 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoccerNet 2023 Challenges Results
Sep 12, 2023



The SoccerNet 2023 challenges were the third annual video understanding challenges organized by the SoccerNet team. For this third edition, the challenges were composed of seven vision-based tasks split into three main themes. The first theme, broadcast video understanding, is composed of three high-level tasks related to describing events occurring in the video broadcasts: (1) action spotting, focusing on retrieving all timestamps related to global actions in soccer, (2) ball action spotting, focusing on retrieving all timestamps related to the soccer ball change of state, and (3) dense video captioning, focusing on describing the broadcast with natural language and anchored timestamps. The second theme, field understanding, relates to the single task of (4) camera calibration, focusing on retrieving the intrinsic and extrinsic camera parameters from images. The third and last theme, player understanding, is composed of three low-level tasks related to extracting information about the players: (5) re-identification, focusing on retrieving the same players across multiple views, (6) multiple object tracking, focusing on tracking players and the ball through unedited video streams, and (7) jersey number recognition, focusing on recognizing the jersey number of players from tracklets. Compared to the previous editions of the SoccerNet challenges, tasks (2-3-7) are novel, including new annotations and data, task (4) was enhanced with more data and annotations, and task (6) now focuses on end-to-end approaches. More information on the tasks, challenges, and leaderboards are available on https://www.soccer-net.org. Baselines and development kits can be found on https://github.com/SoccerNet.
COMEDIAN: Self-Supervised Learning and Knowledge Distillation for Action Spotting using Transformers
Sep 03, 2023



We present COMEDIAN, a novel pipeline to initialize spatio-temporal transformers for action spotting, which involves self-supervised learning and knowledge distillation. Action spotting is a timestamp-level temporal action detection task. Our pipeline consists of three steps, with two initialization stages. First, we perform self-supervised initialization of a spatial transformer using short videos as input. Additionally, we initialize a temporal transformer that enhances the spatial transformer's outputs with global context through knowledge distillation from a pre-computed feature bank aligned with each short video segment. In the final step, we fine-tune the transformers to the action spotting task. The experiments, conducted on the SoccerNet-v2 dataset, demonstrate state-of-the-art performance and validate the effectiveness of COMEDIAN's pretraining paradigm. Our results highlight several advantages of our pretraining pipeline, including improved performance and faster convergence compared to non-pretrained models.
Self-Supervised Representation Learning using Visual Field Expansion on Digital Pathology
Sep 07, 2021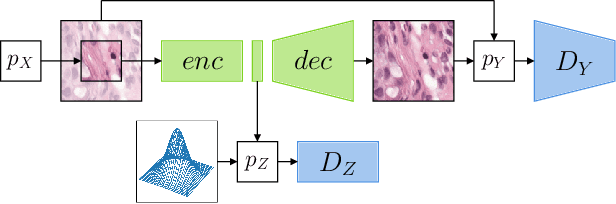
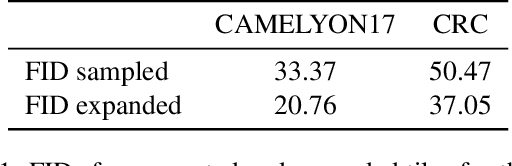
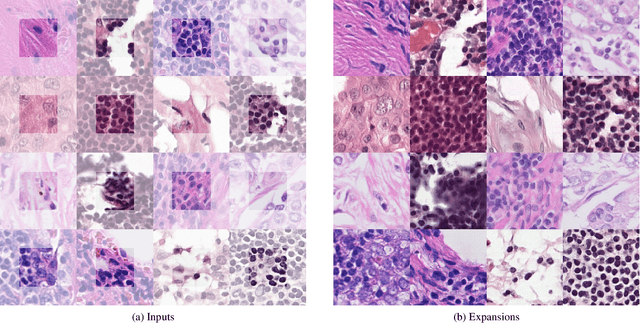
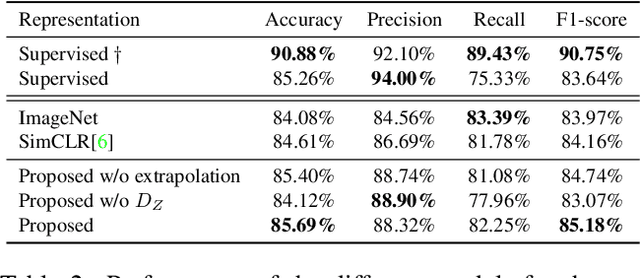
The examination of histopathology images is considered to be the gold standard for the diagnosis and stratification of cancer patients. A key challenge in the analysis of such images is their size, which can run into the gigapixels and can require tedious screening by clinicians. With the recent advances in computational medicine, automatic tools have been proposed to assist clinicians in their everyday practice. Such tools typically process these large images by slicing them into tiles that can then be encoded and utilized for different clinical models. In this study, we propose a novel generative framework that can learn powerful representations for such tiles by learning to plausibly expand their visual field. In particular, we developed a progressively grown generative model with the objective of visual field expansion. Thus trained, our model learns to generate different tissue types with fine details, while simultaneously learning powerful representations that can be used for different clinical endpoints, all in a self-supervised way. To evaluate the performance of our model, we conducted classification experiments on CAMELYON17 and CRC benchmark datasets, comparing favorably to other self-supervised and pre-trained strategies that are commonly used in digital pathology. Our code is available at https://github.com/jcboyd/cdpath21-gan.