 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbabilistic Predictions of Process-Induced Deformation in Carbon/Epoxy Composites Using a Deep Operator Network
Dec 18, 2025



Fiber reinforcement and polymer matrix respond differently to manufacturing conditions due to mismatch in coefficient of thermal expansion and matrix shrinkage during curing of thermosets. These heterogeneities generate residual stresses over multiple length scales, whose partial release leads to process-induced deformation (PID), requiring accurate prediction and mitigation via optimized non-isothermal cure cycles. This study considers a unidirectional AS4 carbon fiber/amine bi-functional epoxy prepreg and models PID using a two-mechanism framework that accounts for thermal expansion/shrinkage and cure shrinkage. The model is validated against manufacturing trials to identify initial and boundary conditions, then used to generate PID responses for a diverse set of non-isothermal cure cycles (time-temperature profiles). Building on this physics-based foundation, we develop a data-driven surrogate based on Deep Operator Networks (DeepONets). A DeepONet is trained on a dataset combining high-fidelity simulations with targeted experimental measurements of PID. We extend this to a Feature-wise Linear Modulation (FiLM) DeepONet, where branch-network features are modulated by external parameters, including the initial degree of cure, enabling prediction of time histories of degree of cure, viscosity, and deformation. Because experimental data are available only at limited time instances (for example, final deformation), we use transfer learning: simulation-trained trunk and branch networks are fixed and only the final layer is updated using measured final deformation. Finally, we augment the framework with Ensemble Kalman Inversion (EKI) to quantify uncertainty under experimental conditions and to support optimization of cure schedules for reduced PID in composites.
FutureX: Enhance End-to-End Autonomous Driving via Latent Chain-of-Thought World Model
Dec 12, 2025



In autonomous driving, end-to-end planners learn scene representations from raw sensor data and utilize them to generate a motion plan or control actions. However, exclusive reliance on the current scene for motion planning may result in suboptimal responses in highly dynamic traffic environments where ego actions further alter the future scene. To model the evolution of future scenes, we leverage the World Model to represent how the ego vehicle and its environment interact and change over time, which entails complex reasoning. The Chain of Thought (CoT) offers a promising solution by forecasting a sequence of future thoughts that subsequently guide trajectory refinement. In this paper, we propose FutureX, a CoT-driven pipeline that enhances end-to-end planners to perform complex motion planning via future scene latent reasoning and trajectory refinement. Specifically, the Auto-think Switch examines the current scene and decides whether additional reasoning is required to yield a higher-quality motion plan. Once FutureX enters the Thinking mode, the Latent World Model conducts a CoT-guided rollout to predict future scene representation, enabling the Summarizer Module to further refine the motion plan. Otherwise, FutureX operates in an Instant mode to generate motion plans in a forward pass for relatively simple scenes. Extensive experiments demonstrate that FutureX enhances existing methods by producing more rational motion plans and fewer collisions without compromising efficiency, thereby achieving substantial overall performance gains, e.g., 6.2 PDMS improvement for TransFuser on NAVSIM. Code will be released.
Distribution Matching Distillation Meets Reinforcement Learning
Nov 19, 2025Distribution Matching Distillation (DMD) distills a pre-trained multi-step diffusion model to a few-step one to improve inference efficiency. However, the performance of the latter is often capped by the former. To circumvent this dilemma, we propose DMDR, a novel framework that combines Reinforcement Learning (RL) techniques into the distillation process. We show that for the RL of the few-step generator, the DMD loss itself is a more effective regularization compared to the traditional ones. In turn, RL can help to guide the mode coverage process in DMD more effectively. These allow us to unlock the capacity of the few-step generator by conducting distillation and RL simultaneously. Meanwhile, we design the dynamic distribution guidance and dynamic renoise sampling training strategies to improve the initial distillation process. The experiments demonstrate that DMDR can achieve leading visual quality, prompt coherence among few-step methods, and even exhibit performance that exceeds the multi-step teacher.
MalRAG: A Retrieval-Augmented LLM Framework for Open-set Malicious Traffic Identification
Nov 18, 2025Fine-grained identification of IDS-flagged suspicious traffic is crucial in cybersecurity. In practice, cyber threats evolve continuously, making the discovery of novel malicious traffic a critical necessity as well as the identification of known classes. Recent studies have advanced this goal with deep models, but they often rely on task-specific architectures that limit transferability and require per-dataset tuning. In this paper we introduce MalRAG, the first LLM driven retrieval-augmented framework for open-set malicious traffic identification. MalRAG freezes the LLM and operates via comprehensive traffic knowledge construction, adaptive retrieval, and prompt engineering. Concretely, we construct a multi-view traffic database by mining prior malicious traffic from content, structural, and temporal perspectives. Furthermore, we introduce a Coverage-Enhanced Retrieval Algorithm that queries across these views to assemble the most probable candidates, thereby improving the inclusion of correct evidence. We then employ Traffic-Aware Adaptive Pruning to select a variable subset of these candidates based on traffic-aware similarity scores, suppressing incorrect matches and yielding reliable retrieved evidence. Moreover, we develop a suite of guidance prompts where task instruction, evidence referencing, and decision guidance are integrated with the retrieved evidence to improve LLM performance. Across diverse real-world datasets and settings, MalRAG delivers state-of-the-art results in both fine-grained identification of known classes and novel malicious traffic discovery. Ablation and deep-dive analyses further show that MalRAG effective leverages LLM capabilities yet achieves open-set malicious traffic identification without relying on a specific LLM.
Reconstruction of three-dimensional shapes of normal and disease-related erythrocytes from partial observations using multi-fidelity neural networks
Nov 18, 2025



Reconstruction of 3D erythrocyte or red blood cell (RBC) morphology from partial observations, such as microscope images, is essential for understanding the physiology of RBC aging and the pathology of various RBC disorders. In this study, we propose a multi-fidelity neural network (MFNN) approach to fuse high-fidelity cross-sections of an RBC, with a morphologically similar low-fidelity reference 3D RBC shape to recover its full 3D surface. The MFNN predictor combines a convolutional neural network trained on low-fidelity reference RBC data with a feedforward neural network that captures nonlinear morphological correlations, and augments training with surface area and volume constraints for regularization in the low-fidelity branch. This approach is theoretically grounded by a topological homeomorphism between a sphere and 3D RBC surfaces, with training data generated by dissipative particle dynamics simulations of stomatocyte-discocyte-echinocyte transformation. Benchmarking across diverse RBC shapes observed in normal and aged populations, our results show that the MFNN predictor can reconstruct complex RBC morphologies with over 95% coordinate accuracy when provided with at least two orthogonal cross-sections. It is observed that informative oblique cross-sections intersecting spicule tips of echinocytes improve both local and global feature reconstruction, highlighting the value of feature-aware sampling. Our study further evaluates the influence of sampling strategies, shape dissimilarity, and noise, showing enhanced robustness under physically constrained training. Altogether, these results demonstrate the capability of MFNN to reconstruct the 3D shape of normal and aged RBCs from partial cross-sections as observed in conventional microscope images, which could facilitate the quantitative analysis of RBC morphological parameters in normal and disease-related RBC samples.
AffordBot: 3D Fine-grained Embodied Reasoning via Multimodal Large Language Models
Nov 13, 2025



Effective human-agent collaboration in physical environments requires understanding not only what to act upon, but also where the actionable elements are and how to interact with them. Existing approaches often operate at the object level or disjointedly handle fine-grained affordance reasoning, lacking coherent, instruction-driven grounding and reasoning. In this work, we introduce a new task: Fine-grained 3D Embodied Reasoning, which requires an agent to predict, for each referenced affordance element in a 3D scene, a structured triplet comprising its spatial location, motion type, and motion axis, based on a task instruction. To solve this task, we propose AffordBot, a novel framework that integrates Multimodal Large Language Models (MLLMs) with a tailored chain-of-thought (CoT) reasoning paradigm. To bridge the gap between 3D input and 2D-compatible MLLMs, we render surround-view images of the scene and project 3D element candidates into these views, forming a rich visual representation aligned with the scene geometry. Our CoT pipeline begins with an active perception stage, prompting the MLLM to select the most informative viewpoint based on the instruction, before proceeding with step-by-step reasoning to localize affordance elements and infer plausible interaction motions. Evaluated on the SceneFun3D dataset, AffordBot achieves state-of-the-art performance, demonstrating strong generalization and physically grounded reasoning with only 3D point cloud input and MLLMs.
Composition-Incremental Learning for Compositional Generalization
Nov 12, 2025Compositional generalization has achieved substantial progress in computer vision on pre-collected training data. Nonetheless, real-world data continually emerges, with possible compositions being nearly infinite, long-tailed, and not entirely visible. Thus, an ideal model is supposed to gradually improve the capability of compositional generalization in an incremental manner. In this paper, we explore Composition-Incremental Learning for Compositional Generalization (CompIL) in the context of the compositional zero-shot learning (CZSL) task, where models need to continually learn new compositions, intending to improve their compositional generalization capability progressively. To quantitatively evaluate CompIL, we develop a benchmark construction pipeline leveraging existing datasets, yielding MIT-States-CompIL and C-GQA-CompIL. Furthermore, we propose a pseudo-replay framework utilizing a visual synthesizer to synthesize visual representations of learned compositions and a linguistic primitive distillation mechanism to maintain aligned primitive representations across the learning process. Extensive experiments demonstrate the effectiveness of the proposed framework.
HyPerNav: Hybrid Perception for Object-Oriented Navigation in Unknown Environment
Oct 27, 2025



Objective-oriented navigation(ObjNav) enables robot to navigate to target object directly and autonomously in an unknown environment. Effective perception in navigation in unknown environment is critical for autonomous robots. While egocentric observations from RGB-D sensors provide abundant local information, real-time top-down maps offer valuable global context for ObjNav. Nevertheless, the majority of existing studies focus on a single source, seldom integrating these two complementary perceptual modalities, despite the fact that humans naturally attend to both. With the rapid advancement of Vision-Language Models(VLMs), we propose Hybrid Perception Navigation (HyPerNav), leveraging VLMs' strong reasoning and vision-language understanding capabilities to jointly perceive both local and global information to enhance the effectiveness and intelligence of navigation in unknown environments. In both massive simulation evaluation and real-world validation, our methods achieved state-of-the-art performance against popular baselines. Benefiting from hybrid perception approach, our method captures richer cues and finds the objects more effectively, by simultaneously leveraging information understanding from egocentric observations and the top-down map. Our ablation study further proved that either of the hybrid perception contributes to the navigation performance.
Posterior Collapse as a Phase Transition in Variational Autoencoders
Oct 02, 2025We investigate the phenomenon of posterior collapse in variational autoencoders (VAEs) from the perspective of statistical physics, and reveal that it constitutes a phase transition governed jointly by data structure and model hyper-parameters. By analyzing the stability of the trivial solution associated with posterior collapse, we identify a critical hyper-parameter threshold. This critical boundary, separating meaningful latent inference from collapse, is characterized by a discontinuity in the KL divergence between the approximate posterior and the prior distribution. We validate this critical behavior on both synthetic and real-world datasets, confirming the existence of a phase transition. Our results demonstrate that posterior collapse is not merely an optimization failure, but rather an emerging phase transition arising from the interplay between data structure and variational constraints. This perspective offers new insights into the trainability and representational capacity of deep generative models.
InfiR2: A Comprehensive FP8 Training Recipe for Reasoning-Enhanced Language Models
Sep 26, 2025


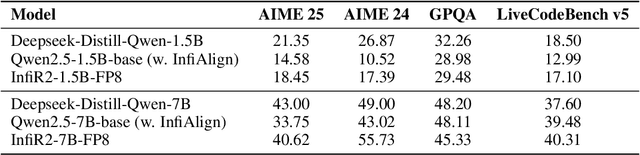
The immense computational cost of training Large Language Models (LLMs) presents a major barrier to innovation. While FP8 training offers a promising solution with significant theoretical efficiency gains, its widespread adoption has been hindered by the lack of a comprehensive, open-source training recipe. To bridge this gap, we introduce an end-to-end FP8 training recipe that seamlessly integrates continual pre-training and supervised fine-tuning. Our methodology employs a fine-grained, hybrid-granularity quantization strategy to maintain numerical fidelity while maximizing computational efficiency. Through extensive experiments, including the continue pre-training of models on a 160B-token corpus, we demonstrate that our recipe is not only remarkably stable but also essentially lossless, achieving performance on par with the BF16 baseline across a suite of reasoning benchmarks. Crucially, this is achieved with substantial efficiency improvements, including up to a 22% reduction in training time, a 14% decrease in peak memory usage, and a 19% increase in throughput. Our results establish FP8 as a practical and robust alternative to BF16, and we will release the accompanying code to further democratize large-scale model training.