 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTOD-DA: Towards Boosting the Robustness of Task-oriented Dialogue Modeling on Spoken Conversations
Dec 23, 2021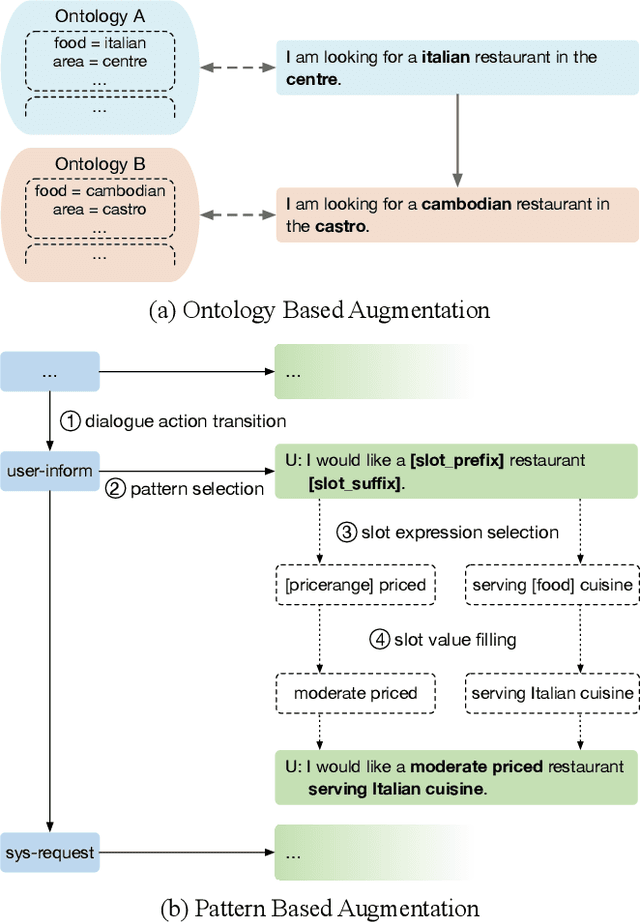
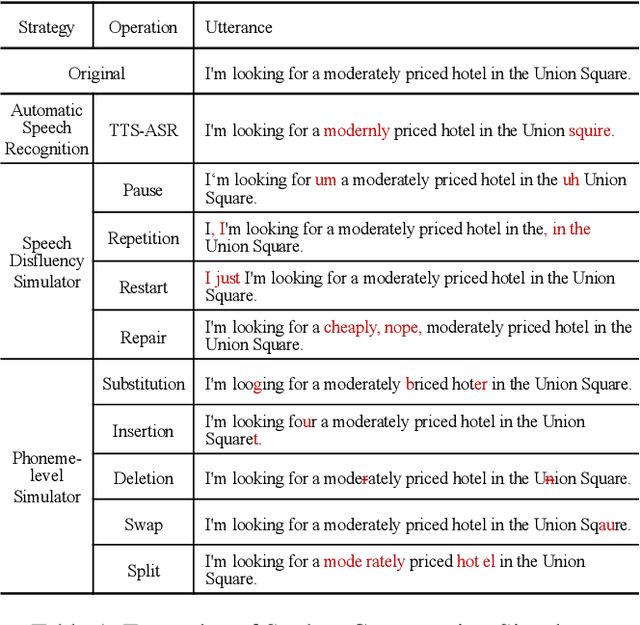
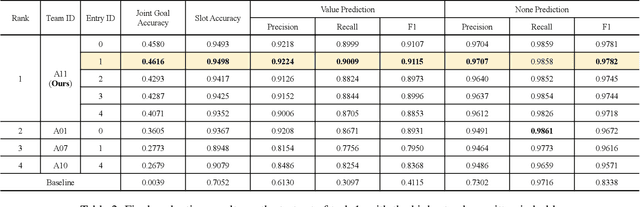
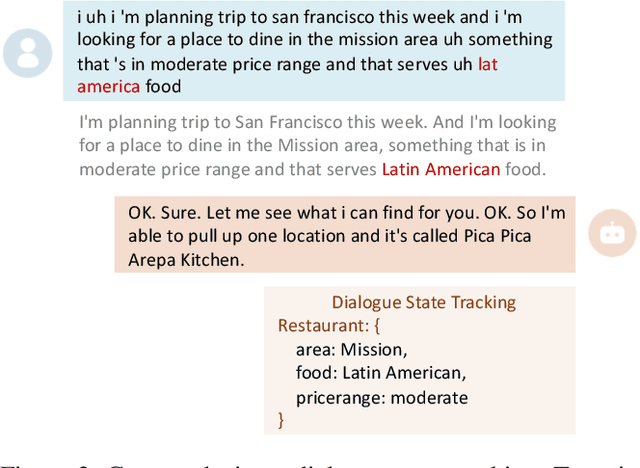
Task-oriented dialogue systems have been plagued by the difficulties of obtaining large-scale and high-quality annotated conversations. Furthermore, most of the publicly available datasets only include written conversations, which are insufficient to reflect actual human behaviors in practical spoken dialogue systems. In this paper, we propose Task-oriented Dialogue Data Augmentation (TOD-DA), a novel model-agnostic data augmentation paradigm to boost the robustness of task-oriented dialogue modeling on spoken conversations. The TOD-DA consists of two modules: 1) Dialogue Enrichment to expand training data on task-oriented conversations for easing data sparsity and 2) Spoken Conversation Simulator to imitate oral style expressions and speech recognition errors in diverse granularities for bridging the gap between written and spoken conversations. With such designs, our approach ranked first in both tasks of DSTC10 Track2, a benchmark for task-oriented dialogue modeling on spoken conversations, demonstrating the superiority and effectiveness of our proposed TOD-DA.
PLATO-XL: Exploring the Large-scale Pre-training of Dialogue Generation
Sep 20, 2021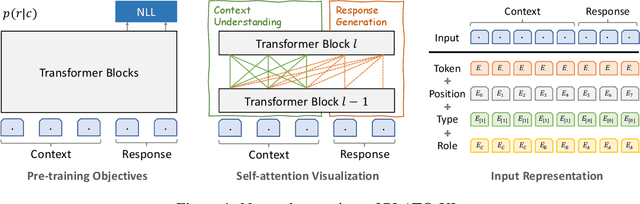
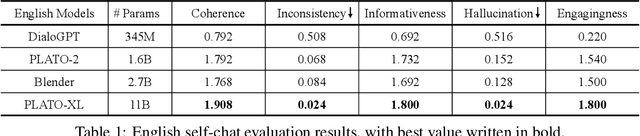

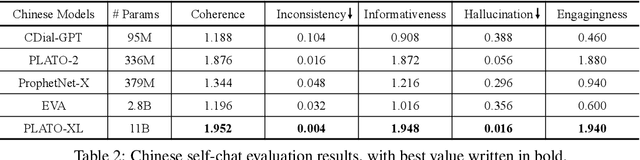
To explore the limit of dialogue generation pre-training, we present the models of PLATO-XL with up to 11 billion parameters, trained on both Chinese and English social media conversations. To train such large models, we adopt the architecture of unified transformer with high computation and parameter efficiency. In addition, we carry out multi-party aware pre-training to better distinguish the characteristic information in social media conversations. With such designs, PLATO-XL successfully achieves superior performances as compared to other approaches in both Chinese and English chitchat. We further explore the capacity of PLATO-XL on other conversational tasks, such as knowledge grounded dialogue and task-oriented conversation. The experimental results indicate that PLATO-XL obtains state-of-the-art results across multiple conversational tasks, verifying its potential as a foundation model of conversational AI.