 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Self-Evaluation for Diffusion Language Models via Sequence Regeneration
Mar 03, 2026Diffusion large language models (dLLMs) have recently attracted significant attention for their ability to enhance diversity, controllability, and parallelism. However, their non-sequential, bidirectionally masked generation makes quality assessment difficult, underscoring the need for effective self-evaluation. In this work, we propose DiSE, a simple yet effective self-evaluation confidence quantification method for dLLMs. DiSE quantifies confidence by computing the probability of regenerating the tokens in the entire generated sequence, given the full context. This method enables more efficient and reliable quality assessment by leveraging token regeneration probabilities, facilitating both likelihood estimation and robust uncertainty quantification. Building upon DiSE, we further introduce a flexible-length generation framework, which adaptively controls the sequence length based on the model's self-assessment of its own output. We analyze and validate the feasibility of DiSE from the perspective of dLLM generalization, and empirically demonstrate that DiSE is positively correlated with both semantic coherence and answer accuracy. Extensive experiments on likelihood evaluation, uncertainty quantification, and flexible-length generation further confirm the effectiveness of the proposed DiSE.
Differentiate-and-Inject: Enhancing VLAs via Functional Differentiation Induced by In-Parameter Structural Reasoning
Feb 07, 2026As robots are expected to perform increasingly diverse tasks, they must understand not only low-level actions but also the higher-level structure that determines how a task should unfold. Existing vision-language-action (VLA) models struggle with this form of task-level reasoning. They either depend on prompt-based in-context decomposition, which is unstable and sensitive to linguistic variations, or end-to-end long-horizon training, which requires large-scale demonstrations and entangles task-level reasoning with low-level control. We present in-parameter structured task reasoning (iSTAR), a framework for enhancing VLA models via functional differentiation induced by in-parameter structural reasoning. Instead of treating VLAs as monolithic policies, iSTAR embeds task-level semantic structure directly into model parameters, enabling differentiated task-level inference without external planners or handcrafted prompt inputs. This injected structure takes the form of implicit dynamic scene-graph knowledge that captures object relations, subtask semantics, and task-level dependencies in parameter space. Across diverse manipulation benchmarks, iSTAR achieves more reliable task decompositions and higher success rates than both in-context and end-to-end VLA baselines, demonstrating the effectiveness of parameter-space structural reasoning for functional differentiation and improved generalization across task variations.
Beyond Hard Masks: Progressive Token Evolution for Diffusion Language Models
Jan 12, 2026Diffusion Language Models (DLMs) offer a promising alternative for language modeling by enabling parallel decoding through iterative refinement. However, most DLMs rely on hard binary masking and discrete token assignments, which hinder the revision of early decisions and underutilize intermediate probabilistic representations. In this paper, we propose EvoToken-DLM, a novel diffusion-based language modeling approach that replaces hard binary masks with evolving soft token distributions. EvoToken-DLM enables a progressive transition from masked states to discrete outputs, supporting revisable decoding. To effectively support this evolution, we introduce continuous trajectory supervision, which aligns training objectives with iterative probabilistic updates. Extensive experiments across multiple benchmarks show that EvoToken-DLM consistently achieves superior performance, outperforming strong diffusion-based and masked DLM baselines. Project webpage: https://aim-uofa.github.io/EvoTokenDLM.
Preserving Source Video Realism: High-Fidelity Face Swapping for Cinematic Quality
Dec 08, 2025Video face swapping is crucial in film and entertainment production, where achieving high fidelity and temporal consistency over long and complex video sequences remains a significant challenge. Inspired by recent advances in reference-guided image editing, we explore whether rich visual attributes from source videos can be similarly leveraged to enhance both fidelity and temporal coherence in video face swapping. Building on this insight, this work presents LivingSwap, the first video reference guided face swapping model. Our approach employs keyframes as conditioning signals to inject the target identity, enabling flexible and controllable editing. By combining keyframe conditioning with video reference guidance, the model performs temporal stitching to ensure stable identity preservation and high-fidelity reconstruction across long video sequences. To address the scarcity of data for reference-guided training, we construct a paired face-swapping dataset, Face2Face, and further reverse the data pairs to ensure reliable ground-truth supervision. Extensive experiments demonstrate that our method achieves state-of-the-art results, seamlessly integrating the target identity with the source video's expressions, lighting, and motion, while significantly reducing manual effort in production workflows. Project webpage: https://aim-uofa.github.io/LivingSwap
Composition-Incremental Learning for Compositional Generalization
Nov 12, 2025Compositional generalization has achieved substantial progress in computer vision on pre-collected training data. Nonetheless, real-world data continually emerges, with possible compositions being nearly infinite, long-tailed, and not entirely visible. Thus, an ideal model is supposed to gradually improve the capability of compositional generalization in an incremental manner. In this paper, we explore Composition-Incremental Learning for Compositional Generalization (CompIL) in the context of the compositional zero-shot learning (CZSL) task, where models need to continually learn new compositions, intending to improve their compositional generalization capability progressively. To quantitatively evaluate CompIL, we develop a benchmark construction pipeline leveraging existing datasets, yielding MIT-States-CompIL and C-GQA-CompIL. Furthermore, we propose a pseudo-replay framework utilizing a visual synthesizer to synthesize visual representations of learned compositions and a linguistic primitive distillation mechanism to maintain aligned primitive representations across the learning process. Extensive experiments demonstrate the effectiveness of the proposed framework.
Evolutionary Profiles for Protein Fitness Prediction
Oct 08, 2025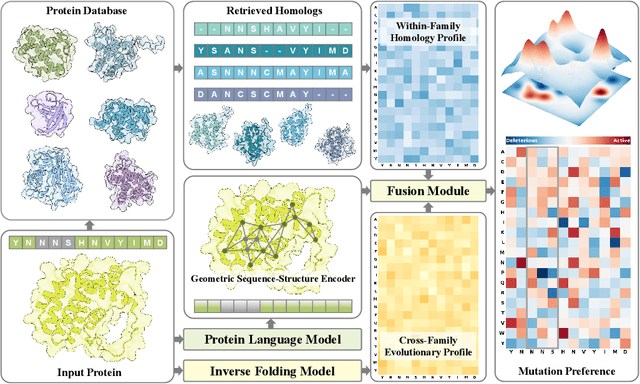
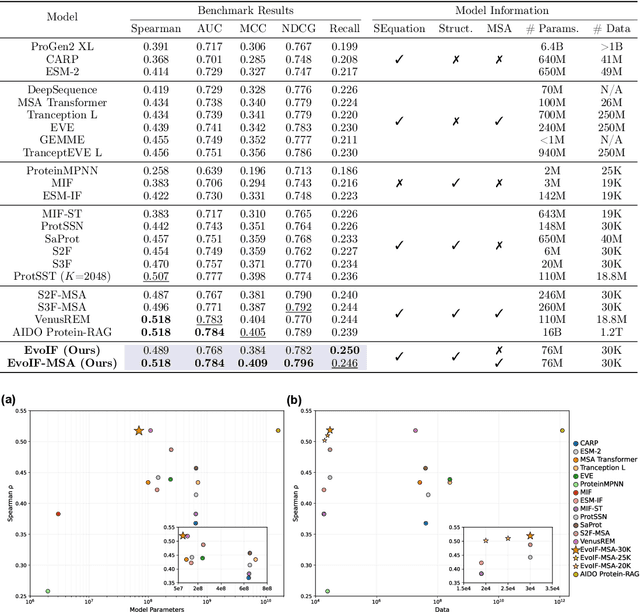
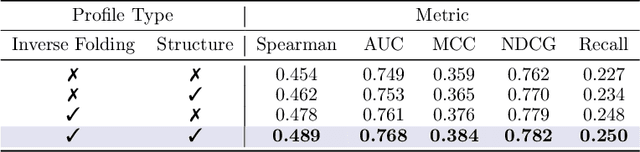
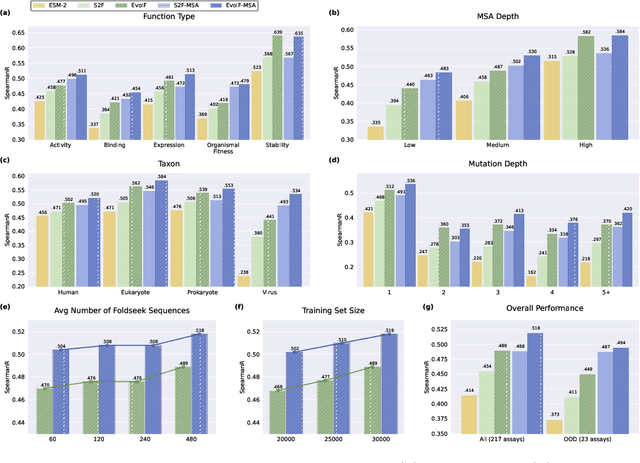
Predicting the fitness impact of mutations is central to protein engineering but constrained by limited assays relative to the size of sequence space. Protein language models (pLMs) trained with masked language modeling (MLM) exhibit strong zero-shot fitness prediction; we provide a unifying view by interpreting natural evolution as implicit reward maximization and MLM as inverse reinforcement learning (IRL), in which extant sequences act as expert demonstrations and pLM log-odds serve as fitness estimates. Building on this perspective, we introduce EvoIF, a lightweight model that integrates two complementary sources of evolutionary signal: (i) within-family profiles from retrieved homologs and (ii) cross-family structural-evolutionary constraints distilled from inverse folding logits. EvoIF fuses sequence-structure representations with these profiles via a compact transition block, yielding calibrated probabilities for log-odds scoring. On ProteinGym (217 mutational assays; >2.5M mutants), EvoIF and its MSA-enabled variant achieve state-of-the-art or competitive performance while using only 0.15% of the training data and fewer parameters than recent large models. Ablations confirm that within-family and cross-family profiles are complementary, improving robustness across function types, MSA depths, taxa, and mutation depths. The codes will be made publicly available at https://github.com/aim-uofa/EvoIF.
Learning by Imagining: Debiased Feature Augmentation for Compositional Zero-Shot Learning
Sep 16, 2025Compositional Zero-Shot Learning (CZSL) aims to recognize unseen attribute-object compositions by learning prior knowledge of seen primitives, \textit{i.e.}, attributes and objects. Learning generalizable compositional representations in CZSL remains challenging due to the entangled nature of attributes and objects as well as the prevalence of long-tailed distributions in real-world data. Inspired by neuroscientific findings that imagination and perception share similar neural processes, we propose a novel approach called Debiased Feature Augmentation (DeFA) to address these challenges. The proposed DeFA integrates a disentangle-and-reconstruct framework for feature augmentation with a debiasing strategy. DeFA explicitly leverages the prior knowledge of seen attributes and objects by synthesizing high-fidelity composition features to support compositional generalization. Extensive experiments on three widely used datasets demonstrate that DeFA achieves state-of-the-art performance in both \textit{closed-world} and \textit{open-world} settings.
Time Is a Feature: Exploiting Temporal Dynamics in Diffusion Language Models
Aug 12, 2025Diffusion large language models (dLLMs) generate text through iterative denoising, yet current decoding strategies discard rich intermediate predictions in favor of the final output. Our work here reveals a critical phenomenon, temporal oscillation, where correct answers often emerge in the middle process, but are overwritten in later denoising steps. To address this issue, we introduce two complementary methods that exploit temporal consistency: 1) Temporal Self-Consistency Voting, a training-free, test-time decoding strategy that aggregates predictions across denoising steps to select the most consistent output; and 2) a post-training method termed Temporal Consistency Reinforcement, which uses Temporal Semantic Entropy (TSE), a measure of semantic stability across intermediate predictions, as a reward signal to encourage stable generations. Empirical results across multiple benchmarks demonstrate the effectiveness of our approach. Using the negative TSE reward alone, we observe a remarkable average improvement of 24.7% on the Countdown dataset over an existing dLLM. Combined with the accuracy reward, we achieve absolute gains of 2.0% on GSM8K, 4.3% on MATH500, 6.6% on SVAMP, and 25.3% on Countdown, respectively. Our findings underscore the untapped potential of temporal dynamics in dLLMs and offer two simple yet effective tools to harness them.
DREAM: Disentangling Risks to Enhance Safety Alignment in Multimodal Large Language Models
Apr 25, 2025



Multimodal Large Language Models (MLLMs) pose unique safety challenges due to their integration of visual and textual data, thereby introducing new dimensions of potential attacks and complex risk combinations. In this paper, we begin with a detailed analysis aimed at disentangling risks through step-by-step reasoning within multimodal inputs. We find that systematic multimodal risk disentanglement substantially enhances the risk awareness of MLLMs. Via leveraging the strong discriminative abilities of multimodal risk disentanglement, we further introduce \textbf{DREAM} (\textit{\textbf{D}isentangling \textbf{R}isks to \textbf{E}nhance Safety \textbf{A}lignment in \textbf{M}LLMs}), a novel approach that enhances safety alignment in MLLMs through supervised fine-tuning and iterative Reinforcement Learning from AI Feedback (RLAIF). Experimental results show that DREAM significantly boosts safety during both inference and training phases without compromising performance on normal tasks (namely oversafety), achieving a 16.17\% improvement in the SIUO safe\&effective score compared to GPT-4V. The data and code are available at https://github.com/Kizna1ver/DREAM.
PerturboLLaVA: Reducing Multimodal Hallucinations with Perturbative Visual Training
Mar 09, 2025This paper aims to address the challenge of hallucinations in Multimodal Large Language Models (MLLMs) particularly for dense image captioning tasks. To tackle the challenge, we identify the current lack of a metric that finely measures the caption quality in concept level. We hereby introduce HalFscore, a novel metric built upon the language graph and is designed to evaluate both the accuracy and completeness of dense captions at a granular level. Additionally, we identify the root cause of hallucination as the model's over-reliance on its language prior. To address this, we propose PerturboLLaVA, which reduces the model's reliance on the language prior by incorporating adversarially perturbed text during training. This method enhances the model's focus on visual inputs, effectively reducing hallucinations and producing accurate, image-grounded descriptions without incurring additional computational overhead. PerturboLLaVA significantly improves the fidelity of generated captions, outperforming existing approaches in handling multimodal hallucinations and achieving improved performance across general multimodal benchmarks.