 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoccerNet 2023 Challenges Results
Sep 12, 2023



The SoccerNet 2023 challenges were the third annual video understanding challenges organized by the SoccerNet team. For this third edition, the challenges were composed of seven vision-based tasks split into three main themes. The first theme, broadcast video understanding, is composed of three high-level tasks related to describing events occurring in the video broadcasts: (1) action spotting, focusing on retrieving all timestamps related to global actions in soccer, (2) ball action spotting, focusing on retrieving all timestamps related to the soccer ball change of state, and (3) dense video captioning, focusing on describing the broadcast with natural language and anchored timestamps. The second theme, field understanding, relates to the single task of (4) camera calibration, focusing on retrieving the intrinsic and extrinsic camera parameters from images. The third and last theme, player understanding, is composed of three low-level tasks related to extracting information about the players: (5) re-identification, focusing on retrieving the same players across multiple views, (6) multiple object tracking, focusing on tracking players and the ball through unedited video streams, and (7) jersey number recognition, focusing on recognizing the jersey number of players from tracklets. Compared to the previous editions of the SoccerNet challenges, tasks (2-3-7) are novel, including new annotations and data, task (4) was enhanced with more data and annotations, and task (6) now focuses on end-to-end approaches. More information on the tasks, challenges, and leaderboards are available on https://www.soccer-net.org. Baselines and development kits can be found on https://github.com/SoccerNet.
COMEDIAN: Self-Supervised Learning and Knowledge Distillation for Action Spotting using Transformers
Sep 03, 2023



We present COMEDIAN, a novel pipeline to initialize spatio-temporal transformers for action spotting, which involves self-supervised learning and knowledge distillation. Action spotting is a timestamp-level temporal action detection task. Our pipeline consists of three steps, with two initialization stages. First, we perform self-supervised initialization of a spatial transformer using short videos as input. Additionally, we initialize a temporal transformer that enhances the spatial transformer's outputs with global context through knowledge distillation from a pre-computed feature bank aligned with each short video segment. In the final step, we fine-tune the transformers to the action spotting task. The experiments, conducted on the SoccerNet-v2 dataset, demonstrate state-of-the-art performance and validate the effectiveness of COMEDIAN's pretraining paradigm. Our results highlight several advantages of our pretraining pipeline, including improved performance and faster convergence compared to non-pretrained models.
VIBR: Learning View-Invariant Value Functions for Robust Visual Control
Jun 14, 2023



End-to-end reinforcement learning on images showed significant progress in the recent years. Data-based approach leverage data augmentation and domain randomization while representation learning methods use auxiliary losses to learn task-relevant features. Yet, reinforcement still struggles in visually diverse environments full of distractions and spurious noise. In this work, we tackle the problem of robust visual control at its core and present VIBR (View-Invariant Bellman Residuals), a method that combines multi-view training and invariant prediction to reduce out-of-distribution (OOD) generalization gap for RL based visuomotor control. Our model-free approach improve baselines performances without the need of additional representation learning objectives and with limited additional computational cost. We show that VIBR outperforms existing methods on complex visuo-motor control environment with high visual perturbation. Our approach achieves state-of the-art results on the Distracting Control Suite benchmark, a challenging benchmark still not solved by current methods, where we evaluate the robustness to a number of visual perturbators, as well as OOD generalization and extrapolation capabilities.
Similarity Contrastive Estimation for Image and Video Soft Contrastive Self-Supervised Learning
Dec 21, 2022Contrastive representation learning has proven to be an effective self-supervised learning method for images and videos. Most successful approaches are based on Noise Contrastive Estimation (NCE) and use different views of an instance as positives that should be contrasted with other instances, called negatives, that are considered as noise. However, several instances in a dataset are drawn from the same distribution and share underlying semantic information. A good data representation should contain relations between the instances, or semantic similarity and dissimilarity, that contrastive learning harms by considering all negatives as noise. To circumvent this issue, we propose a novel formulation of contrastive learning using semantic similarity between instances called Similarity Contrastive Estimation (SCE). Our training objective is a soft contrastive one that brings the positives closer and estimates a continuous distribution to push or pull negative instances based on their learned similarities. We validate empirically our approach on both image and video representation learning. We show that SCE performs competitively with the state of the art on the ImageNet linear evaluation protocol for fewer pretraining epochs and that it generalizes to several downstream image tasks. We also show that SCE reaches state-of-the-art results for pretraining video representation and that the learned representation can generalize to video downstream tasks.
Self-Supervised Pre-training of Vision Transformers for Dense Prediction Tasks
Jun 07, 2022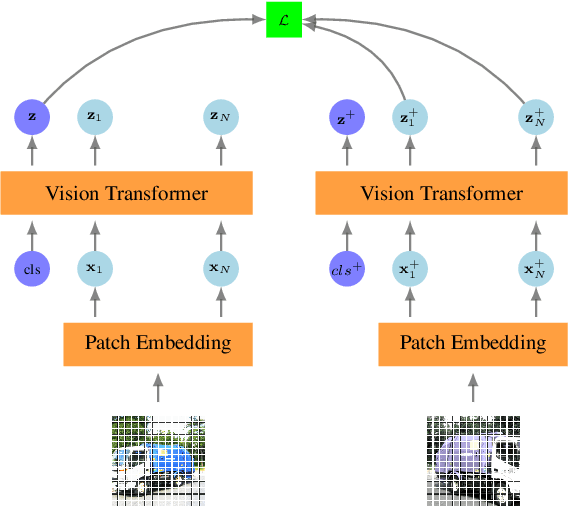
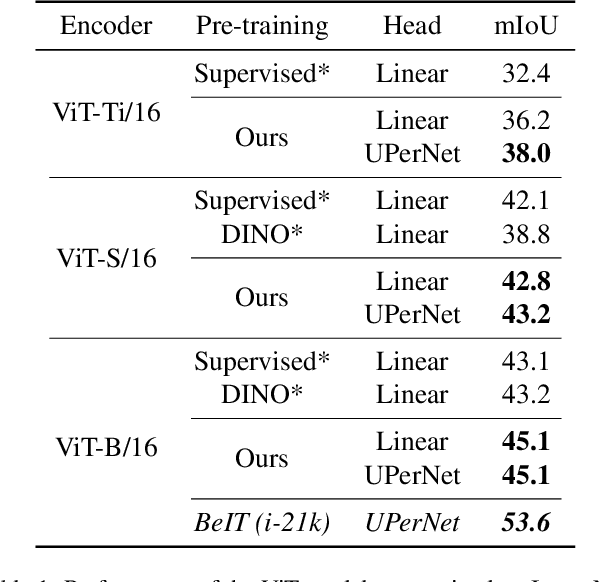
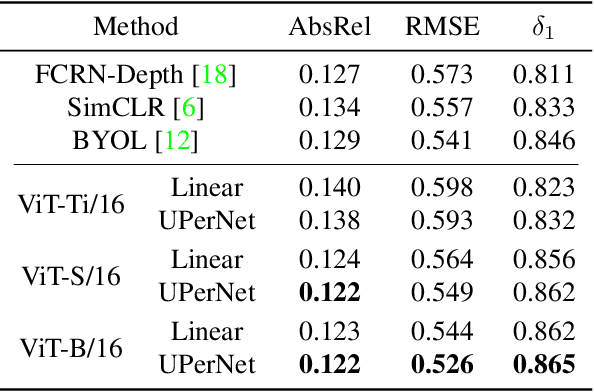
We present a new self-supervised pre-training of Vision Transformers for dense prediction tasks. It is based on a contrastive loss across views that compares pixel-level representations to global image representations. This strategy produces better local features suitable for dense prediction tasks as opposed to contrastive pre-training based on global image representation only. Furthermore, our approach does not suffer from a reduced batch size since the number of negative examples needed in the contrastive loss is in the order of the number of local features. We demonstrate the effectiveness of our pre-training strategy on two dense prediction tasks: semantic segmentation and monocular depth estimation.
End-to-end Person Search Sequentially Trained on Aggregated Dataset
Jan 24, 2022
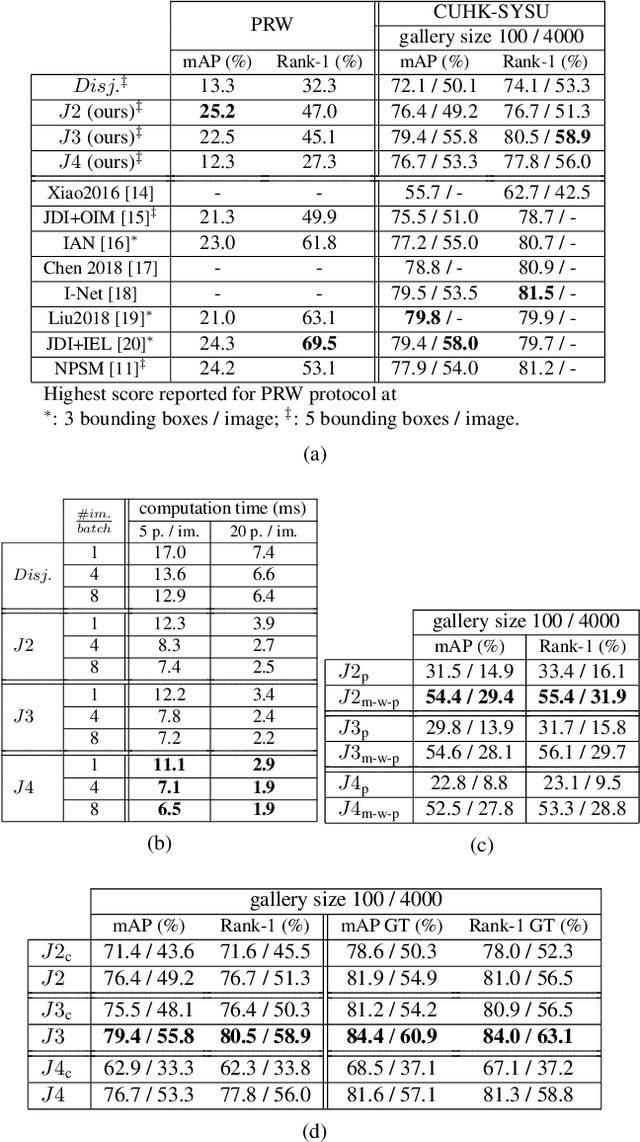
In video surveillance applications, person search is a challenging task consisting in detecting people and extracting features from their silhouette for re-identification (re-ID) purpose. We propose a new end-to-end model that jointly computes detection and feature extraction steps through a single deep Convolutional Neural Network architecture. Sharing feature maps between the two tasks for jointly describing people commonalities and specificities allows faster runtime, which is valuable in real-world applications. In addition to reaching state-of-the-art accuracy, this multi-task model can be sequentially trained task-by-task, which results in a broader acceptance of input dataset types. Indeed, we show that aggregating more pedestrian detection datasets without costly identity annotations makes the shared feature maps more generic, and improves re-ID precision. Moreover, these boosted shared feature maps result in re-ID features more robust to a cross-dataset scenario.
* 5 pages
Similarity Contrastive Estimation for Self-Supervised Soft Contrastive Learning
Nov 29, 2021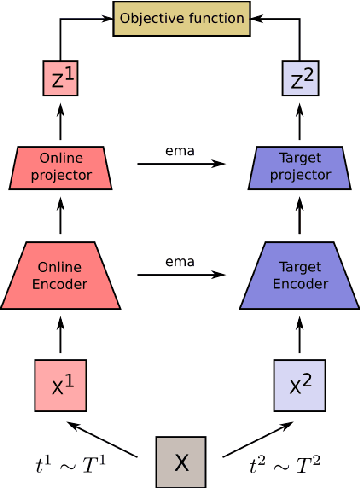

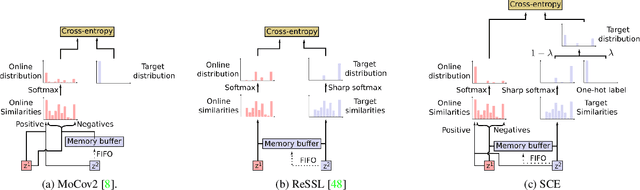
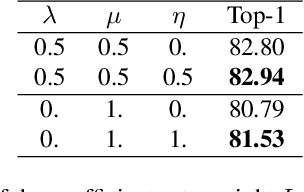
Contrastive representation learning has proven to be an effective self-supervised learning method. Most successful approaches are based on the Noise Contrastive Estimation (NCE) paradigm and consider different views of an instance as positives and other instances as noise that positives should be contrasted with. However, all instances in a dataset are drawn from the same distribution and share underlying semantic information that should not be considered as noise. We argue that a good data representation contains the relations, or semantic similarity, between the instances. Contrastive learning implicitly learns relations but considers the negatives as noise which is harmful to the quality of the learned relations and therefore the quality of the representation. To circumvent this issue we propose a novel formulation of contrastive learning using semantic similarity between instances called Similarity Contrastive Estimation (SCE). Our training objective can be considered as soft contrastive learning. Instead of hard classifying positives and negatives, we propose a continuous distribution to push or pull instances based on their semantic similarities. The target similarity distribution is computed from weak augmented instances and sharpened to eliminate irrelevant relations. Each weak augmented instance is paired with a strong augmented instance that contrasts its positive while maintaining the target similarity distribution. Experimental results show that our proposed SCE outperforms its baselines MoCov2 and ReSSL on various datasets and is competitive with state-of-the-art algorithms on the ImageNet linear evaluation protocol.
Evaluating Robustness over High Level Driving Instruction for Autonomous Driving
May 20, 2021
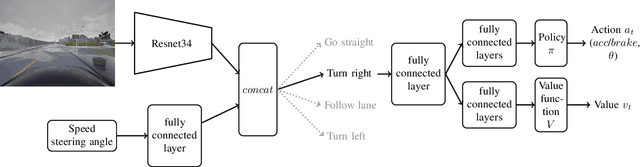
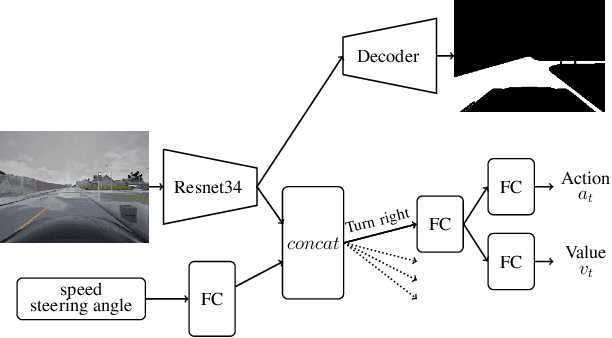
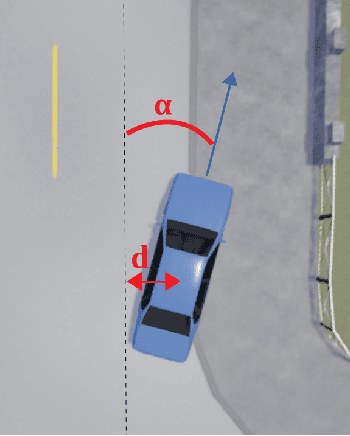
In recent years, we have witnessed increasingly high performance in the field of autonomous end-to-end driving. In particular, more and more research is being done on driving in urban environments, where the car has to follow high level commands to navigate. However, few evaluations are made on the ability of these agents to react in an unexpected situation. Specifically, no evaluations are conducted on the robustness of driving agents in the event of a bad high-level command. We propose here an evaluation method, namely a benchmark that allows to assess the robustness of an agent, and to appreciate its understanding of the environment through its ability to keep a safe behavior, regardless of the instruction.
Deep MANTA: A Coarse-to-fine Many-Task Network for joint 2D and 3D vehicle analysis from monocular image
Mar 22, 2017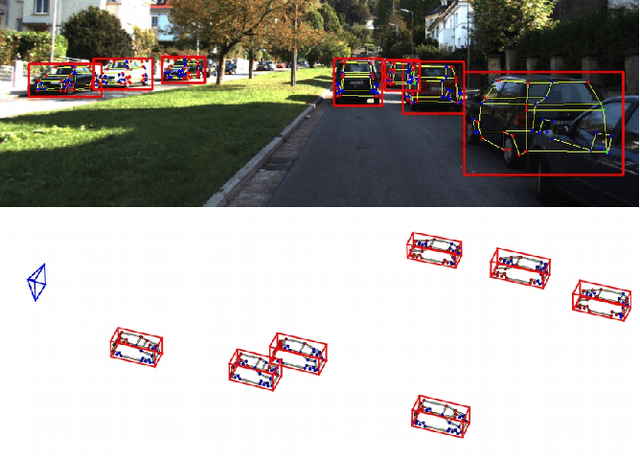
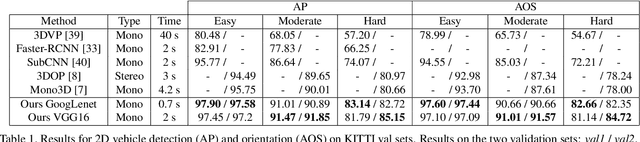
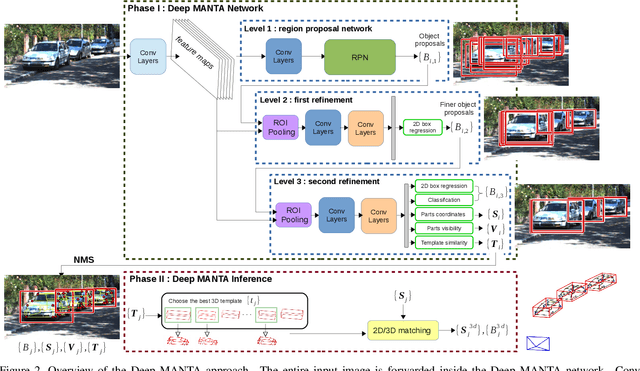
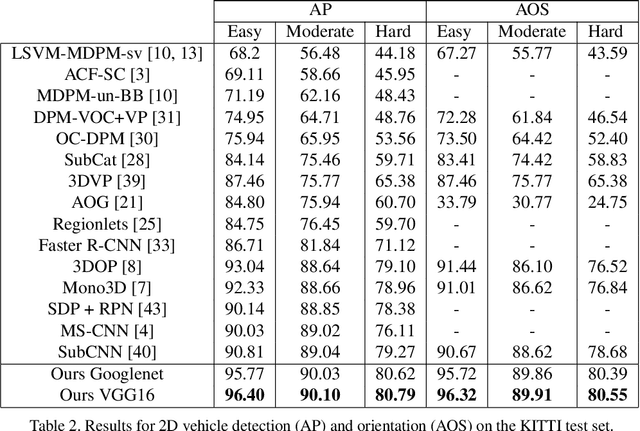
In this paper, we present a novel approach, called Deep MANTA (Deep Many-Tasks), for many-task vehicle analysis from a given image. A robust convolutional network is introduced for simultaneous vehicle detection, part localization, visibility characterization and 3D dimension estimation. Its architecture is based on a new coarse-to-fine object proposal that boosts the vehicle detection. Moreover, the Deep MANTA network is able to localize vehicle parts even if these parts are not visible. In the inference, the network's outputs are used by a real time robust pose estimation algorithm for fine orientation estimation and 3D vehicle localization. We show in experiments that our method outperforms monocular state-of-the-art approaches on vehicle detection, orientation and 3D location tasks on the very challenging KITTI benchmark.