 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHORIZON: Recoverability-Governed Curriculum for Physical-Domain Scaling
Jun 03, 2026Scaling robust robot policies requires more than broader randomization, because physical-domain experience must remain organized and learnable throughout training. We study when a policy can benefit from harder physics and identify recoverability as a central constraint in on-policy physical-domain scaling. In on-policy training, new dynamics are useful only insofar as they remain close enough to the current policy to generate corrective on-policy data, rather than collapsing rollouts into unrecoverable failures. Using quadruped locomotion as a physically demanding benchmark for embodied generalization, we introduce HORIZON, a checkpointed frontier curriculum that expands physical domains only within the current policy's recoverable boundary. HORIZON uses rollback and boundary refinement to govern each expansion step, turning fixed randomization into a continual process of physical-domain growth. Experiments reveal three regularities of physical-domain expansion. First, direct domain widening is uneven across physical axes and often unlearnable without staged ordering. Second, domain composition is non-monotonic, and adding more domains beyond a compact core can dilute recoverable joint samples and reduce overall robustness. Third, offline distillation of isolated experts cannot substitute for the joint interaction generated by on-policy curriculum. Together, these results frame physical-domain generalization as a continual growth problem for embodied control, with recoverability as the organizing principle for on-policy expansion.
MatFormBench: A Benchmarking Evaluation Framework for Target-Driven Materials Formulation
May 26, 2026Inverse design of materials has significantly advanced target-driven formulation optimization, yet existing materials machine learning benchmarks remain limited to forward property prediction, failing to systematically evaluate inverse optimization and generation algorithms, a critical gap that hinders the progress of target-driven materials design. To address this limitation, we propose MatFormBench, a novel benchmarking ecosystem tailored to evaluate and guide generative strategies for target-driven formulation. MatFormBench integrates a physics-driven formulation generation scheme to generate synthetic samples that faithfully emulate realistic materials structure-property response relationships, complemented by five escalating difficulty levels to quantify the complexity of these relationships. To rigorously assess algorithm performance, we further propose MatFormScore, a multi-dimensional metric that comprehensively quantifies performance across five critical axes: target success, search efficiency, exploratory capacity, robustness, and stability. We validate MatFormBench by evaluating 39 diverse inverse design algorithms, covering classical surrogate-assisted black-box search, state-of-the-art deep generative models, and increasingly popular Large Language Model (LLM)-based recommendation strategies. Across 1170 standardized algorithm-task evaluations, diffusion-based models demonstrate the strongest overall performance, while Variational Autoencoder (VAE)-based and Genetic Algorithm (GA)-based methods exhibit distinct advantages in specific scenarios. By establishing a unified evaluation standard for target-driven materials formulation, MatFormBench enables reproducible benchmarking, principled algorithm comparison, and diagnostic analysis of inverse design strategies, providing a foundational tool for advancing materials inverse design.
Clipping Bottleneck: Stabilizing RLVR via Stochastic Recovery of Near-Boundary Signals
May 21, 2026Reinforcement Learning with Verifiable Rewards (RLVR) has emerged as a central paradigm for scaling LLM reasoning, yet its optimization often suffers from training instability and suboptimal convergence. Through a systematic dissection of clipping-based GRPO-style objectives, we identify the rigid clipping decision induced by hard clipping as a key practical bottleneck in the studied RLVR setups. Specifically, our analysis suggests that informative signals can lie in the near-boundary region just beyond the clipping threshold, and are therefore discarded by the standard hard-clipping rule. Notably, once this bottleneck is precisely identified, even simple stochastic perturbations at the boundary can recover meaningful performance gains. Building on this finding, we propose Near-boundary Stochastic Rescue (NSR), a minimal, plug-and-play modification that stochastically retains these slightly out-of-bound tokens to recover lost signals. While NSR, via stochastic sampling, can be interpreted as inducing an implicit gradient decay in expectation, our ablations reveal that its stochastic, boundary-local rescue mechanism is consistently more effective than deterministic gradient decay. Validated by extensive experiments across model sizes from 7B to 30B and both dense and MoE architectures, as a plug-and-play solution, NSR substantially improves training stability and delivers consistent gains over strong baselines such as DAPO and GSPO.
One-Way Policy Optimization for Self-Evolving LLMs
May 21, 2026Reinforcement Learning with Verifiable Rewards (RLVR) has become a promising paradigm for scaling reasoning capabilities of Large Language Models (LLMs). However, the sparsity of binary verifier rewards often leads to low efficiency and optimization instability. To stabilize training, existing methods typically impose token-level constraints relative to a reference policy. We identify that such constraints penalize deviations indiscriminately; this can flip verifier-determined direction when the policy attempts to outperform the reference, thereby suppressing gains. To resolve this, we propose One-Way Policy Optimization (OWPO), a method based on the principle of decoupling optimization direction from update magnitude. In OWPO, the verifier dictates the update direction, while the reference policy serves only to adjust the magnitude. Specifically, OWPO applies asymmetric reweighting: it performs Accelerated Alignment for inferior deviations (where the policy lags behind the reference) and Gain Locking for superior deviations (where the policy surpasses the reference). Furthermore, by incorporating iterative reference updates, OWPO creates a ``Ratchet Effect'' that continuously consolidates gains. Experimental results demonstrate that OWPO outperforms strong baselines, including DAPO, OPD, and MOPD, breaking the bottleneck of fixed priors to enable continuous self-evolution without reliance on external reference models.
PRM-as-a-Judge: A Dense Evaluation Paradigm for Fine-Grained Robotic Auditing
Mar 23, 2026Current robotic evaluation is still largely dominated by binary success rates, which collapse rich execution processes into a single outcome and obscure critical qualities such as progress, efficiency, and stability. To address this limitation, we propose PRM-as-a-Judge, a dense evaluation paradigm that leverages Process Reward Models (PRMs) to audit policy execution directly from trajectory videos by estimating task progress from observation sequences. Central to this paradigm is the OPD (Outcome-Process-Diagnosis) metric system, which explicitly formalizes execution quality via a task-aligned progress potential. We characterize dense robotic evaluation through two axiomatic properties: macro-consistency, which requires additive and path-consistent aggregation, and micro-resolution, which requires sensitivity to fine-grained physical evolution. Under this formulation, potential-based PRM judges provide a natural instantiation of dense evaluation, with macro-consistency following directly from the induced scalar potential. We empirically validate the micro-resolution property using RoboPulse, a diagnostic benchmark specifically designed for probing micro-scale progress discrimination, where several trajectory-trained PRM judges outperform discriminative similarity-based methods and general-purpose foundation-model judges. Finally, leveraging PRM-as-a-Judge and the OPD metric system, we conduct a structured audit of mainstream policy paradigms across long-horizon tasks, revealing behavioral signatures and failure modes that are invisible to outcome-only metrics.
cuGenOpt: A GPU-Accelerated General-Purpose Metaheuristic Framework for Combinatorial Optimization
Mar 19, 2026Combinatorial optimization problems arise in logistics, scheduling, and resource allocation, yet existing approaches face a fundamental trade-off among generality, performance, and usability. We present cuGenOpt, a GPU-accelerated general-purpose metaheuristic framework that addresses all three dimensions simultaneously. At the engine level, cuGenOpt adopts a "one block evolves one solution" CUDA architecture with a unified encoding abstraction (permutation, binary, integer), a two-level adaptive operator selection mechanism, and hardware-aware resource management. At the extensibility level, a user-defined operator registration interface allows domain experts to inject problem-specific CUDA search operators. At the usability level, a JIT compilation pipeline exposes the framework as a pure-Python API, and an LLM-based modeling assistant converts natural-language problem descriptions into executable solver code. Experiments across five thematic suites on three GPU architectures (T4, V100, A800) show that cuGenOpt outperforms general MIP solvers by orders of magnitude, achieves competitive quality against specialized solvers on instances up to n=150, and attains 4.73% gap on TSP-442 within 30s. Twelve problem types spanning five encoding variants are solved to optimality. Framework-level optimizations cumulatively reduce pcb442 gap from 36% to 4.73% and boost VRPTW throughput by 75-81%. Code: https://github.com/L-yang-yang/cugenopt
BioProAgent: Neuro-Symbolic Grounding for Constrained Scientific Planning
Mar 01, 2026Large language models (LLMs) have demonstrated significant reasoning capabilities in scientific discovery but struggle to bridge the gap to physical execution in wet-labs. In these irreversible environments, probabilistic hallucinations are not merely incorrect, but also cause equipment damage or experimental failure. To address this, we propose \textbf{BioProAgent}, a neuro-symbolic framework that anchors probabilistic planning in a deterministic Finite State Machine (FSM). We introduce a State-Augmented Planning mechanism that enforces a rigorous \textit{Design-Verify-Rectify} workflow, ensuring hardware compliance before execution. Furthermore, we address the context bottleneck inherent in complex device schemas by \textit{Semantic Symbol Grounding}, reducing token consumption by $\sim$6$\times$ through symbolic abstraction. In the extended BioProBench benchmark, BioProAgent achieves 95.6\% physical compliance (compared to 21.0\% for ReAct), demonstrating that neuro-symbolic constraints are essential for reliable autonomy in irreversible physical environments. \footnote{Code at https://github.com/YuyangSunshine/bioproagent and project at https://yuyangsunshine.github.io/BioPro-Project/}
Sound Field Estimation Using Optimal Transport Barycenters in the Presence of Phase Errors
Feb 05, 2026This study introduces a novel approach for estimating plane-wave coefficients in sound field reconstruction, specifically addressing challenges posed by error-in-variable phase perturbations. Such systematic errors typically arise from sensor mis-calibration, including uncertainties in sensor positions and response characteristics, leading to measurement-induced phase shifts in plane wave coefficients. Traditional methods often result in biased estimates or non-convex solutions. To overcome these issues, we propose an optimal transport (OT) framework. This framework operates on a set of lifted non-negative measures that correspond to observation-dependent shifted coefficients relative to the unperturbed ones. By applying OT, the supports of the measures are transported toward an optimal average in the phase space, effectively morphing them into an indistinguishable state. This optimal average, known as barycenter, is linked to the estimated plane-wave coefficients using the same lifting rule. The framework addresses the ill-posed nature of the problem, due to the large number of plane waves, by adding a constant to the ground cost, ensuring the sparsity of the transport matrix. Convex consistency of the solution is maintained. Simulation results confirm that our proposed method provides more accurate coefficient estimations compared to baseline approaches in scenarios with both additive noise and phase perturbations.
Translating Flow to Policy via Hindsight Online Imitation
Dec 22, 2025Recent advances in hierarchical robot systems leverage a high-level planner to propose task plans and a low-level policy to generate robot actions. This design allows training the planner on action-free or even non-robot data sources (e.g., videos), providing transferable high-level guidance. Nevertheless, grounding these high-level plans into executable actions remains challenging, especially with the limited availability of high-quality robot data. To this end, we propose to improve the low-level policy through online interactions. Specifically, our approach collects online rollouts, retrospectively annotates the corresponding high-level goals from achieved outcomes, and aggregates these hindsight-relabeled experiences to update a goal-conditioned imitation policy. Our method, Hindsight Flow-conditioned Online Imitation (HinFlow), instantiates this idea with 2D point flows as the high-level planner. Across diverse manipulation tasks in both simulation and physical world, our method achieves more than $2\times$ performance improvement over the base policy, significantly outperforming the existing methods. Moreover, our framework enables policy acquisition from planners trained on cross-embodiment video data, demonstrating its potential for scalable and transferable robot learning.
Scaling Up AI-Generated Image Detection via Generator-Aware Prototypes
Dec 15, 2025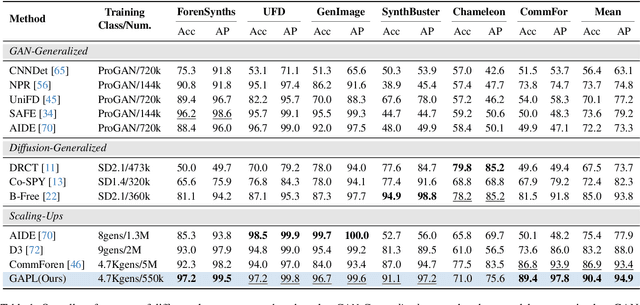
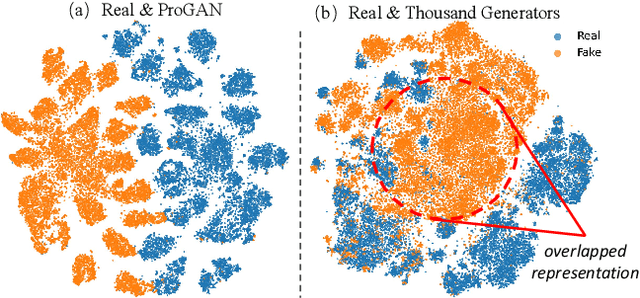
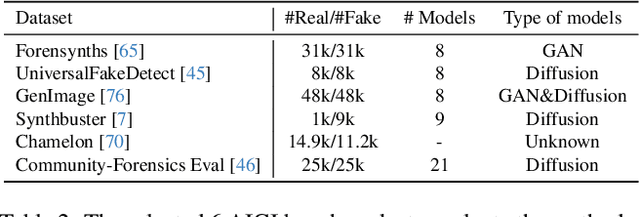
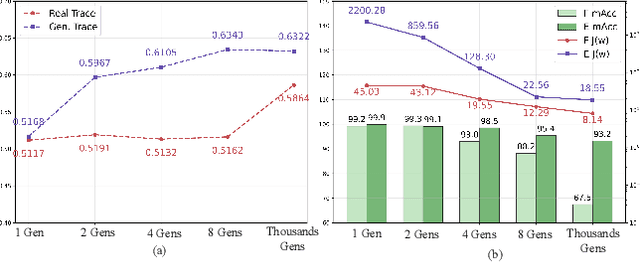
The pursuit of a universal AI-generated image (AIGI) detector often relies on aggregating data from numerous generators to improve generalization. However, this paper identifies a paradoxical phenomenon we term the Benefit then Conflict dilemma, where detector performance stagnates and eventually degrades as source diversity expands. Our systematic analysis, diagnoses this failure by identifying two core issues: severe data-level heterogeneity, which causes the feature distributions of real and synthetic images to increasingly overlap, and a critical model-level bottleneck from fixed, pretrained encoders that cannot adapt to the rising complexity. To address these challenges, we propose Generator-Aware Prototype Learning (GAPL), a framework that constrain representation with a structured learning paradigm. GAPL learns a compact set of canonical forgery prototypes to create a unified, low-variance feature space, effectively countering data heterogeneity.To resolve the model bottleneck, it employs a two-stage training scheme with Low-Rank Adaptation, enhancing its discriminative power while preserving valuable pretrained knowledge. This approach establishes a more robust and generalizable decision boundary. Through extensive experiments, we demonstrate that GAPL achieves state-of-the-art performance, showing superior detection accuracy across a wide variety of GAN and diffusion-based generators. Code is available at https://github.com/UltraCapture/GAPL