 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniviewVLA: A Unified Multiview Vision-Language-Action Model with World Modeling
Jun 19, 2026Occluded tasks remain a bottleneck in robot manipulation. Existing solutions either deploy additional physical cameras requiring training-inference camera parity, or rely on explicit 3D reconstruction with high computational cost. Moreover, both approaches rely on standard agent-view and wrist-view observations, while failing to capture occlusion information and future scene evolution. To this end, we propose UniviewVLA, a unified multiview Vision-Language-Action model with world modeling, which infers multiview scene evolution for action prediction from only standard two-camera observations. We demonstrate that by leveraging generated multiview future views from the world model, UniviewVLA reveals occluded cues and models future scene evolution, improving action prediction and removing the need for extra hardware or explicit reconstruction. Besides, to accelerate inference while preserving prediction accuracy, UniviewVLA develops Motion-Informative Token Compression, which compresses each generated view from 625 to 16 tokens and reduces per-view latency from 6-7s to 0.2-0.3s. UniviewVLA also proposes training-free Action-Entropy View Selection, which dynamically identifies the most action-informative view at different inference stages. Extensive experiments show that UniviewVLA achieves 95.8% on LIBERO and 4.60 on CALVIN ABCD to D, both standard occlusion-free benchmarks. On customized occlusion-focused tasks, it improves success rate from 40.0% to 73.3%, and average real-robot success rate by 33.4 points, demonstrating stronger occlusion-focused performance without sacrificing standard occlusion-free benchmarks.
OneVL: One-Step Latent Reasoning and Planning with Vision-Language Explanation
Apr 20, 2026Chain-of-Thought (CoT) reasoning has become a powerful driver of trajectory prediction in VLA-based autonomous driving, yet its autoregressive nature imposes a latency cost that is prohibitive for real-time deployment. Latent CoT methods attempt to close this gap by compressing reasoning into continuous hidden states, but consistently fall short of their explicit counterparts. We suggest that this is due to purely linguistic latent representations compressing a symbolic abstraction of the world, rather than the causal dynamics that actually govern driving. Thus, we present OneVL (One-step latent reasoning and planning with Vision-Language explanations), a unified VLA and World Model framework that routes reasoning through compact latent tokens supervised by dual auxiliary decoders. Alongside a language decoder that reconstructs text CoT, we introduce a visual world model decoder that predicts future-frame tokens, forcing the latent space to internalize the causal dynamics of road geometry, agent motion, and environmental change. A three-stage training pipeline progressively aligns these latents with trajectory, language, and visual objectives, ensuring stable joint optimization. At inference, the auxiliary decoders are discarded and all latent tokens are prefilled in a single parallel pass, matching the speed of answer-only prediction. Across four benchmarks, OneVL becomes the first latent CoT method to surpass explicit CoT, delivering state-of-the-art accuracy at answer-only latency, and providing direct evidence that tighter compression, when guided in both language and world-model supervision, produces more generalizable representations than verbose token-by-token reasoning. Project Page: https://xiaomi-embodied-intelligence.github.io/OneVL
VGGDrive: Empowering Vision-Language Models with Cross-View Geometric Grounding for Autonomous Driving
Feb 24, 2026The significance of cross-view 3D geometric modeling capabilities for autonomous driving is self-evident, yet existing Vision-Language Models (VLMs) inherently lack this capability, resulting in their mediocre performance. While some promising approaches attempt to mitigate this by constructing Q&A data for auxiliary training, they still fail to fundamentally equip VLMs with the ability to comprehensively handle diverse evaluation protocols. We thus chart a new course, advocating for the infusion of VLMs with the cross-view geometric grounding of mature 3D foundation models, closing this critical capability gap in autonomous driving. In this spirit, we propose a novel architecture, VGGDrive, which empowers Vision-language models with cross-view Geometric Grounding for autonomous Driving. Concretely, to bridge the cross-view 3D geometric features from the frozen visual 3D model with the VLM's 2D visual features, we introduce a plug-and-play Cross-View 3D Geometric Enabler (CVGE). The CVGE decouples the base VLM architecture and effectively empowers the VLM with 3D features through a hierarchical adaptive injection mechanism. Extensive experiments show that VGGDrive enhances base VLM performance across five autonomous driving benchmarks, including tasks like cross-view risk perception, motion prediction, and trajectory planning. It's our belief that mature 3D foundation models can empower autonomous driving tasks through effective integration, and we hope our initial exploration demonstrates the potential of this paradigm to the autonomous driving community.
Is Your VLM for Autonomous Driving Safety-Ready? A Comprehensive Benchmark for Evaluating External and In-Cabin Risks
Nov 19, 2025Vision-Language Models (VLMs) show great promise for autonomous driving, but their suitability for safety-critical scenarios is largely unexplored, raising safety concerns. This issue arises from the lack of comprehensive benchmarks that assess both external environmental risks and in-cabin driving behavior safety simultaneously. To bridge this critical gap, we introduce DSBench, the first comprehensive Driving Safety Benchmark designed to assess a VLM's awareness of various safety risks in a unified manner. DSBench encompasses two major categories: external environmental risks and in-cabin driving behavior safety, divided into 10 key categories and a total of 28 sub-categories. This comprehensive evaluation covers a wide range of scenarios, ensuring a thorough assessment of VLMs' performance in safety-critical contexts. Extensive evaluations across various mainstream open-source and closed-source VLMs reveal significant performance degradation under complex safety-critical situations, highlighting urgent safety concerns. To address this, we constructed a large dataset of 98K instances focused on in-cabin and external safety scenarios, showing that fine-tuning on this dataset significantly enhances the safety performance of existing VLMs and paves the way for advancing autonomous driving technology. The benchmark toolkit, code, and model checkpoints will be publicly accessible.
Hierarchical Structure-Property Alignment for Data-Efficient Molecular Generation and Editing
Nov 11, 2025Property-constrained molecular generation and editing are crucial in AI-driven drug discovery but remain hindered by two factors: (i) capturing the complex relationships between molecular structures and multiple properties remains challenging, and (ii) the narrow coverage and incomplete annotations of molecular properties weaken the effectiveness of property-based models. To tackle these limitations, we propose HSPAG, a data-efficient framework featuring hierarchical structure-property alignment. By treating SMILES and molecular properties as complementary modalities, the model learns their relationships at atom, substructure, and whole-molecule levels. Moreover, we select representative samples through scaffold clustering and hard samples via an auxiliary variational auto-encoder (VAE), substantially reducing the required pre-training data. In addition, we incorporate a property relevance-aware masking mechanism and diversified perturbation strategies to enhance generation quality under sparse annotations. Experiments demonstrate that HSPAG captures fine-grained structure-property relationships and supports controllable generation under multiple property constraints. Two real-world case studies further validate the editing capabilities of HSPAG.
X-SAM: From Segment Anything to Any Segmentation
Aug 06, 2025Large Language Models (LLMs) demonstrate strong capabilities in broad knowledge representation, yet they are inherently deficient in pixel-level perceptual understanding. Although the Segment Anything Model (SAM) represents a significant advancement in visual-prompt-driven image segmentation, it exhibits notable limitations in multi-mask prediction and category-specific segmentation tasks, and it cannot integrate all segmentation tasks within a unified model architecture. To address these limitations, we present X-SAM, a streamlined Multimodal Large Language Model (MLLM) framework that extends the segmentation paradigm from \textit{segment anything} to \textit{any segmentation}. Specifically, we introduce a novel unified framework that enables more advanced pixel-level perceptual comprehension for MLLMs. Furthermore, we propose a new segmentation task, termed Visual GrounDed (VGD) segmentation, which segments all instance objects with interactive visual prompts and empowers MLLMs with visual grounded, pixel-wise interpretative capabilities. To enable effective training on diverse data sources, we present a unified training strategy that supports co-training across multiple datasets. Experimental results demonstrate that X-SAM achieves state-of-the-art performance on a wide range of image segmentation benchmarks, highlighting its efficiency for multimodal, pixel-level visual understanding. Code is available at https://github.com/wanghao9610/X-SAM.
RoboTron-Sim: Improving Real-World Driving via Simulated Hard-Case
Aug 06, 2025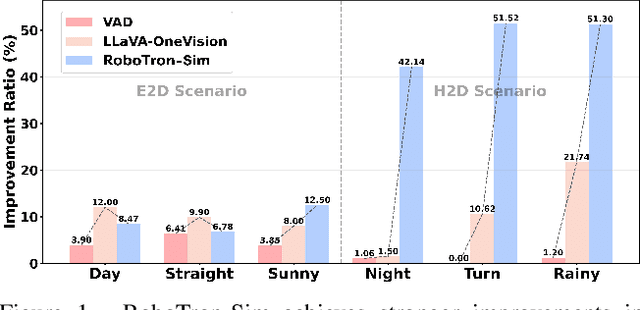



Collecting real-world data for rare high-risk scenarios, long-tailed driving events, and complex interactions remains challenging, leading to poor performance of existing autonomous driving systems in these critical situations. In this paper, we propose RoboTron-Sim that improves real-world driving in critical situations by utilizing simulated hard cases. First, we develop a simulated dataset called Hard-case Augmented Synthetic Scenarios (HASS), which covers 13 high-risk edge-case categories, as well as balanced environmental conditions such as day/night and sunny/rainy. Second, we introduce Scenario-aware Prompt Engineering (SPE) and an Image-to-Ego Encoder (I2E Encoder) to enable multimodal large language models to effectively learn real-world challenging driving skills from HASS, via adapting to environmental deviations and hardware differences between real-world and simulated scenarios. Extensive experiments on nuScenes show that RoboTron-Sim improves driving performance in challenging scenarios by around 50%, achieving state-of-the-art results in real-world open-loop planning. Qualitative results further demonstrate the effectiveness of RoboTron-Sim in better managing rare high-risk driving scenarios. Project page: https://stars79689.github.io/RoboTron-Sim/
DriveMM: All-in-One Large Multimodal Model for Autonomous Driving
Dec 10, 2024



Large Multimodal Models (LMMs) have demonstrated exceptional comprehension and interpretation capabilities in Autonomous Driving (AD) by incorporating large language models. Despite the advancements, current data-driven AD approaches tend to concentrate on a single dataset and specific tasks, neglecting their overall capabilities and ability to generalize. To bridge these gaps, we propose DriveMM, a general large multimodal model designed to process diverse data inputs, such as images and multi-view videos, while performing a broad spectrum of AD tasks, including perception, prediction, and planning. Initially, the model undergoes curriculum pre-training to process varied visual signals and perform basic visual comprehension and perception tasks. Subsequently, we augment and standardize various AD-related datasets to fine-tune the model, resulting in an all-in-one LMM for autonomous driving. To assess the general capabilities and generalization ability, we conduct evaluations on six public benchmarks and undertake zero-shot transfer on an unseen dataset, where DriveMM achieves state-of-the-art performance across all tasks. We hope DriveMM as a promising solution for future end-toend autonomous driving applications in the real world.
Making Large Language Models Better Planners with Reasoning-Decision Alignment
Aug 25, 2024Data-driven approaches for autonomous driving (AD) have been widely adopted in the past decade but are confronted with dataset bias and uninterpretability. Inspired by the knowledge-driven nature of human driving, recent approaches explore the potential of large language models (LLMs) to improve understanding and decision-making in traffic scenarios. They find that the pretrain-finetune paradigm of LLMs on downstream data with the Chain-of-Thought (CoT) reasoning process can enhance explainability and scene understanding. However, such a popular strategy proves to suffer from the notorious problems of misalignment between the crafted CoTs against the consequent decision-making, which remains untouched by previous LLM-based AD methods. To address this problem, we motivate an end-to-end decision-making model based on multimodality-augmented LLM, which simultaneously executes CoT reasoning and carries out planning results. Furthermore, we propose a reasoning-decision alignment constraint between the paired CoTs and planning results, imposing the correspondence between reasoning and decision-making. Moreover, we redesign the CoTs to enable the model to comprehend complex scenarios and enhance decision-making performance. We dub our proposed large language planners with reasoning-decision alignment as RDA-Driver. Experimental evaluations on the nuScenes and DriveLM-nuScenes benchmarks demonstrate the effectiveness of our RDA-Driver in enhancing the performance of end-to-end AD systems. Specifically, our RDA-Driver achieves state-of-the-art planning performance on the nuScenes dataset with 0.80 L2 error and 0.32 collision rate, and also achieves leading results on challenging DriveLM-nuScenes benchmarks with 0.82 L2 error and 0.38 collision rate.
SoccerNet 2023 Challenges Results
Sep 12, 2023



The SoccerNet 2023 challenges were the third annual video understanding challenges organized by the SoccerNet team. For this third edition, the challenges were composed of seven vision-based tasks split into three main themes. The first theme, broadcast video understanding, is composed of three high-level tasks related to describing events occurring in the video broadcasts: (1) action spotting, focusing on retrieving all timestamps related to global actions in soccer, (2) ball action spotting, focusing on retrieving all timestamps related to the soccer ball change of state, and (3) dense video captioning, focusing on describing the broadcast with natural language and anchored timestamps. The second theme, field understanding, relates to the single task of (4) camera calibration, focusing on retrieving the intrinsic and extrinsic camera parameters from images. The third and last theme, player understanding, is composed of three low-level tasks related to extracting information about the players: (5) re-identification, focusing on retrieving the same players across multiple views, (6) multiple object tracking, focusing on tracking players and the ball through unedited video streams, and (7) jersey number recognition, focusing on recognizing the jersey number of players from tracklets. Compared to the previous editions of the SoccerNet challenges, tasks (2-3-7) are novel, including new annotations and data, task (4) was enhanced with more data and annotations, and task (6) now focuses on end-to-end approaches. More information on the tasks, challenges, and leaderboards are available on https://www.soccer-net.org. Baselines and development kits can be found on https://github.com/SoccerNet.