 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMLLM-Tool: A Multimodal Large Language Model For Tool Agent Learning
Jan 24, 2024



Recently, the astonishing performance of large language models (LLMs) in natural language comprehension and generation tasks triggered lots of exploration of using them as central controllers to build agent systems. Multiple studies focus on bridging the LLMs to external tools to extend the application scenarios. However, the current LLMs' perceiving tool-use ability is limited to a single text query, which may result in ambiguity in understanding the users' real intentions. LLMs are expected to eliminate that by perceiving the visual- or auditory-grounded instructions' information. Therefore, in this paper, we propose MLLM-Tool, a system incorporating open-source LLMs and multi-modal encoders so that the learnt LLMs can be conscious of multi-modal input instruction and then select the function-matched tool correctly. To facilitate the evaluation of the model's capability, we collect a dataset featured by consisting of multi-modal input tools from HuggingFace. Another important feature of our dataset is that our dataset also contains multiple potential choices for the same instruction due to the existence of identical functions and synonymous functions, which provides more potential solutions for the same query. The experiments reveal that our MLLM-Tool is capable of recommending appropriate tools for multi-modal instructions. Codes and data are available at https://github.com/MLLM-Tool/MLLM-Tool.
SoccerNet 2023 Challenges Results
Sep 12, 2023



The SoccerNet 2023 challenges were the third annual video understanding challenges organized by the SoccerNet team. For this third edition, the challenges were composed of seven vision-based tasks split into three main themes. The first theme, broadcast video understanding, is composed of three high-level tasks related to describing events occurring in the video broadcasts: (1) action spotting, focusing on retrieving all timestamps related to global actions in soccer, (2) ball action spotting, focusing on retrieving all timestamps related to the soccer ball change of state, and (3) dense video captioning, focusing on describing the broadcast with natural language and anchored timestamps. The second theme, field understanding, relates to the single task of (4) camera calibration, focusing on retrieving the intrinsic and extrinsic camera parameters from images. The third and last theme, player understanding, is composed of three low-level tasks related to extracting information about the players: (5) re-identification, focusing on retrieving the same players across multiple views, (6) multiple object tracking, focusing on tracking players and the ball through unedited video streams, and (7) jersey number recognition, focusing on recognizing the jersey number of players from tracklets. Compared to the previous editions of the SoccerNet challenges, tasks (2-3-7) are novel, including new annotations and data, task (4) was enhanced with more data and annotations, and task (6) now focuses on end-to-end approaches. More information on the tasks, challenges, and leaderboards are available on https://www.soccer-net.org. Baselines and development kits can be found on https://github.com/SoccerNet.
E2E-LOAD: End-to-End Long-form Online Action Detection
Jun 13, 2023



Recently, there has been a growing trend toward feature-based approaches for Online Action Detection (OAD). However, these approaches have limitations due to their fixed backbone design, which ignores the potential capability of a trainable backbone. In this paper, we propose the first end-to-end OAD model, termed E2E-LOAD, designed to address the major challenge of OAD, namely, long-term understanding and efficient online reasoning. Specifically, our proposed approach adopts an initial spatial model that is shared by all frames and maintains a long sequence cache for inference at a low computational cost. We also advocate an asymmetric spatial-temporal model for long-form and short-form modeling effectively. Furthermore, we propose a novel and efficient inference mechanism that accelerates heavy spatial-temporal exploration. Extensive ablation studies and experiments demonstrate the effectiveness and efficiency of our proposed method. Notably, we achieve 17.3 (+12.6) FPS for end-to-end OAD with 72.4%~(+1.2%), 90.3%~(+0.7%), and 48.1%~(+26.0%) mAP on THMOUS14, TVSeries, and HDD, respectively, which is 3x faster than previous approaches. The source code will be made publicly available.
Bridging the Gap Between End-to-end and Non-End-to-end Multi-Object Tracking
May 22, 2023



Existing end-to-end Multi-Object Tracking (e2e-MOT) methods have not surpassed non-end-to-end tracking-by-detection methods. One potential reason is its label assignment strategy during training that consistently binds the tracked objects with tracking queries and then assigns the few newborns to detection queries. With one-to-one bipartite matching, such an assignment will yield unbalanced training, i.e., scarce positive samples for detection queries, especially for an enclosed scene, as the majority of the newborns come on stage at the beginning of videos. Thus, e2e-MOT will be easier to yield a tracking terminal without renewal or re-initialization, compared to other tracking-by-detection methods. To alleviate this problem, we present Co-MOT, a simple and effective method to facilitate e2e-MOT by a novel coopetition label assignment with a shadow concept. Specifically, we add tracked objects to the matching targets for detection queries when performing the label assignment for training the intermediate decoders. For query initialization, we expand each query by a set of shadow counterparts with limited disturbance to itself. With extensive ablations, Co-MOT achieves superior performance without extra costs, e.g., 69.4% HOTA on DanceTrack and 52.8% TETA on BDD100K. Impressively, Co-MOT only requires 38\% FLOPs of MOTRv2 to attain a similar performance, resulting in the 1.4$\times$ faster inference speed.
Weakly Supervised Video Representation Learning with Unaligned Text for Sequential Videos
Mar 28, 2023



Sequential video understanding, as an emerging video understanding task, has driven lots of researchers' attention because of its goal-oriented nature. This paper studies weakly supervised sequential video understanding where the accurate time-stamp level text-video alignment is not provided. We solve this task by borrowing ideas from CLIP. Specifically, we use a transformer to aggregate frame-level features for video representation and use a pre-trained text encoder to encode the texts corresponding to each action and the whole video, respectively. To model the correspondence between text and video, we propose a multiple granularity loss, where the video-paragraph contrastive loss enforces matching between the whole video and the complete script, and a fine-grained frame-sentence contrastive loss enforces the matching between each action and its description. As the frame-sentence correspondence is not available, we propose to use the fact that video actions happen sequentially in the temporal domain to generate pseudo frame-sentence correspondence and supervise the network training with the pseudo labels. Extensive experiments on video sequence verification and text-to-video matching show that our method outperforms baselines by a large margin, which validates the effectiveness of our proposed approach. Code is available at https://github.com/svip-lab/WeakSVR
Multiple Object Tracking Challenge Technical Report for Team MT_IoT
Dec 07, 2022This is a brief technical report of our proposed method for Multiple-Object Tracking (MOT) Challenge in Complex Environments. In this paper, we treat the MOT task as a two-stage task including human detection and trajectory matching. Specifically, we designed an improved human detector and associated most of detection to guarantee the integrity of the motion trajectory. We also propose a location-wise matching matrix to obtain more accurate trace matching. Without any model merging, our method achieves 66.672 HOTA and 93.971 MOTA on the DanceTrack challenge dataset.
HAM: Hierarchical Attention Model with High Performance for 3D Visual Grounding
Oct 30, 2022



This paper tackles an emerging and challenging vision-language task, namely 3D visual grounding on point clouds. Many recent works benefit from Transformer with the well-known attention mechanism, leading to a tremendous breakthrough for this task. However, we find that they realize the achievement by using various pre-training or multi-stage processing. To simplify the pipeline, we carefully investigate 3D visual grounding and summarize three fundamental problems about how to develop an end-to-end model with high performance for this task. To address these problems, we especially introduce a novel Hierarchical Attention Model (HAM), offering multi-granularity representation and efficient augmentation for both given texts and multi-modal visual inputs. Extensive experimental results demonstrate the superiority of our proposed HAM model. Specifically, HAM ranks first on the large-scale ScanRefer challenge, which outperforms all the existing methods by a significant margin. Codes will be released after acceptance.
A Circular Window-based Cascade Transformer for Online Action Detection
Aug 30, 2022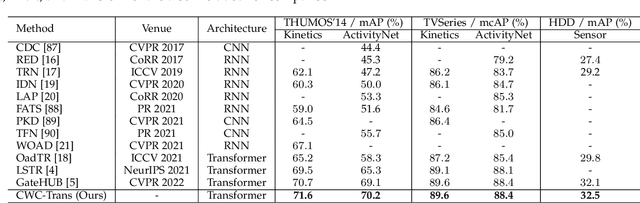
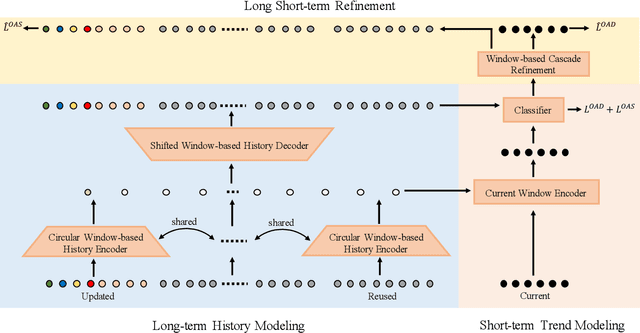
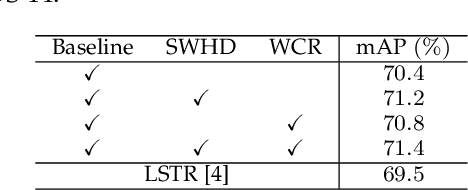
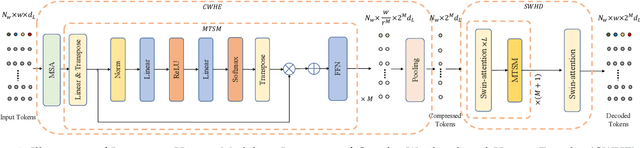
Online action detection aims at the accurate action prediction of the current frame based on long historical observations. Meanwhile, it demands real-time inference on online streaming videos. In this paper, we advocate a novel and efficient principle for online action detection. It merely updates the latest and oldest historical representations in one window but reuses the intermediate ones, which have been already computed. Based on this principle, we introduce a window-based cascade Transformer with a circular historical queue, where it conducts multi-stage attentions and cascade refinement on each window. We also explore the association between online action detection and its counterpart offline action segmentation as an auxiliary task. We find that such an extra supervision helps discriminative history clustering and acts as feature augmentation for better training the classifier and cascade refinement. Our proposed method achieves the state-of-the-art performances on three challenging datasets THUMOS'14, TVSeries, and HDD. Codes will be available after acceptance.
SVIP: Sequence VerIfication for Procedures in Videos
Dec 14, 2021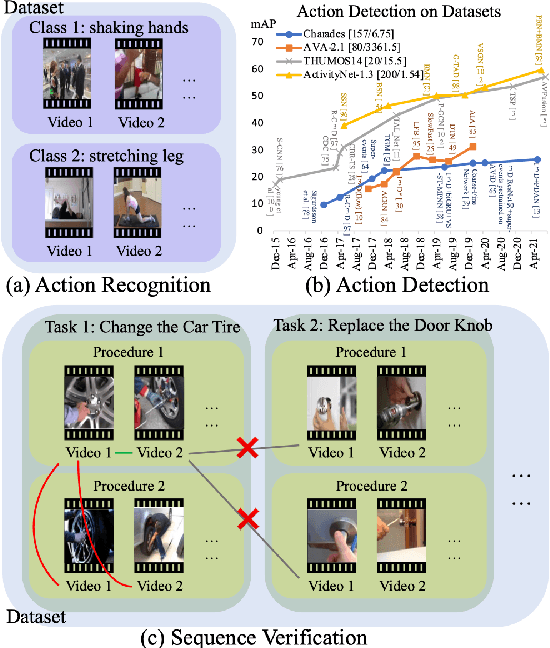

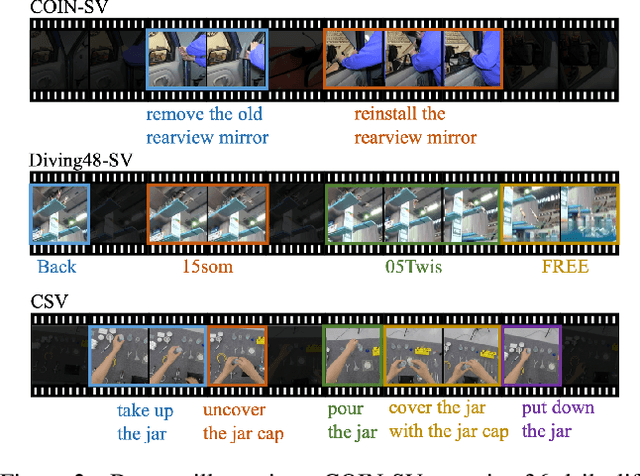
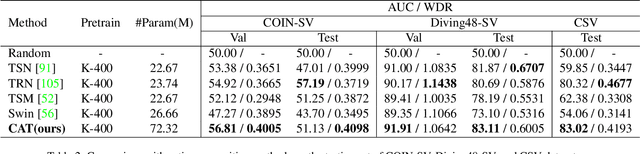
In this paper, we propose a novel sequence verification task that aims to distinguish positive video pairs performing the same action sequence from negative ones with step-level transformations but still conducting the same task. Such a challenging task resides in an open-set setting without prior action detection or segmentation that requires event-level or even frame-level annotations. To that end, we carefully reorganize two publicly available action-related datasets with step-procedure-task structure. To fully investigate the effectiveness of any method, we collect a scripted video dataset enumerating all kinds of step-level transformations in chemical experiments. Besides, a novel evaluation metric Weighted Distance Ratio is introduced to ensure equivalence for different step-level transformations during evaluation. In the end, a simple but effective baseline based on the transformer with a novel sequence alignment loss is introduced to better characterize long-term dependency between steps, which outperforms other action recognition methods. Codes and data will be released.
Two-stage Visual Cues Enhancement Network for Referring Image Segmentation
Oct 09, 2021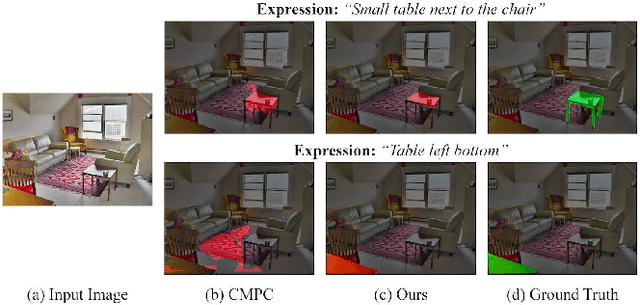
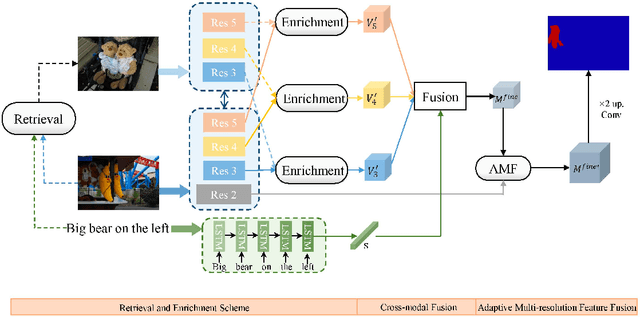
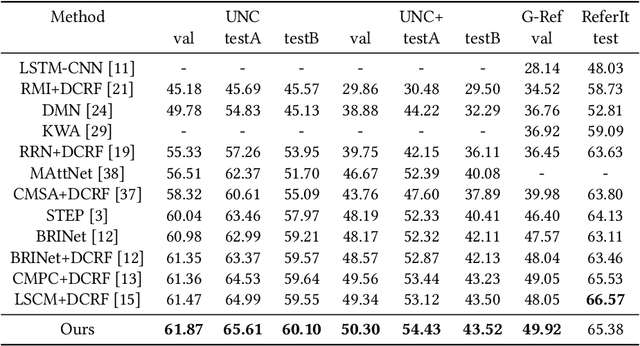
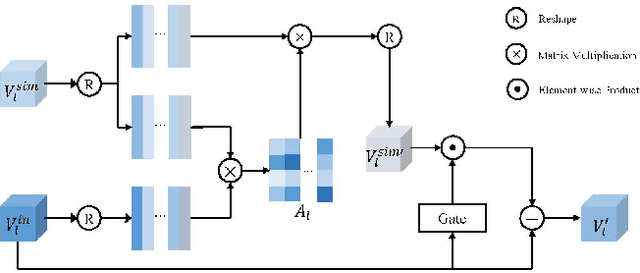
Referring Image Segmentation (RIS) aims at segmenting the target object from an image referred by one given natural language expression. The diverse and flexible expressions as well as complex visual contents in the images raise the RIS model with higher demands for investigating fine-grained matching behaviors between words in expressions and objects presented in images. However, such matching behaviors are hard to be learned and captured when the visual cues of referents (i.e. referred objects) are insufficient, as the referents with weak visual cues tend to be easily confused by cluttered background at boundary or even overwhelmed by salient objects in the image. And the insufficient visual cues issue can not be handled by the cross-modal fusion mechanisms as done in previous work. In this paper, we tackle this problem from a novel perspective of enhancing the visual information for the referents by devising a Two-stage Visual cues enhancement Network (TV-Net), where a novel Retrieval and Enrichment Scheme (RES) and an Adaptive Multi-resolution feature Fusion (AMF) module are proposed. Through the two-stage enhancement, our proposed TV-Net enjoys better performances in learning fine-grained matching behaviors between the natural language expression and image, especially when the visual information of the referent is inadequate, thus produces better segmentation results. Extensive experiments are conducted to validate the effectiveness of the proposed method on the RIS task, with our proposed TV-Net surpassing the state-of-the-art approaches on four benchmark datasets.