 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideoSEG-O3: A Multi-turn Reinforcement Learning Framework for Reasoning Video Object Segmentation
Jun 05, 2026Reasoning Video Object Segmentation (RVOS) demands a sophisticated integration of temporal dynamics, spatial details, and linguistic reasoning to achieve precise pixel-level localization. Existing methods are limited to reasoning over fixed initial inputs and lack the capacity to actively acquire further visual evidence, which is often essential for resolving complex references in long or intricate videos. To address this, we propose \textbf{VideoSEG-O3}, the first multi-turn reinforcement learning framework for RVOS that emulates the human \textit{``coarse-to-fine''} cognitive process. It employs a \textit{multi-turn temporal-spatial chain-of-thought} to capture fine-grained details by iteratively pinpointing critical intervals and keyframes. Additionally, to enable the policy to perceive segmentation quality beyond mere text probability of \texttt{[SEG]} during the RL stage, we introduce \textit{SEG-aware logit calibration}, which integrates pixel-wise segmentation feedback directly into the token-level logits. Furthermore, we design a \textit{decoupled thinking trace} to hierarchically decompose the reasoning process into temporal, spatial, and linguistic dimensions, and construct \textbf{VTS-CoT}, a specialized cold-start dataset featuring comprehensive reasoning trajectories. The code and models will be released at https://github.com/Dmmm1997/VideoSEG-O3.
ERNIE-ViLG: Unified Generative Pre-training for Bidirectional Vision-Language Generation
Dec 31, 2021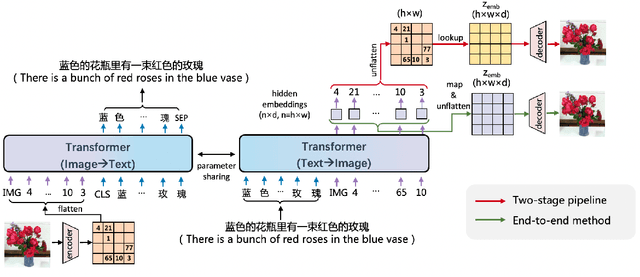
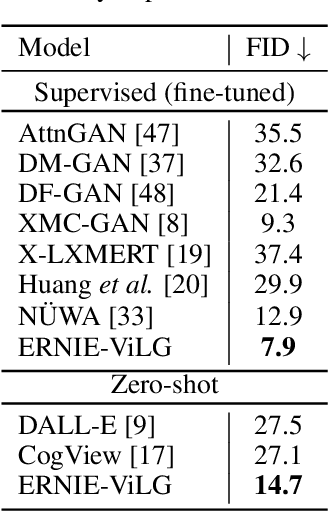
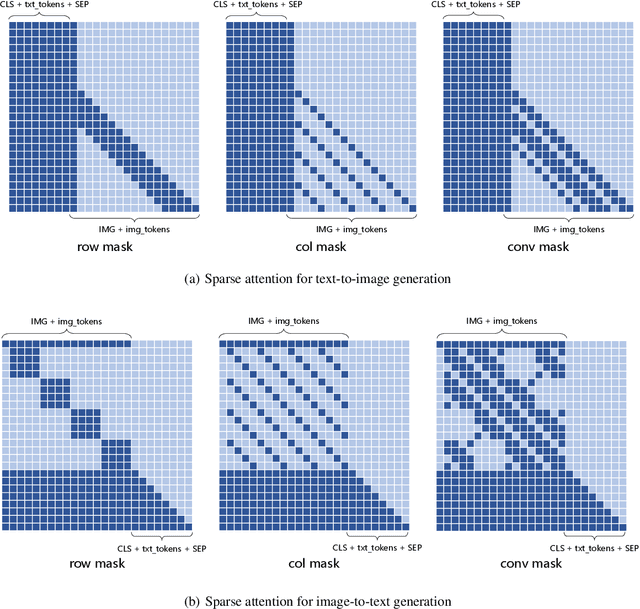

Conventional methods for the image-text generation tasks mainly tackle the naturally bidirectional generation tasks separately, focusing on designing task-specific frameworks to improve the quality and fidelity of the generated samples. Recently, Vision-Language Pre-training models have greatly improved the performance of the image-to-text generation tasks, but large-scale pre-training models for text-to-image synthesis task are still under-developed. In this paper, we propose ERNIE-ViLG, a unified generative pre-training framework for bidirectional image-text generation with transformer model. Based on the image quantization models, we formulate both image generation and text generation as autoregressive generative tasks conditioned on the text/image input. The bidirectional image-text generative modeling eases the semantic alignments across vision and language. For the text-to-image generation process, we further propose an end-to-end training method to jointly learn the visual sequence generator and the image reconstructor. To explore the landscape of large-scale pre-training for bidirectional text-image generation, we train a 10-billion parameter ERNIE-ViLG model on a large-scale dataset of 145 million (Chinese) image-text pairs which achieves state-of-the-art performance for both text-to-image and image-to-text tasks, obtaining an FID of 7.9 on MS-COCO for text-to-image synthesis and best results on COCO-CN and AIC-ICC for image captioning.