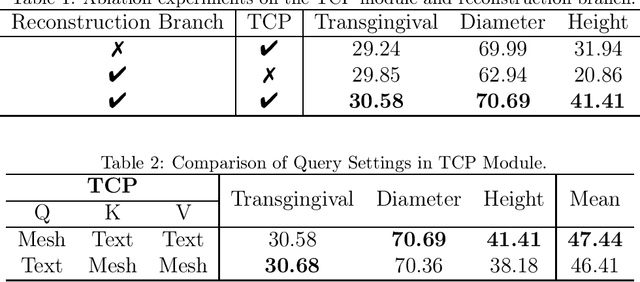
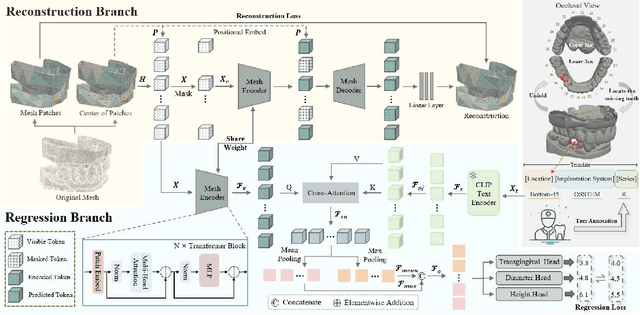
Abutment design is a critical step in dental implant restoration. However, manual design involves tedious measurement and fitting, and research on automating this process with AI is limited, due to the unavailability of large annotated datasets. Although self-supervised learning (SSL) can alleviate data scarcity, its need for pre-training and fine-tuning results in high computational costs and long training times. In this paper, we propose a Self-supervised assisted automatic abutment design framework (SS$A^3$D), which employs a dual-branch architecture with a reconstruction branch and a regression branch. The reconstruction branch learns to restore masked intraoral scan data and transfers the learned structural information to the regression branch. The regression branch then predicts the abutment parameters under supervised learning, which eliminates the separate pre-training and fine-tuning process. We also design a Text-Conditioned Prompt (TCP) module to incorporate clinical information (such as implant location, system, and series) into SS$A^3$D. This guides the network to focus on relevant regions and constrains the parameter predictions. Extensive experiments on a collected dataset show that SS$A^3$D saves half of the training time and achieves higher accuracy than traditional SSL methods. It also achieves state-of-the-art performance compared to other methods, significantly improving the accuracy and efficiency of automated abutment design.
Technical Report for Soccernet 2023 -- Dense Video Captioning
Oct 31, 2024


In the task of dense video captioning of Soccernet dataset, we propose to generate a video caption of each soccer action and locate the timestamp of the caption. Firstly, we apply Blip as our video caption framework to generate video captions. Then we locate the timestamp by using (1) multi-size sliding windows (2) temporal proposal generation and (3) proposal classification.
SSAD: Self-supervised Auxiliary Detection Framework for Panoramic X-ray based Dental Disease Diagnosis
Jun 20, 2024Panoramic X-ray is a simple and effective tool for diagnosing dental diseases in clinical practice. When deep learning models are developed to assist dentist in interpreting panoramic X-rays, most of their performance suffers from the limited annotated data, which requires dentist's expertise and a lot of time cost. Although self-supervised learning (SSL) has been proposed to address this challenge, the two-stage process of pretraining and fine-tuning requires even more training time and computational resources. In this paper, we present a self-supervised auxiliary detection (SSAD) framework, which is plug-and-play and compatible with any detectors. It consists of a reconstruction branch and a detection branch. Both branches are trained simultaneously, sharing the same encoder, without the need for finetuning. The reconstruction branch learns to restore the tooth texture of healthy or diseased teeth, while the detection branch utilizes these learned features for diagnosis. To enhance the encoder's ability to capture fine-grained features, we incorporate the image encoder of SAM to construct a texture consistency (TC) loss, which extracts image embedding from the input and output of reconstruction branch, and then enforces both embedding into the same feature space. Extensive experiments on the public DENTEX dataset through three detection tasks demonstrate that the proposed SSAD framework achieves state-of-the-art performance compared to mainstream object detection methods and SSL methods. The code is available at https://github.com/Dylonsword/SSAD