 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeERNIE-ViLG: Unified Generative Pre-training for Bidirectional Vision-Language Generation
Dec 31, 2021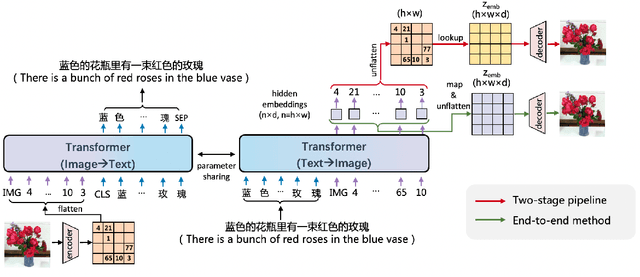
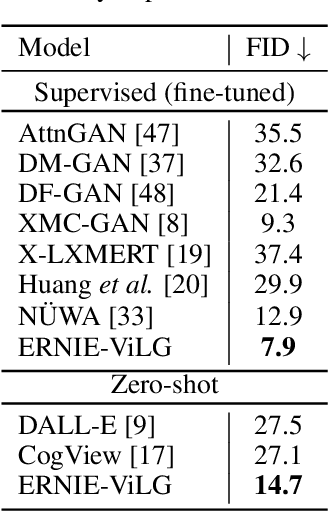
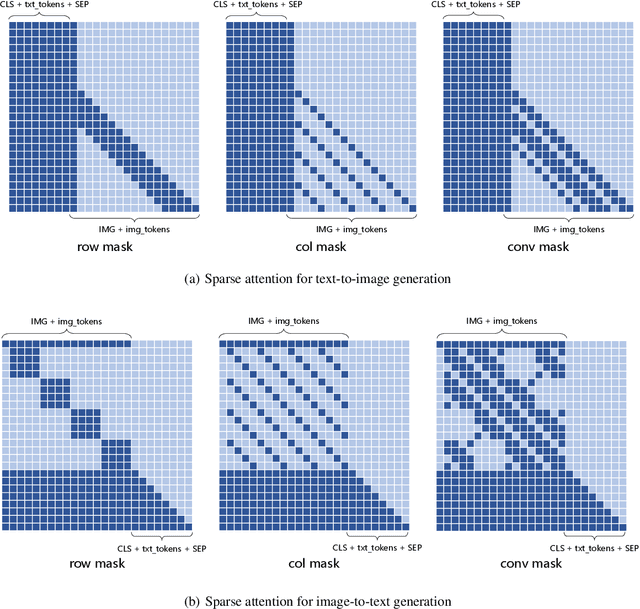

Conventional methods for the image-text generation tasks mainly tackle the naturally bidirectional generation tasks separately, focusing on designing task-specific frameworks to improve the quality and fidelity of the generated samples. Recently, Vision-Language Pre-training models have greatly improved the performance of the image-to-text generation tasks, but large-scale pre-training models for text-to-image synthesis task are still under-developed. In this paper, we propose ERNIE-ViLG, a unified generative pre-training framework for bidirectional image-text generation with transformer model. Based on the image quantization models, we formulate both image generation and text generation as autoregressive generative tasks conditioned on the text/image input. The bidirectional image-text generative modeling eases the semantic alignments across vision and language. For the text-to-image generation process, we further propose an end-to-end training method to jointly learn the visual sequence generator and the image reconstructor. To explore the landscape of large-scale pre-training for bidirectional text-image generation, we train a 10-billion parameter ERNIE-ViLG model on a large-scale dataset of 145 million (Chinese) image-text pairs which achieves state-of-the-art performance for both text-to-image and image-to-text tasks, obtaining an FID of 7.9 on MS-COCO for text-to-image synthesis and best results on COCO-CN and AIC-ICC for image captioning.
ERNIE 3.0 Titan: Exploring Larger-scale Knowledge Enhanced Pre-training for Language Understanding and Generation
Dec 23, 2021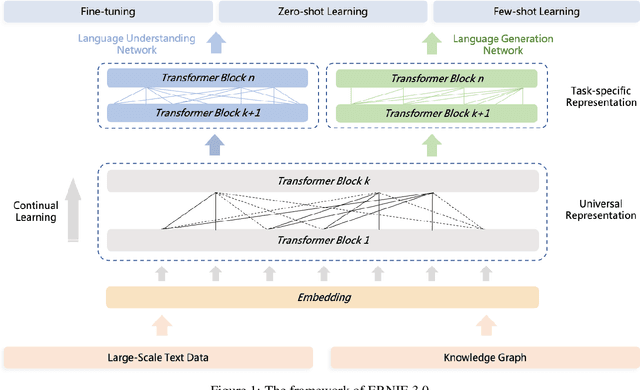
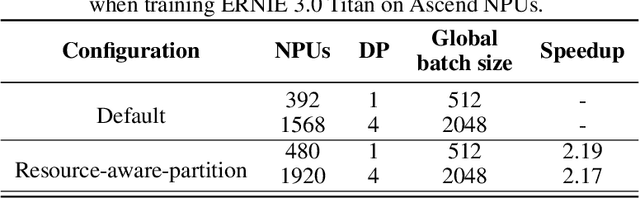
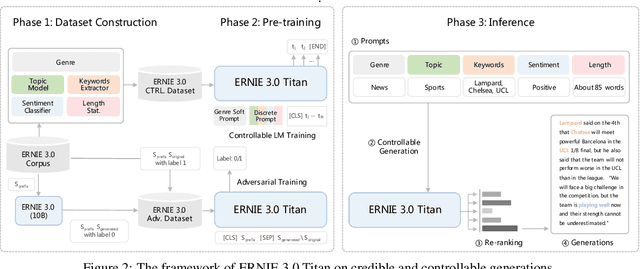
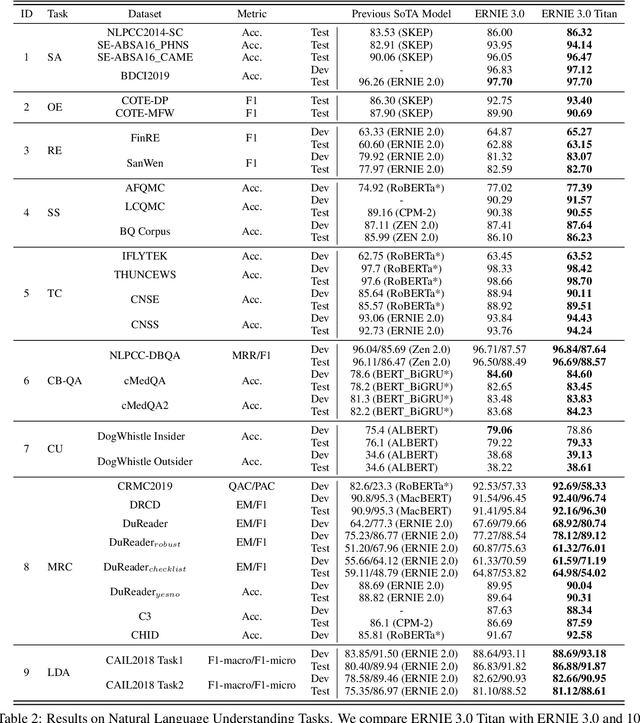
Pre-trained language models have achieved state-of-the-art results in various Natural Language Processing (NLP) tasks. GPT-3 has shown that scaling up pre-trained language models can further exploit their enormous potential. A unified framework named ERNIE 3.0 was recently proposed for pre-training large-scale knowledge enhanced models and trained a model with 10 billion parameters. ERNIE 3.0 outperformed the state-of-the-art models on various NLP tasks. In order to explore the performance of scaling up ERNIE 3.0, we train a hundred-billion-parameter model called ERNIE 3.0 Titan with up to 260 billion parameters on the PaddlePaddle platform. Furthermore, we design a self-supervised adversarial loss and a controllable language modeling loss to make ERNIE 3.0 Titan generate credible and controllable texts. To reduce the computation overhead and carbon emission, we propose an online distillation framework for ERNIE 3.0 Titan, where the teacher model will teach students and train itself simultaneously. ERNIE 3.0 Titan is the largest Chinese dense pre-trained model so far. Empirical results show that the ERNIE 3.0 Titan outperforms the state-of-the-art models on 68 NLP datasets.
End-to-end Adaptive Distributed Training on PaddlePaddle
Dec 06, 2021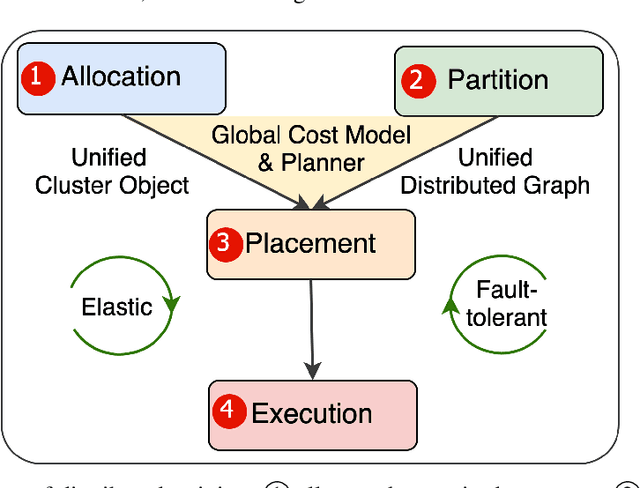
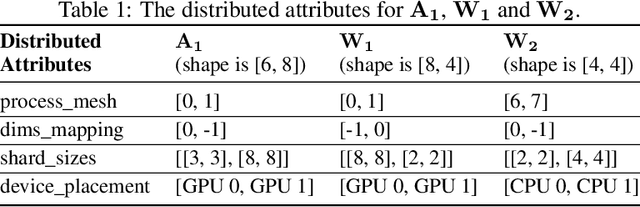
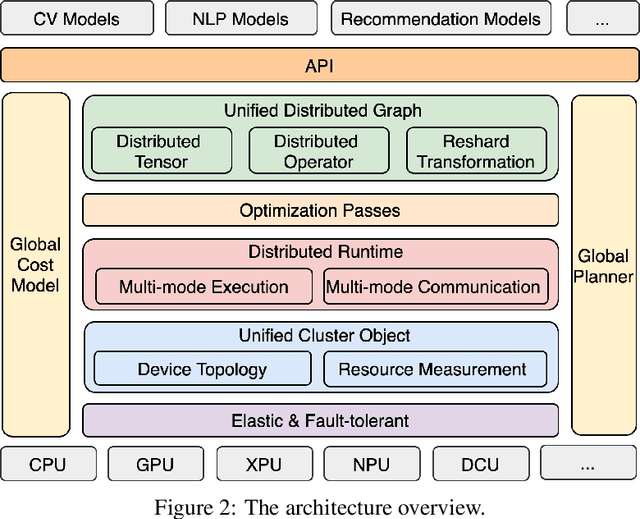
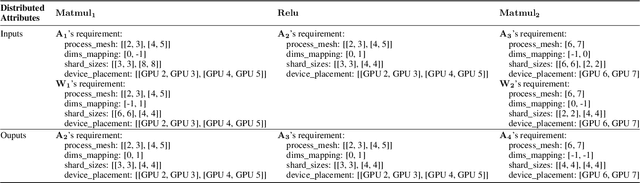
Distributed training has become a pervasive and effective approach for training a large neural network (NN) model with processing massive data. However, it is very challenging to satisfy requirements from various NN models, diverse computing resources, and their dynamic changes during a training job. In this study, we design our distributed training framework in a systematic end-to-end view to provide the built-in adaptive ability for different scenarios, especially for industrial applications and production environments, by fully considering resource allocation, model partition, task placement, and distributed execution. Based on the unified distributed graph and the unified cluster object, our adaptive framework is equipped with a global cost model and a global planner, which can enable arbitrary parallelism, resource-aware placement, multi-mode execution, fault-tolerant, and elastic distributed training. The experiments demonstrate that our framework can satisfy various requirements from the diversity of applications and the heterogeneity of resources with highly competitive performance. The ERNIE language model with 260 billion parameters is efficiently trained on thousands of AI processors with 91.7% weak scalability. The throughput of the model from the recommender system by employing the heterogeneous pipeline asynchronous execution can be increased up to 2.1 times and 3.3 times that of the GPU-only and CPU-only training respectively. Moreover, the fault-tolerant and elastic distributed training have been successfully applied to the online industrial applications, which give a reduction of 34.49% in the number of failed long-term training jobs and an increase of 33.91% for the global scheduling efficiency in the production environment.
HeterPS: Distributed Deep Learning With Reinforcement Learning Based Scheduling in Heterogeneous Environments
Nov 20, 2021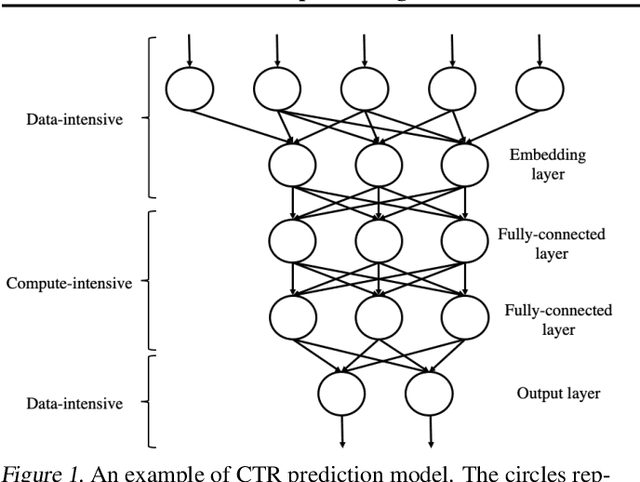

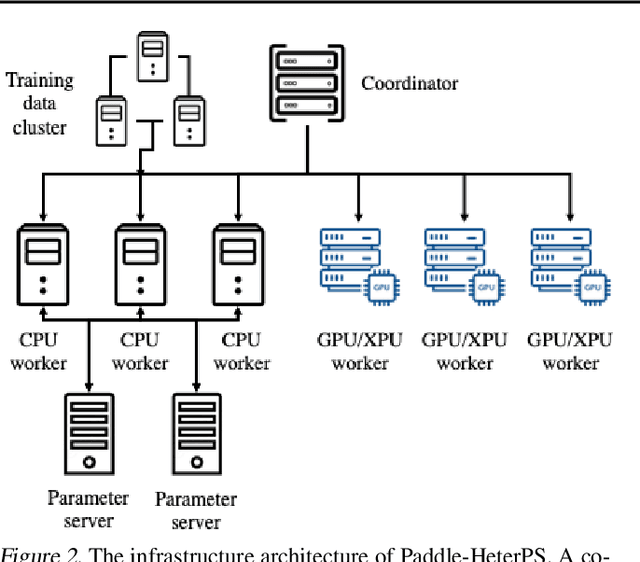
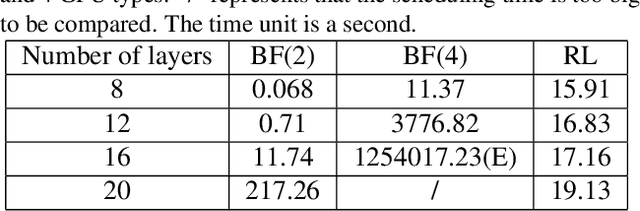
Deep neural networks (DNNs) exploit many layers and a large number of parameters to achieve excellent performance. The training process of DNN models generally handles large-scale input data with many sparse features, which incurs high Input/Output (IO) cost, while some layers are compute-intensive. The training process generally exploits distributed computing resources to reduce training time. In addition, heterogeneous computing resources, e.g., CPUs, GPUs of multiple types, are available for the distributed training process. Thus, the scheduling of multiple layers to diverse computing resources is critical for the training process. To efficiently train a DNN model using the heterogeneous computing resources, we propose a distributed framework, i.e., Paddle-Heterogeneous Parameter Server (Paddle-HeterPS), composed of a distributed architecture and a Reinforcement Learning (RL)-based scheduling method. The advantages of Paddle-HeterPS are three-fold compared with existing frameworks. First, Paddle-HeterPS enables efficient training process of diverse workloads with heterogeneous computing resources. Second, Paddle-HeterPS exploits an RL-based method to efficiently schedule the workload of each layer to appropriate computing resources to minimize the cost while satisfying throughput constraints. Third, Paddle-HeterPS manages data storage and data communication among distributed computing resources. We carry out extensive experiments to show that Paddle-HeterPS significantly outperforms state-of-the-art approaches in terms of throughput (14.5 times higher) and monetary cost (312.3% smaller). The codes of the framework are publicly available at: https://github.com/PaddlePaddle/Paddle.
PLATO-XL: Exploring the Large-scale Pre-training of Dialogue Generation
Sep 20, 2021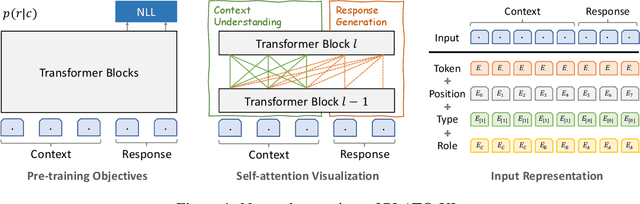
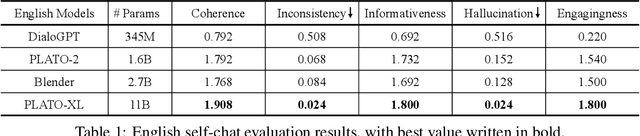

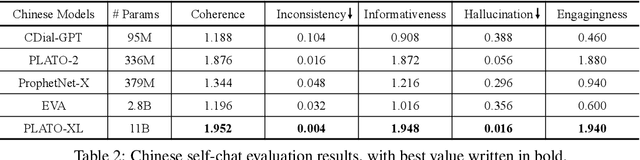
To explore the limit of dialogue generation pre-training, we present the models of PLATO-XL with up to 11 billion parameters, trained on both Chinese and English social media conversations. To train such large models, we adopt the architecture of unified transformer with high computation and parameter efficiency. In addition, we carry out multi-party aware pre-training to better distinguish the characteristic information in social media conversations. With such designs, PLATO-XL successfully achieves superior performances as compared to other approaches in both Chinese and English chitchat. We further explore the capacity of PLATO-XL on other conversational tasks, such as knowledge grounded dialogue and task-oriented conversation. The experimental results indicate that PLATO-XL obtains state-of-the-art results across multiple conversational tasks, verifying its potential as a foundation model of conversational AI.
ERNIE 3.0: Large-scale Knowledge Enhanced Pre-training for Language Understanding and Generation
Jul 05, 2021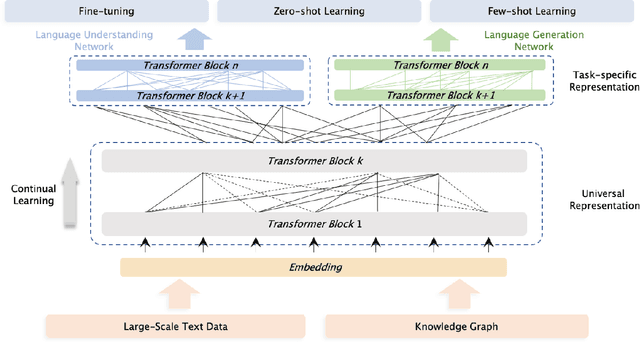

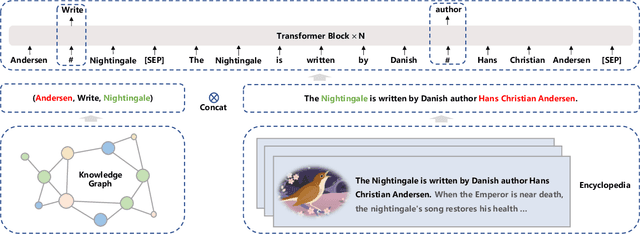
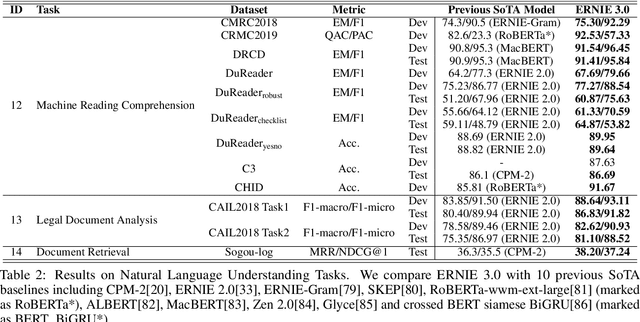
Pre-trained models have achieved state-of-the-art results in various Natural Language Processing (NLP) tasks. Recent works such as T5 and GPT-3 have shown that scaling up pre-trained language models can improve their generalization abilities. Particularly, the GPT-3 model with 175 billion parameters shows its strong task-agnostic zero-shot/few-shot learning capabilities. Despite their success, these large-scale models are trained on plain texts without introducing knowledge such as linguistic knowledge and world knowledge. In addition, most large-scale models are trained in an auto-regressive way. As a result, this kind of traditional fine-tuning approach demonstrates relatively weak performance when solving downstream language understanding tasks. In order to solve the above problems, we propose a unified framework named ERNIE 3.0 for pre-training large-scale knowledge enhanced models. It fuses auto-regressive network and auto-encoding network, so that the trained model can be easily tailored for both natural language understanding and generation tasks with zero-shot learning, few-shot learning or fine-tuning. We trained the model with 10 billion parameters on a 4TB corpus consisting of plain texts and a large-scale knowledge graph. Empirical results show that the model outperforms the state-of-the-art models on 54 Chinese NLP tasks, and its English version achieves the first place on the SuperGLUE benchmark (July 3, 2021), surpassing the human performance by +0.8% (90.6% vs. 89.8%).
ASCNet: Self-supervised Video Representation Learning with Appearance-Speed Consistency
Jun 04, 2021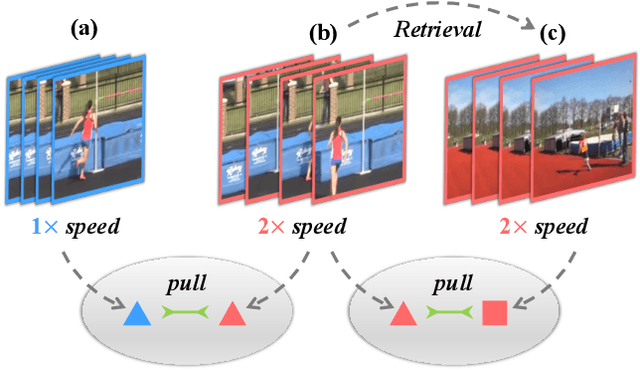

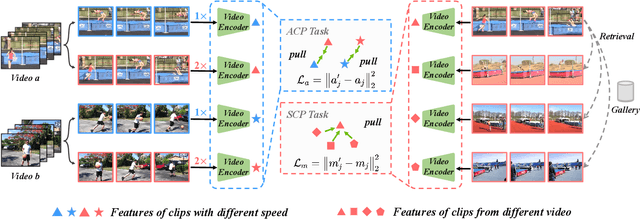
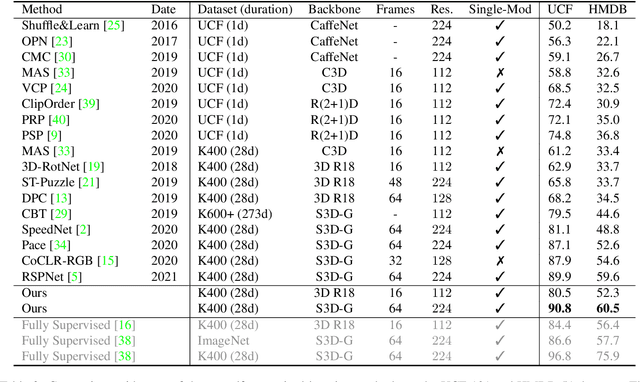
We study self-supervised video representation learning, which is a challenging task due to 1) a lack of labels for explicit supervision and 2) unstructured and noisy visual information. Existing methods mainly use contrastive loss with video clips as the instances and learn visual representation by discriminating instances from each other, but they require careful treatment of negative pairs by relying on large batch sizes, memory banks, extra modalities, or customized mining strategies, inevitably including noisy data. In this paper, we observe that the consistency between positive samples is the key to learn robust video representations. Specifically, we propose two tasks to learn the appearance and speed consistency, separately. The appearance consistency task aims to maximize the similarity between two clips of the same video with different playback speeds. The speed consistency task aims to maximize the similarity between two clips with the same playback speed but different appearance information. We show that joint optimization of the two tasks consistently improves the performance on downstream tasks, e.g., action recognition and video retrieval. Remarkably, for action recognition on the UCF-101 dataset, we achieve 90.8% accuracy without using any additional modalities or negative pairs for unsupervised pretraining, outperforming the ImageNet supervised pre-trained model. Codes and models will be available.
MNN: A Universal and Efficient Inference Engine
Feb 27, 2020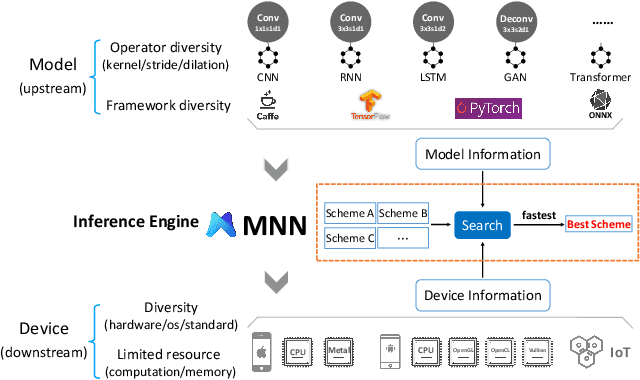
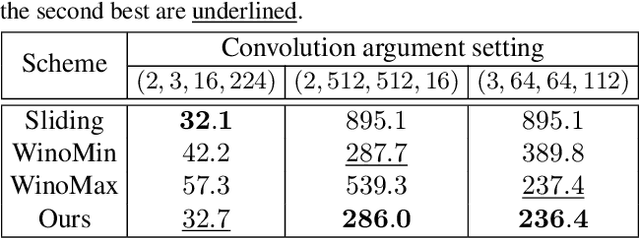
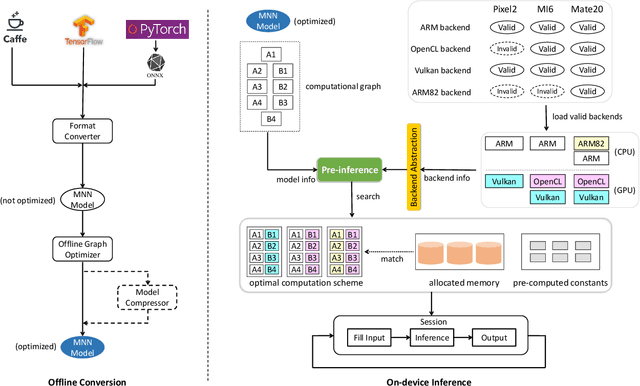
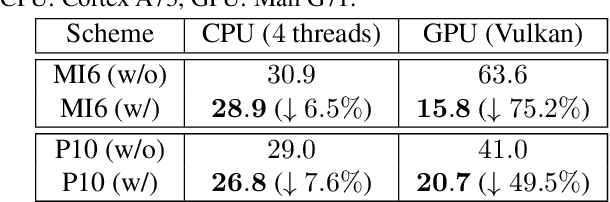
Deploying deep learning models on mobile devices draws more and more attention recently. However, designing an efficient inference engine on devices is under the great challenges of model compatibility, device diversity, and resource limitation. To deal with these challenges, we propose Mobile Neural Network (MNN), a universal and efficient inference engine tailored to mobile applications. In this paper, the contributions of MNN include: (1) presenting a mechanism called pre-inference that manages to conduct runtime optimization; (2)deliveringthorough kernel optimization on operators to achieve optimal computation performance; (3) introducing backend abstraction module which enables hybrid scheduling and keeps the engine lightweight. Extensive benchmark experiments demonstrate that MNN performs favorably against other popular lightweight deep learning frameworks. MNN is available to public at: https://github.com/alibaba/MNN.
Distributed Non-Convex Optimization with Sublinear Speedup under Intermittent Client Availability
Feb 18, 2020
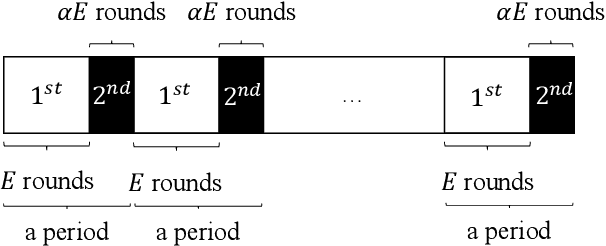
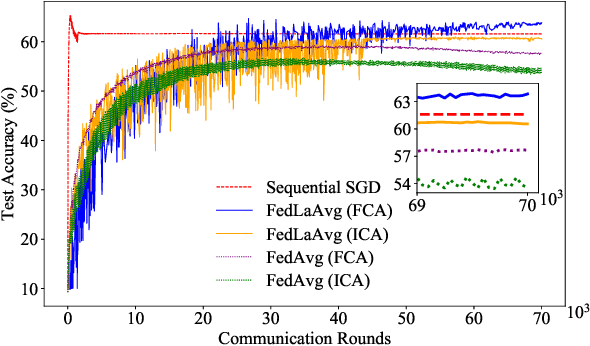

Federated learning is a new distributed machine learning framework, where a bunch of heterogeneous clients collaboratively train a model without sharing training data. In this work, we consider a practical and ubiquitous issue in federated learning: intermittent client availability, where the set of eligible clients may change during the training process. Such an intermittent client availability model would significantly deteriorate the performance of the classical Federated Averaging algorithm (FedAvg for short). We propose a simple distributed non-convex optimization algorithm, called Federated Latest Averaging (FedLaAvg for short), which leverages the latest gradients of all clients, even when the clients are not available, to jointly update the global model in each iteration. Our theoretical analysis shows that FedLaAvg attains the convergence rate of $O(1/(N^{1/4} T^{1/2}))$, achieving a sublinear speedup with respect to the total number of clients. We implement and evaluate FedLaAvg with the CIFAR-10 dataset. The evaluation results demonstrate that FedLaAvg indeed reaches a sublinear speedup and achieves 4.23% higher test accuracy than FedAvg.
Secure Federated Submodel Learning
Nov 11, 2019



Federated learning was proposed with an intriguing vision of achieving collaborative machine learning among numerous clients without uploading their private data to a cloud server. However, the conventional framework requires each client to leverage the full model for learning, which can be prohibitively inefficient for resource-constrained clients and large-scale deep learning tasks. We thus propose a new framework, called federated submodel learning, where clients download only the needed parts of the full model, namely submodels, and then upload the submodel updates. Nevertheless, the "position" of a client's truly required submodel corresponds to her private data, and its disclosure to the cloud server during interactions inevitably breaks the tenet of federated learning. To integrate efficiency and privacy, we have designed a secure federated submodel learning scheme coupled with a private set union protocol as a cornerstone. Our secure scheme features the properties of randomized response, secure aggregation, and Bloom filter, and endows each client with a customized plausible deniability, in terms of local differential privacy, against the position of her desired submodel, thus protecting her private data. We further instantiated our scheme with the e-commerce recommendation scenario in Alibaba, implemented a prototype system, and extensively evaluated its performance over 30-day Taobao user data. The analysis and evaluation results demonstrate the feasibility and scalability of our scheme from model accuracy and convergency, practical communication, computation, and storage overheads, as well as manifest its remarkable advantages over the conventional federated learning framework.