 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing Feature Extraction for On-device Model Inference with User Behavior Sequences
Mar 23, 2026Machine learning models are widely integrated into modern mobile apps to analyze user behaviors and deliver personalized services. Ensuring low-latency on-device model execution is critical for maintaining high-quality user experiences. While prior research has primarily focused on accelerating model inference with given input features, we identify an overlooked bottleneck in real-world on-device model execution pipelines: extracting input features from raw application logs. In this work, we explore a new direction of feature extraction optimization by analyzing and eliminating redundant extraction operations across different model features and consecutive model inferences. We then introduce AutoFeature, an automated feature extraction engine designed to accelerate on-device feature extraction process without compromising model inference accuracy. AutoFeature comprises three core designs: (1) graph abstraction to formulate the extraction workflows of different input features as one directed acyclic graph, (2) graph optimization to identify and fuse redundant operation nodes across different features within the graph; (3) efficient caching to minimize operations on overlapping raw data between consecutive model inferences. We implement a system prototype of AutoFeature and integrate it into five industrial mobile services spanning search, video and e-commerce domains. Online evaluations show that AutoFeature reduces end-to-end on-device model execution latency by 1.33x-3.93x during daytime and 1.43x-4.53x at night.
MNN: A Universal and Efficient Inference Engine
Feb 27, 2020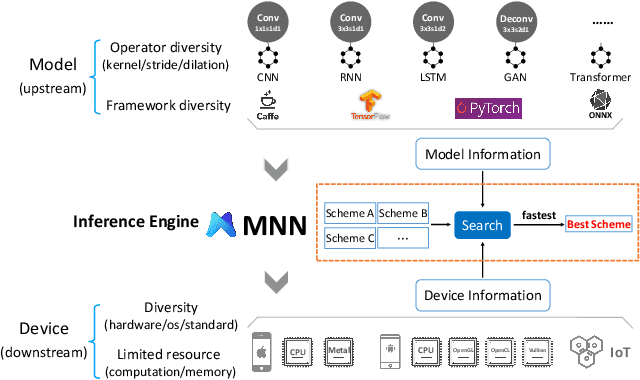
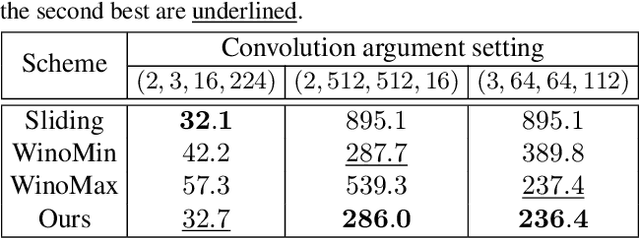
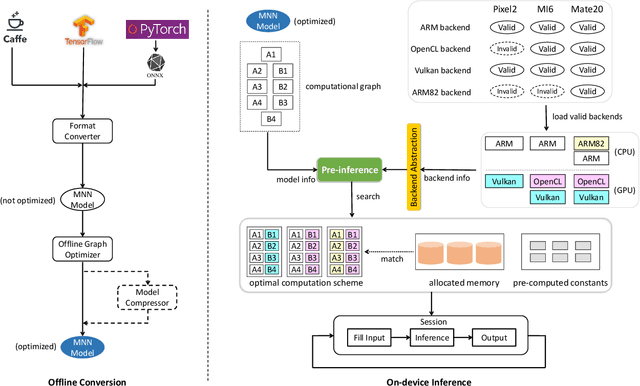
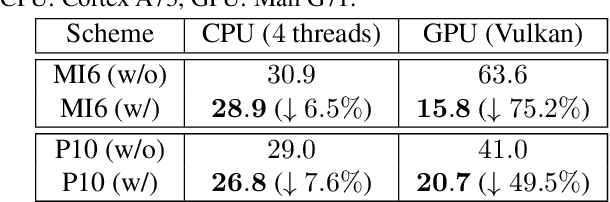
Deploying deep learning models on mobile devices draws more and more attention recently. However, designing an efficient inference engine on devices is under the great challenges of model compatibility, device diversity, and resource limitation. To deal with these challenges, we propose Mobile Neural Network (MNN), a universal and efficient inference engine tailored to mobile applications. In this paper, the contributions of MNN include: (1) presenting a mechanism called pre-inference that manages to conduct runtime optimization; (2)deliveringthorough kernel optimization on operators to achieve optimal computation performance; (3) introducing backend abstraction module which enables hybrid scheduling and keeps the engine lightweight. Extensive benchmark experiments demonstrate that MNN performs favorably against other popular lightweight deep learning frameworks. MNN is available to public at: https://github.com/alibaba/MNN.