 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFactCheck: Feasibility-aware Long-term Action Anticipation with Multi-agent Collaboration
Jun 10, 2026Long-term action anticipation (LTA) aims to predict an ordered sequence of future verb-noun actions from a partially observed video. While this task serves as the foundation for embodied intelligence, anticipating physically feasible long-term actions remains a critical challenge. Existing methods, which operate in an open-loop manner, often hallucinate non-existent objects, violate object affordances, or disregard object states, as they lack explicit mechanisms to verify action feasibility against the physical environment. To address this, we propose FactCheck, a novel multi-agent collaboration framework that improves feasibility through a closed-loop "Observe-Plan-Verify" mechanism. FactCheck decomposes the complex LTA task into specialized roles: an Observer that recognizes historical actions from video observations and constructs a dual-form structured memory, comprising a History Action Abstract that captures high-level human intentions and environmental status, and a History Action Graph that encodes object states and temporal dependencies; a Planner that generates draft future actions conditioned on both low-level historical actions and high-level History Action Abstract; and a Verifier that rigorously validates the draft against the History Action Graph and refines infeasible actions. Extensive experiments on the EPIC-Kitchens-55 and EGTEA Gaze+ benchmarks demonstrate that FactCheck consistently outperforms state-of-the-art methods. Our work establishes a new paradigm for feasibility-aware long-term action anticipation, effectively closing the loop of action recognition, action prediction and action verification.
GPrune-LLM: Generalization-Aware Structured Pruning for Large Language Models
Mar 12, 2026Structured pruning is widely used to compress large language models (LLMs), yet its effectiveness depends heavily on neuron importance estimation. Most existing methods estimate neuron importance from activation statistics on a single calibration dataset, which introduces calibration bias and degrades downstream cross-task generalization. We observe that neurons exhibit heterogeneous distribution sensitivity, with distribution-robust neurons maintaining consistent rankings across datasets and distribution-sensitive neurons showing high cross-dataset ranking variance. Based on this, we identify two structural limitations in existing methods. First, ranking all neurons within a shared space causes distribution-sensitive neurons that strongly activate on calibration inputs to dominate, crowding out distribution-robust neurons critical for out-of-distribution tasks. Second, applying activation-based importance metrics uniformly can be unreliable. Distribution-sensitive neurons that infrequently activate on calibration data receive insufficient activation signal for accurate local ranking. To address these limitations, we propose GPrune-LLM, a generalization-aware structured pruning framework that explicitly accounts for neuron differences in cross-distribution behavior. We first partition neurons into behavior-consistent modules to localize ranking competition, then evaluate activation-based metric reliability per module according to distribution sensitivity and score magnitude. For modules where activation-based scoring is unreliable, we switch to an activation-independent metric. Finally, we adaptively learn module-wise sparsity. Extensive experiments across multiple downstream tasks demonstrate GPrune-LLM's consistent improvements in post-compression generalization, particularly at high sparsity, and reduced dependence on importance metric choice.
Ctrl&Shift: High-Quality Geometry-Aware Object Manipulation in Visual Generation
Feb 11, 2026Object-level manipulation, relocating or reorienting objects in images or videos while preserving scene realism, is central to film post-production, AR, and creative editing. Yet existing methods struggle to jointly achieve three core goals: background preservation, geometric consistency under viewpoint shifts, and user-controllable transformations. Geometry-based approaches offer precise control but require explicit 3D reconstruction and generalize poorly; diffusion-based methods generalize better but lack fine-grained geometric control. We present Ctrl&Shift, an end-to-end diffusion framework to achieve geometry-consistent object manipulation without explicit 3D representations. Our key insight is to decompose manipulation into two stages, object removal and reference-guided inpainting under explicit camera pose control, and encode both within a unified diffusion process. To enable precise, disentangled control, we design a multi-task, multi-stage training strategy that separates background, identity, and pose signals across tasks. To improve generalization, we introduce a scalable real-world dataset construction pipeline that generates paired image and video samples with estimated relative camera poses. Extensive experiments demonstrate that Ctrl&Shift achieves state-of-the-art results in fidelity, viewpoint consistency, and controllability. To our knowledge, this is the first framework to unify fine-grained geometric control and real-world generalization for object manipulation, without relying on any explicit 3D modeling.
FedRD: Reducing Divergences for Generalized Federated Learning via Heterogeneity-aware Parameter Guidance
Jan 28, 2026Heterogeneous federated learning (HFL) aims to ensure effective and privacy-preserving collaboration among different entities. As newly joined clients require significant adjustments and additional training to align with the existing system, the problem of generalizing federated learning models to unseen clients under heterogeneous data has become progressively crucial. Consequently, we highlight two unsolved challenging issues in federated domain generalization: Optimization Divergence and Performance Divergence. To tackle the above challenges, we propose FedRD, a novel heterogeneity-aware federated learning algorithm that collaboratively utilizes parameter-guided global generalization aggregation and local debiased classification to reduce divergences, aiming to obtain an optimal global model for participating and unseen clients. Extensive experiments on public multi-domain datasets demonstrate that our approach exhibits a substantial performance advantage over competing baselines in addressing this specific problem.
FedCCA: Client-Centric Adaptation against Data Heterogeneity in Federated Learning on IoT Devices
Jan 25, 2026With the rapid development of the Internet of Things (IoT), AI model training on private data such as human sensing data is highly desired. Federated learning (FL) has emerged as a privacy-preserving distributed training framework for this purpuse. However, the data heterogeneity issue among IoT devices can significantly degrade the model performance and convergence speed in FL. Existing approaches limit in fixed client selection and aggregation on cloud server, making the privacy-preserving extraction of client-specific information during local training challenging. To this end, we propose Client-Centric Adaptation federated learning (FedCCA), an algorithm that optimally utilizes client-specific knowledge to learn a unique model for each client through selective adaptation, aiming to alleviate the influence of data heterogeneity. Specifically, FedCCA employs dynamic client selection and adaptive aggregation based on the additional client-specific encoder. To enhance multi-source knowledge transfer, we adopt an attention-based global aggregation strategy. We conducted extensive experiments on diverse datasets to assess the efficacy of FedCCA. The experimental results demonstrate that our approach exhibits a substantial performance advantage over competing baselines in addressing this specific problem.
Continuous Vision-Language-Action Co-Learning with Semantic-Physical Alignment for Behavioral Cloning
Nov 18, 2025



Language-conditioned manipulation facilitates human-robot interaction via behavioral cloning (BC), which learns control policies from human demonstrations and serves as a cornerstone of embodied AI. Overcoming compounding errors in sequential action decisions remains a central challenge to improving BC performance. Existing approaches mitigate compounding errors through data augmentation, expressive representation, or temporal abstraction. However, they suffer from physical discontinuities and semantic-physical misalignment, leading to inaccurate action cloning and intermittent execution. In this paper, we present Continuous vision-language-action Co-Learning with Semantic-Physical Alignment (CCoL), a novel BC framework that ensures temporally consistent execution and fine-grained semantic grounding. It generates robust and smooth action execution trajectories through continuous co-learning across vision, language, and proprioceptive inputs (e.g., robot internal states). Meanwhile, we anchor language semantics to visuomotor representations by a bidirectional cross-attention to learn contextual information for action generation, successfully overcoming the problem of semantic-physical misalignment. Extensive experiments show that CCoL achieves an average 8.0% relative improvement across three simulation suites, with up to 19.2% relative gain in human-demonstrated bimanual insertion tasks. Real-world tests on a 7-DoF robot further confirm CCoL's generalization under unseen and noisy object states.
Covariance-based Imaging and Multi-View Fusion for Networked Sensing
Nov 18, 2025This paper considers multi-view imaging in a sixth-generation (6G) integrated sensing and communication network, which consists of a transmit base-station (BS), multiple receive BSs connected to a central processing unit (CPU), and multiple extended targets. Our goal is to devise an effective multi-view imaging technique that can jointly leverage the targets' echo signals at all the receive BSs to precisely construct the image of these targets. To achieve this goal, we propose a two-phase approach. In Phase I, each receive BS recovers an individual image based on the sample covariance matrix of its received signals. Specifically, we propose a novel covariance-based imaging framework to jointly estimate effective scattering intensity and grid positions, which reduces the number of estimated parameters leveraging channel statistical properties and allows grid adjustment to conform to target geometry. In Phase II, the CPU fuses the individual images of all the receivers to construct a high-quality image of all the targets. Specifically, we design edge-preserving natural neighbor interpolation (EP-NNI) to map individual heterogeneous images onto common and finer grids, and then propose a joint optimization framework to estimate fused scattering intensity and BS fields of view. Extensive numerical results show that the proposed scheme significantly enhances imaging performance, facilitating high-quality environment reconstruction for future 6G networks.
Integrated Massive Communication and Target Localization in 6G Cell-Free Networks
Oct 16, 2025This paper presents an initial investigation into the combination of integrated sensing and communication (ISAC) and massive communication, both of which are largely regarded as key scenarios in sixth-generation (6G) wireless networks. Specifically, we consider a cell-free network comprising a large number of users, multiple targets, and distributed base stations (BSs). In each time slot, a random subset of users becomes active, transmitting pilot signals that can be scattered by the targets before reaching the BSs. Unlike conventional massive random access schemes, where the primary objectives are device activity detection and channel estimation, our framework also enables target localization by leveraging the multipath propagation effects introduced by the targets. However, due to the intricate dependency between user channels and target locations, characterizing the posterior distribution required for minimum mean-square error (MMSE) estimation presents significant computational challenges. To handle this problem, we propose a hybrid message passing-based framework that incorporates multiple approximations to mitigate computational complexity. Numerical results demonstrate that the proposed approach achieves high-accuracy device activity detection, channel estimation, and target localization simultaneously, validating the feasibility of embedding localization functionality into massive communication systems for future 6G networks.
InfiR2: A Comprehensive FP8 Training Recipe for Reasoning-Enhanced Language Models
Sep 26, 2025


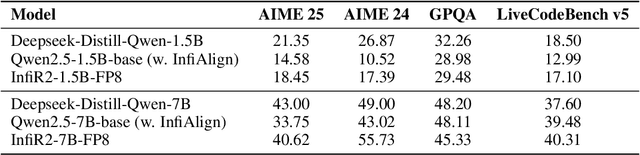
The immense computational cost of training Large Language Models (LLMs) presents a major barrier to innovation. While FP8 training offers a promising solution with significant theoretical efficiency gains, its widespread adoption has been hindered by the lack of a comprehensive, open-source training recipe. To bridge this gap, we introduce an end-to-end FP8 training recipe that seamlessly integrates continual pre-training and supervised fine-tuning. Our methodology employs a fine-grained, hybrid-granularity quantization strategy to maintain numerical fidelity while maximizing computational efficiency. Through extensive experiments, including the continue pre-training of models on a 160B-token corpus, we demonstrate that our recipe is not only remarkably stable but also essentially lossless, achieving performance on par with the BF16 baseline across a suite of reasoning benchmarks. Crucially, this is achieved with substantial efficiency improvements, including up to a 22% reduction in training time, a 14% decrease in peak memory usage, and a 19% increase in throughput. Our results establish FP8 as a practical and robust alternative to BF16, and we will release the accompanying code to further democratize large-scale model training.
You Don't Need Pre-built Graphs for RAG: Retrieval Augmented Generation with Adaptive Reasoning Structures
Aug 08, 2025Large language models (LLMs) often suffer from hallucination, generating factually incorrect statements when handling questions beyond their knowledge and perception. Retrieval-augmented generation (RAG) addresses this by retrieving query-relevant contexts from knowledge bases to support LLM reasoning. Recent advances leverage pre-constructed graphs to capture the relational connections among distributed documents, showing remarkable performance in complex tasks. However, existing Graph-based RAG (GraphRAG) methods rely on a costly process to transform the corpus into a graph, introducing overwhelming token cost and update latency. Moreover, real-world queries vary in type and complexity, requiring different logic structures for accurate reasoning. The pre-built graph may not align with these required structures, resulting in ineffective knowledge retrieval. To this end, we propose a \textbf{\underline{Logic}}-aware \textbf{\underline{R}}etrieval-\textbf{\underline{A}}ugmented \textbf{\underline{G}}eneration framework (\textbf{LogicRAG}) that dynamically extracts reasoning structures at inference time to guide adaptive retrieval without any pre-built graph. LogicRAG begins by decomposing the input query into a set of subproblems and constructing a directed acyclic graph (DAG) to model the logical dependencies among them. To support coherent multi-step reasoning, LogicRAG then linearizes the graph using topological sort, so that subproblems can be addressed in a logically consistent order. Besides, LogicRAG applies graph pruning to reduce redundant retrieval and uses context pruning to filter irrelevant context, significantly reducing the overall token cost. Extensive experiments demonstrate that LogicRAG achieves both superior performance and efficiency compared to state-of-the-art baselines.