 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeatCal: Feature Calibration for Post-Merging Models
May 13, 2026Model merging combines task experts into one model and avoids joint training, retraining, or deploying many expert models, but the merged model often still underperforms task experts. We study this performance gap through feature drift, the difference between features produced by the merged model and by the expert on the same input. Our theory decomposes this drift into upstream propagation and local mismatch, tracks how it propagates and combines through later layers in forward order, and links final feature drift to output drift. This view motivates FeatCal, which uses a small calibration set to calibrate the merged model weights layer by layer in forward order, reducing feature drift while staying close to merged weights and preserving the benefits of model merging. FeatCal uses an efficient closed-form solution to update model weights, with no gradient descent, iterative optimization, or extra modules. On the main CLIP and GLUE benchmarks, FeatCal beats Surgery and ProbSurgery, the closest post-merging calibration baselines: 85.5% vs. 77.0%/78.8% on CLIP-ViT-B/32 Task Arithmetic (TA) and 85.2% vs. 83.7%/82.2% on FLAN-T5-base GLUE. On CLIP-ViT-B/32, 8 examples per task reach 82.9%, and 256 examples per task take 53 seconds, about 4x faster than both baselines, showing better sample efficiency and lower calibration cost.
Geometry Conflict: Explaining and Controlling Forgetting in LLM Continual Post-Training
May 10, 2026Continual post-training aims to extend large language models (LLMs) with new knowledge, skills, and behaviors, yet it remains unclear when sequential updates enable capability transfer and when they cause catastrophic forgetting. Existing methods mitigate forgetting through sequential fine-tuning, replay, regularization, or model merging, but offer limited criteria for determining when incorporating new updates is beneficial or harmful. In this work, we study LLM continual post-training through three questions: What drives forgetting? When do sequentially acquired capabilities transfer or interfere? How can compatibility be used to control update integration? We address these questions through task geometry: we represent each post-training task by its parameter update and study the covariance geometry induced by the update. Our central finding is that: forgetting can be considered as a state-relative update-integration failure, it arises when the covariance geometries induced by tasks misalign with the geometry of the evolving model state. Sequential updates transfer when they remain compatible with the model state shaped by previous updates, and interfere when state-relative geometry conflict becomes high. Motivated by this finding, we propose Geometry-Conflict Wasserstein Merging (GCWM), a data-free update-integration method that constructs a shared Wasserstein metric via Gaussian Wasserstein barycenters and uses geometry conflict to gate geometry-aware correction. Across Qwen3 0.6B--14B on domain-continual and capability-continual settings, GCWM consistently outperforms data-free baselines, improving retention and final performance without replay data. These results identify geometry conflict as both an explanatory signal for forgetting and a practical control signal for LLM continual post-training.
Cross-Vehicle 3D Geometric Consistency for Self-Supervised Surround Depth Estimation on Articulated Vehicles
Apr 03, 2026Surround depth estimation provides a cost-effective alternative to LiDAR for 3D perception in autonomous driving. While recent self-supervised methods explore multi-camera settings to improve scale awareness and scene coverage, they are primarily designed for passenger vehicles and rarely consider articulated vehicles or robotics platforms. The articulated structure introduces complex cross-segment geometry and motion coupling, making consistent depth reasoning across views more challenging. In this work, we propose \textbf{ArticuSurDepth}, a self-supervised framework for surround-view depth estimation on articulated vehicles that enhances depth learning through cross-view and cross-vehicle geometric consistency guided by structural priors from vision foundation model. Specifically, we introduce multi-view spatial context enrichment strategy and a cross-view surface normal constraint to improve structural coherence across spatial and temporal contexts. We further incorporate camera height regularization with ground plane-awareness to encourage metric depth estimation, together with cross-vehicle pose consistency that bridges motion estimation between articulated segments. To validate our proposed method, an articulated vehicle experiment platform was established with a dataset collected over it. Experiment results demonstrate state-of-the-art (SoTA) performance of depth estimation on our self-collected dataset as well as on DDAD, nuScenes, and KITTI benchmarks.
DiffAttn: Diffusion-Based Drivers' Visual Attention Prediction with LLM-Enhanced Semantic Reasoning
Mar 30, 2026Drivers' visual attention provides critical cues for anticipating latent hazards and directly shapes decision-making and control maneuvers, where its absence can compromise traffic safety. To emulate drivers' perception patterns and advance visual attention prediction for intelligent vehicles, we propose DiffAttn, a diffusion-based framework that formulates this task as a conditional diffusion-denoising process, enabling more accurate modeling of drivers' attention. To capture both local and global scene features, we adopt Swin Transformer as encoder and design a decoder that combines a Feature Fusion Pyramid for cross-layer interaction with dense, multi-scale conditional diffusion to jointly enhance denoising learning and model fine-grained local and global scene contexts. Additionally, a large language model (LLM) layer is incorporated to enhance top-down semantic reasoning and improve sensitivity to safety-critical cues. Extensive experiments on four public datasets demonstrate that DiffAttn achieves state-of-the-art (SoTA) performance, surpassing most video-based, top-down-feature-driven, and LLM-enhanced baselines. Our framework further supports interpretable driver-centric scene understanding and has the potential to improve in-cabin human-machine interaction, risk perception, and drivers' state measurement in intelligent vehicles.
VecFormer: Towards Efficient and Generalizable Graph Transformer with Graph Token Attention
Feb 23, 2026Graph Transformer has demonstrated impressive capabilities in the field of graph representation learning. However, existing approaches face two critical challenges: (1) most models suffer from exponentially increasing computational complexity, making it difficult to scale to large graphs; (2) attention mechanisms based on node-level operations limit the flexibility of the model and result in poor generalization performance in out-of-distribution (OOD) scenarios. To address these issues, we propose \textbf{VecFormer} (the \textbf{Vec}tor Quantized Graph Trans\textbf{former}), an efficient and highly generalizable model for node classification, particularly under OOD settings. VecFormer adopts a two-stage training paradigm. In the first stage, two codebooks are used to reconstruct the node features and the graph structure, aiming to learn the rich semantic \texttt{Graph Codes}. In the second stage, attention mechanisms are performed at the \texttt{Graph Token} level based on the transformed cross codebook, reducing computational complexity while enhancing the model's generalization capability. Extensive experiments on datasets of various sizes demonstrate that VecFormer outperforms the existing Graph Transformer in both performance and speed.
Pareto-guided Pipeline for Distilling Featherweight AI Agents in Mobile MOBA Games
Feb 07, 2026Recent advances in game AI have demonstrated the feasibility of training agents that surpass top-tier human professionals in complex environments such as Honor of Kings (HoK), a leading mobile multiplayer online battle arena (MOBA) game. However, deploying such powerful agents on mobile devices remains a major challenge. On one hand, the intricate multi-modal state representation and hierarchical action space of HoK demand large, sophisticated policy networks that are inherently difficult to compress into lightweight forms. On the other hand, production deployment requires high-frequency inference under strict energy and latency constraints on mobile platform. To the best of our knowledge, bridging large-scale game AI and practical on-device deployment has not been systematically studied. In this work, we propose a Pareto optimality guided pipeline and design a high-efficiency student architecture search space tailored for mobile execution, enabling systematic exploration of the trade-off between performance and efficiency. Experimental results demonstrate that the distilled model achieves remarkable efficiency, including an $12.4\times$ faster inference speed (under 0.5ms per frame) and a $15.6\times$ improvement in energy efficiency (under 0.5mAh per game), while retaining a 40.32% win rate against the original teacher model.
GeoSurDepth: Spatial Geometry-Consistent Self-Supervised Depth Estimation for Surround-View Cameras
Jan 09, 2026Accurate surround-view depth estimation provides a competitive alternative to laser-based sensors and is essential for 3D scene understanding in autonomous driving. While prior studies have proposed various approaches that primarily focus on enforcing cross-view constraints at the photometric level, few explicitly exploit the rich geometric structure inherent in both monocular and surround-view setting. In this work, we propose GeoSurDepth, a framework that leverages geometry consistency as the primary cue for surround-view depth estimation. Concretely, we utilize foundation models as a pseudo geometry prior and feature representation enhancement tool to guide the network to maintain surface normal consistency in spatial 3D space and regularize object- and texture-consistent depth estimation in 2D. In addition, we introduce a novel view synthesis pipeline where 2D-3D lifting is achieved with dense depth reconstructed via spatial warping, encouraging additional photometric supervision across temporal, spatial, and spatial-temporal contexts, and compensating for the limitations of single-view image reconstruction. Finally, a newly-proposed adaptive joint motion learning strategy enables the network to adaptively emphasize informative spatial geometry cues for improved motion reasoning. Extensive experiments on DDAD and nuScenes demonstrate that GeoSurDepth achieves state-of-the-art performance, validating the effectiveness of our approach. Our framework highlights the importance of exploiting geometry coherence and consistency for robust self-supervised multi-view depth estimation.
Meta Lattice: Model Space Redesign for Cost-Effective Industry-Scale Ads Recommendations
Dec 15, 2025The rapidly evolving landscape of products, surfaces, policies, and regulations poses significant challenges for deploying state-of-the-art recommendation models at industry scale, primarily due to data fragmentation across domains and escalating infrastructure costs that hinder sustained quality improvements. To address this challenge, we propose Lattice, a recommendation framework centered around model space redesign that extends Multi-Domain, Multi-Objective (MDMO) learning beyond models and learning objectives. Lattice addresses these challenges through a comprehensive model space redesign that combines cross-domain knowledge sharing, data consolidation, model unification, distillation, and system optimizations to achieve significant improvements in both quality and cost-efficiency. Our deployment of Lattice at Meta has resulted in 10% revenue-driving top-line metrics gain, 11.5% user satisfaction improvement, 6% boost in conversion rate, with 20% capacity saving.
InfiR2: A Comprehensive FP8 Training Recipe for Reasoning-Enhanced Language Models
Sep 26, 2025


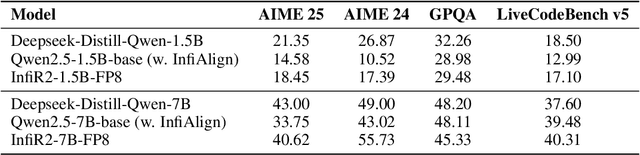
The immense computational cost of training Large Language Models (LLMs) presents a major barrier to innovation. While FP8 training offers a promising solution with significant theoretical efficiency gains, its widespread adoption has been hindered by the lack of a comprehensive, open-source training recipe. To bridge this gap, we introduce an end-to-end FP8 training recipe that seamlessly integrates continual pre-training and supervised fine-tuning. Our methodology employs a fine-grained, hybrid-granularity quantization strategy to maintain numerical fidelity while maximizing computational efficiency. Through extensive experiments, including the continue pre-training of models on a 160B-token corpus, we demonstrate that our recipe is not only remarkably stable but also essentially lossless, achieving performance on par with the BF16 baseline across a suite of reasoning benchmarks. Crucially, this is achieved with substantial efficiency improvements, including up to a 22% reduction in training time, a 14% decrease in peak memory usage, and a 19% increase in throughput. Our results establish FP8 as a practical and robust alternative to BF16, and we will release the accompanying code to further democratize large-scale model training.
Addressing Graph Anomaly Detection via Causal Edge Separation and Spectrum
Aug 20, 2025


In the real world, anomalous entities often add more legitimate connections while hiding direct links with other anomalous entities, leading to heterophilic structures in anomalous networks that most GNN-based techniques fail to address. Several works have been proposed to tackle this issue in the spatial domain. However, these methods overlook the complex relationships between node structure encoding, node features, and their contextual environment and rely on principled guidance, research on solving spectral domain heterophilic problems remains limited. This study analyzes the spectral distribution of nodes with different heterophilic degrees and discovers that the heterophily of anomalous nodes causes the spectral energy to shift from low to high frequencies. To address the above challenges, we propose a spectral neural network CES2-GAD based on causal edge separation for anomaly detection on heterophilic graphs. Firstly, CES2-GAD will separate the original graph into homophilic and heterophilic edges using causal interventions. Subsequently, various hybrid-spectrum filters are used to capture signals from the segmented graphs. Finally, representations from multiple signals are concatenated and input into a classifier to predict anomalies. Extensive experiments with real-world datasets have proven the effectiveness of the method we proposed.