 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Large-scale Generative Ranking
May 08, 2025



Generative recommendation has recently emerged as a promising paradigm in information retrieval. However, generative ranking systems are still understudied, particularly with respect to their effectiveness and feasibility in large-scale industrial settings. This paper investigates this topic at the ranking stage of Xiaohongshu's Explore Feed, a recommender system that serves hundreds of millions of users. Specifically, we first examine how generative ranking outperforms current industrial recommenders. Through theoretical and empirical analyses, we find that the primary improvement in effectiveness stems from the generative architecture, rather than the training paradigm. To facilitate efficient deployment of generative ranking, we introduce GenRank, a novel generative architecture for ranking. We validate the effectiveness and efficiency of our solution through online A/B experiments. The results show that GenRank achieves significant improvements in user satisfaction with nearly equivalent computational resources compared to the existing production system.
HeterPS: Distributed Deep Learning With Reinforcement Learning Based Scheduling in Heterogeneous Environments
Nov 20, 2021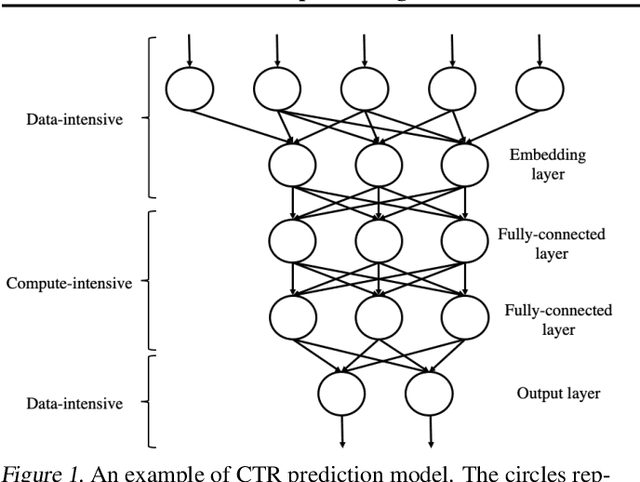

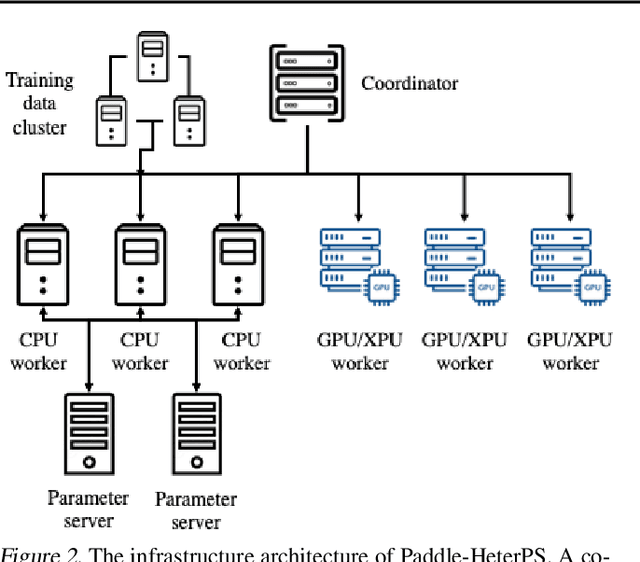
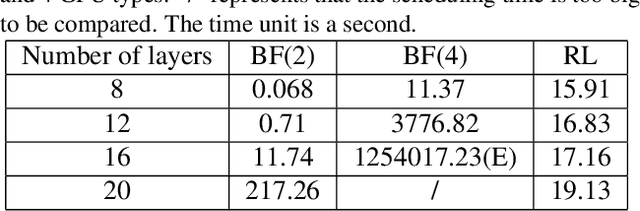
Deep neural networks (DNNs) exploit many layers and a large number of parameters to achieve excellent performance. The training process of DNN models generally handles large-scale input data with many sparse features, which incurs high Input/Output (IO) cost, while some layers are compute-intensive. The training process generally exploits distributed computing resources to reduce training time. In addition, heterogeneous computing resources, e.g., CPUs, GPUs of multiple types, are available for the distributed training process. Thus, the scheduling of multiple layers to diverse computing resources is critical for the training process. To efficiently train a DNN model using the heterogeneous computing resources, we propose a distributed framework, i.e., Paddle-Heterogeneous Parameter Server (Paddle-HeterPS), composed of a distributed architecture and a Reinforcement Learning (RL)-based scheduling method. The advantages of Paddle-HeterPS are three-fold compared with existing frameworks. First, Paddle-HeterPS enables efficient training process of diverse workloads with heterogeneous computing resources. Second, Paddle-HeterPS exploits an RL-based method to efficiently schedule the workload of each layer to appropriate computing resources to minimize the cost while satisfying throughput constraints. Third, Paddle-HeterPS manages data storage and data communication among distributed computing resources. We carry out extensive experiments to show that Paddle-HeterPS significantly outperforms state-of-the-art approaches in terms of throughput (14.5 times higher) and monetary cost (312.3% smaller). The codes of the framework are publicly available at: https://github.com/PaddlePaddle/Paddle.