 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Seek Help: Dynamic Collaboration Between Small and Large Language Models
Apr 20, 2026Large language models (LLMs) offer strong capabilities but raise cost and privacy concerns, whereas small language models (SLMs) facilitate efficient and private local inference yet suffer from limited capacity. To synergize the complementary strengths, we introduce a dynamic collaboration framework, where an SLM learns to proactively decide how to request an LLM during multi-step reasoning, while the LLM provides adaptive feedback instead of acting as a passive tool. We further systematically investigate how collaboration strategies are shaped by SLM and LLM capabilities as well as efficiency and privacy constraints. Evaluation results reveal a distinct scaling effect: stronger SLMs become more self-reliant, while stronger LLMs enable fewer and more informative interactions. In addition, the learned dynamic collaboration strategies significantly outperform static pipelines and standalone inference, and transfer robustly to unseen LLMs.
From Myopic Selection to Long-Horizon Awareness: Sequential LLM Routing for Multi-Turn Dialogue
Apr 14, 2026Multi-turn dialogue is the predominant form of interaction with large language models (LLMs). While LLM routing is effective in single-turn settings, existing methods fail to maximize cumulative performance in multi-turn dialogue due to interaction dynamics and delayed rewards. To address this challenge, we move from myopic, single-turn selection to long-horizon sequential routing for multi-turn dialogue. Accordingly, we propose DialRouter, which first performs MCTS to explore dialogue branches induced by different LLM selections and collect trajectories with high cumulative rewards. DialRouter then learns a lightweight routing policy from search-derived data, augmented with retrieval-based future state approximation, enabling multi-turn routing without online search. Experiments on both open-domain and domain-specific dialogue tasks across diverse candidate sets of both open-source and closed-source LLMs demonstrate that DialRouter significantly outperforms single LLMs and existing routing baselines in task success rate, while achieving a superior performance-cost trade-off when combined with a cost-aware reward.
Bridging Time and Space: Decoupled Spatio-Temporal Alignment for Video Grounding
Apr 09, 2026Spatio-Temporal Video Grounding requires jointly localizing target objects across both temporal and spatial dimensions based on natural language queries, posing fundamental challenges for existing Multimodal Large Language Models (MLLMs). We identify two core challenges: \textit{entangled spatio-temporal alignment}, arising from coupling two heterogeneous sub-tasks within the same autoregressive output space, and \textit{dual-domain visual token redundancy}, where target objects exhibit simultaneous temporal and spatial sparsity, rendering the overwhelming majority of visual tokens irrelevant to the grounding query. To address these, we propose \textbf{Bridge-STG}, an end-to-end framework that decouples temporal and spatial localization while maintaining semantic coherence. While decoupling is the natural solution to this entanglement, it risks creating a semantic gap between the temporal MLLM and the spatial decoder. Bridge-STG resolves this through two pivotal designs: the \textbf{Spatio-Temporal Semantic Bridging (STSB)} mechanism with Explicit Temporal Alignment (ETA) distills the MLLM's temporal reasoning context into enriched bridging queries as a robust semantic interface; and the \textbf{Query-Guided Spatial Localization (QGSL)} module leverages these queries to drive a purpose-built spatial decoder with multi-layer interactive queries and positive/negative frame sampling, jointly eliminating dual-domain visual token redundancy. Extensive experiments across multiple benchmarks demonstrate that Bridge-STG achieves state-of-the-art performance among MLLM-based methods. Bridge-STG improves average m\_vIoU from $26.4$ to $34.3$ on VidSTG and demonstrates strong cross-task transfer across various fine-grained video understanding tasks under a unified multi-task training regime.
FHAvatar: Fast and High-Fidelity Reconstruction of Face-and-Hair Composable 3D Head Avatar from Few Casual Captures
Mar 24, 2026We present FHAvatar, a novel framework for reconstructing 3D Gaussian avatars with composable face and hair components from an arbitrary number of views. Unlike previous approaches that couple facial and hair representations within a unified modeling process, we explicitly decouple two components in texture space by representing the face with planar Gaussians and the hair with strand-based Gaussians. To overcome the limitations of existing methods that rely on dense multi-view captures or costly per-identity optimization, we propose an aggregated transformer backbone to learn geometry-aware cross-view priors and head-hair structural coherence from multi-view datasets, enabling effective and efficient feature extraction and fusion from few casual captures. Extensive quantitative and qualitative experiments demonstrate that FHAvatar achieves state-of-the-art reconstruction quality from only a few observations of new identities within minutes, while supporting real-time animation, convenient hairstyle transfer, and stylized editing, broadening the accessibility and applicability of digital avatar creation.
VIAFormer: Voxel-Image Alignment Transformer for High-Fidelity Voxel Refinement
Jan 21, 2026We propose VIAFormer, a Voxel-Image Alignment Transformer model designed for Multi-view Conditioned Voxel Refinement--the task of repairing incomplete noisy voxels using calibrated multi-view images as guidance. Its effectiveness stems from a synergistic design: an Image Index that provides explicit 3D spatial grounding for 2D image tokens, a Correctional Flow objective that learns a direct voxel-refinement trajectory, and a Hybrid Stream Transformer that enables robust cross-modal fusion. Experiments show that VIAFormer establishes a new state of the art in correcting both severe synthetic corruptions and realistic artifacts on the voxel shape obtained from powerful Vision Foundation Models. Beyond benchmarking, we demonstrate VIAFormer as a practical and reliable bridge in real-world 3D creation pipelines, paving the way for voxel-based methods to thrive in large-model, big-data wave.
Estimating Respiratory Effort from Nocturnal Breathing Sounds for Obstructive Sleep Apnoea Screening
Sep 18, 2025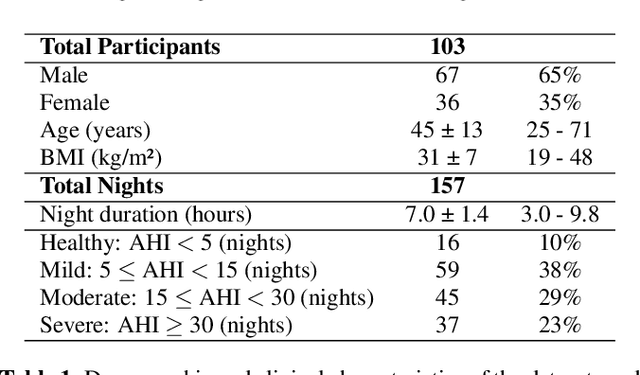
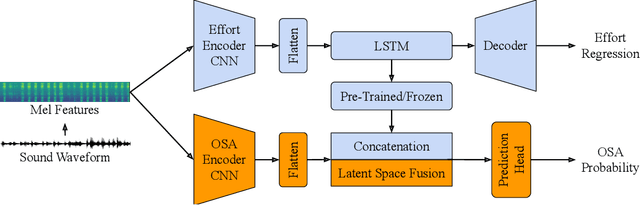

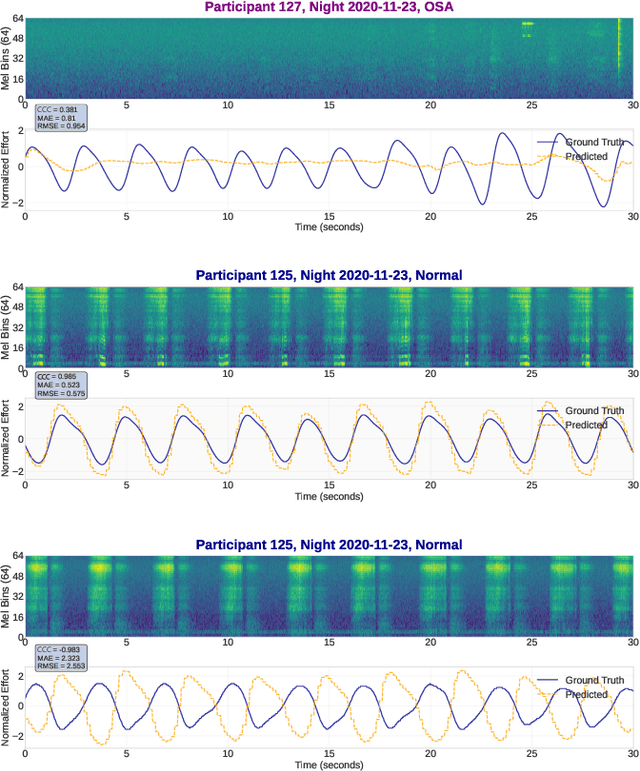
Obstructive sleep apnoea (OSA) is a prevalent condition with significant health consequences, yet many patients remain undiagnosed due to the complexity and cost of over-night polysomnography. Acoustic-based screening provides a scalable alternative, yet performance is limited by environmental noise and the lack of physiological context. Respiratory effort is a key signal used in clinical scoring of OSA events, but current approaches require additional contact sensors that reduce scalability and patient comfort. This paper presents the first study to estimate respiratory effort directly from nocturnal audio, enabling physiological context to be recovered from sound alone. We propose a latent-space fusion framework that integrates the estimated effort embeddings with acoustic features for OSA detection. Using a dataset of 157 nights from 103 participants recorded in home environments, our respiratory effort estimator achieves a concordance correlation coefficient of 0.48, capturing meaningful respiratory dynamics. Fusing effort and audio improves sensitivity and AUC over audio-only baselines, especially at low apnoea-hypopnoea index thresholds. The proposed approach requires only smartphone audio at test time, which enables sensor-free, scalable, and longitudinal OSA monitoring.
Transfer Learning for Paediatric Sleep Apnoea Detection Using Physiology-Guided Acoustic Models
Sep 18, 2025



Paediatric obstructive sleep apnoea (OSA) is clinically significant yet difficult to diagnose, as children poorly tolerate sensor-based polysomnography. Acoustic monitoring provides a non-invasive alternative for home-based OSA screening, but limited paediatric data hinders the development of robust deep learning approaches. This paper proposes a transfer learning framework that adapts acoustic models pretrained on adult sleep data to paediatric OSA detection, incorporating SpO2-based desaturation patterns to enhance model training. Using a large adult sleep dataset (157 nights) and a smaller paediatric dataset (15 nights), we systematically evaluate (i) single- versus multi-task learning, (ii) encoder freezing versus full fine-tuning, and (iii) the impact of delaying SpO2 labels to better align them with the acoustics and capture physiologically meaningful features. Results show that fine-tuning with SpO2 integration consistently improves paediatric OSA detection compared with baseline models without adaptation. These findings demonstrate the feasibility of transfer learning for home-based OSA screening in children and offer its potential clinical value for early diagnosis.
Query Routing for Retrieval-Augmented Language Models
May 29, 2025Retrieval-Augmented Generation (RAG) significantly improves the performance of Large Language Models (LLMs) on knowledge-intensive tasks. However, varying response quality across LLMs under RAG necessitates intelligent routing mechanisms, which select the most suitable model for each query from multiple retrieval-augmented LLMs via a dedicated router model. We observe that external documents dynamically affect LLMs' ability to answer queries, while existing routing methods, which rely on static parametric knowledge representations, exhibit suboptimal performance in RAG scenarios. To address this, we formally define the new retrieval-augmented LLM routing problem, incorporating the influence of retrieved documents into the routing framework. We propose RAGRouter, a RAG-aware routing design, which leverages document embeddings and RAG capability embeddings with contrastive learning to capture knowledge representation shifts and enable informed routing decisions. Extensive experiments on diverse knowledge-intensive tasks and retrieval settings show that RAGRouter outperforms the best individual LLM by 3.61% on average and existing routing methods by 3.29%-9.33%. With an extended score-threshold-based mechanism, it also achieves strong performance-efficiency trade-offs under low-latency constraints.
Automated Privacy Information Annotation in Large Language Model Interactions
May 27, 2025Users interacting with large language models (LLMs) under their real identifiers often unknowingly risk disclosing private information. Automatically notifying users whether their queries leak privacy and which phrases leak what private information has therefore become a practical need. Existing privacy detection methods, however, were designed for different objectives and application scenarios, typically tagging personally identifiable information (PII) in anonymous content. In this work, to support the development and evaluation of privacy detection models for LLM interactions that are deployable on local user devices, we construct a large-scale multilingual dataset with 249K user queries and 154K annotated privacy phrases. In particular, we build an automated privacy annotation pipeline with cloud-based strong LLMs to automatically extract privacy phrases from dialogue datasets and annotate leaked information. We also design evaluation metrics at the levels of privacy leakage, extracted privacy phrase, and privacy information. We further establish baseline methods using light-weight LLMs with both tuning-free and tuning-based methods, and report a comprehensive evaluation of their performance. Evaluation results reveal a gap between current performance and the requirements of real-world LLM applications, motivating future research into more effective local privacy detection methods grounded in our dataset.
Collaborative Learning of On-Device Small Model and Cloud-Based Large Model: Advances and Future Directions
Apr 17, 2025



The conventional cloud-based large model learning framework is increasingly constrained by latency, cost, personalization, and privacy concerns. In this survey, we explore an emerging paradigm: collaborative learning between on-device small model and cloud-based large model, which promises low-latency, cost-efficient, and personalized intelligent services while preserving user privacy. We provide a comprehensive review across hardware, system, algorithm, and application layers. At each layer, we summarize key problems and recent advances from both academia and industry. In particular, we categorize collaboration algorithms into data-based, feature-based, and parameter-based frameworks. We also review publicly available datasets and evaluation metrics with user-level or device-level consideration tailored to collaborative learning settings. We further highlight real-world deployments, ranging from recommender systems and mobile livestreaming to personal intelligent assistants. We finally point out open research directions to guide future development in this rapidly evolving field.