 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReliability-Prioritized Fine-Grained Generation in Multimodal Large
Jun 28, 2026Multimodal large language models (MLLMs) are increasingly expected to generate fine-grained descriptions of visual content. However, we observe and theoretically show that generating fine-grained responses poses a reliability challenge, \textit{i.e.}, fine-grained generation is more error-prone than coarse-grained generation. This phenomenon suggests that models should generate the finest description that remains reliable rather than simply produce more specific outputs. To investigate this problem, we develop \textsc{GranFact}, a granularity-aware benchmark consisting of expert-verified multi-object images with coarse-to-fine category annotations. Then, we design a hierarchy-aware evaluation algorithm, which assesses both whether model predictions are visually correct and how specific the correct predictions are. We also propose a reliability-prioritized preference optimization method based on Direct Preference Optimization, which penalizes unreliable fine-grained claims while rewarding reliable specificity. Experiments on \textsc{GranFact} show that our method improves fine-grained generation while preserving reliability. Code and data are available \href{https://github.com/WeiWu2025/GranFact}{here}.
Rethinking 3D Shape Generation: Diffusion over Superquadrics
Jun 08, 2026Diffusion models have advanced 3D shape generation, yet most methods still denoise in high-cardinality spaces (e.g., voxel/SDF grids, meshes, or point clouds), which is computationally and memory intensive and makes it difficult to scale in terms of both higher resolution and stronger controllability. We rethink the diffusion representation and propose to move diffusion from dense geometry to compact geometric primitives, representing each shape as a small set of superquadrics. Instead of operating on thousands to millions of geometric representation values, we leverage 7KB superquadric parameters (pose, size, and shape), drastically reducing diffusion-state dimensionality and per-step compute/memory. Our diffusion-over-superquadrics improves scalability by supporting broader capabilities (e.g., resolution-free point-cloud decoding, part-level editing, and constraint-based design) and achieving competitive surface-fidelity and distributional performance on standard benchmarks after point-cloud decoding, while enabling efficient generation within 0.6s per shape for most conditions.
Chart-FR1: Visual Focus-Driven Fine-Grained Reasoning on Dense Charts
May 03, 2026Multimodal large language models (MLLMs) have shown considerable potential in chart understanding and reasoning tasks. However, they still struggle with high information density (HID) charts characterized by multiple subplots, legends, and dense annotations due to three major challenges: (1) limited fine-grained perception results in the omission of critical visual cues; (2) redundant or noisy visual information undermines the performance of multimodal reasoning; (3) lack of adaptive deep reasoning relative to the amount of visual information. To tackle these challenges, we present a novel focus-driven fine-grained chart reasoning model, Chart-FR1, to improve perception, focusing efficiency, and adaptive deep reasoning on HID charts. Specifically, we propose Focus-CoT, a visual focusing chain-of-thought that enhances fine-grained perception by explicitly linking reasoning steps to key visual cues, such as local image regions and OCR signals. Building on this, we introduce Focus-GRPO, a focus-driven reinforcement learning algorithm with an information-efficiency reward that compresses redundant visual information for efficient focusing, and an adaptive KL penalty mechanism that enables flexible control over reasoning depth as more visual cues are discovered. Furthermore, to fill the gap in benchmarks for HID charts, we build HID-Chart, a challenging benchmark with an information-density metric designed to evaluate fine-grained chart reasoning capabilities. Extensive experiments on multiple chart benchmarks demonstrate that Chart-FR1 outperforms state-of-the-art MLLMs in chart understanding and reasoning. Code is available at https://github.com/phkhub/Chart-FR1.
WildWorld: A Large-Scale Dataset for Dynamic World Modeling with Actions and Explicit State toward Generative ARPG
Mar 24, 2026Dynamical systems theory and reinforcement learning view world evolution as latent-state dynamics driven by actions, with visual observations providing partial information about the state. Recent video world models attempt to learn this action-conditioned dynamics from data. However, existing datasets rarely match the requirement: they typically lack diverse and semantically meaningful action spaces, and actions are directly tied to visual observations rather than mediated by underlying states. As a result, actions are often entangled with pixel-level changes, making it difficult for models to learn structured world dynamics and maintain consistent evolution over long horizons. In this paper, we propose WildWorld, a large-scale action-conditioned world modeling dataset with explicit state annotations, automatically collected from a photorealistic AAA action role-playing game (Monster Hunter: Wilds). WildWorld contains over 108 million frames and features more than 450 actions, including movement, attacks, and skill casting, together with synchronized per-frame annotations of character skeletons, world states, camera poses, and depth maps. We further derive WildBench to evaluate models through Action Following and State Alignment. Extensive experiments reveal persistent challenges in modeling semantically rich actions and maintaining long-horizon state consistency, highlighting the need for state-aware video generation. The project page is https://shandaai.github.io/wildworld-project/.
AdaptMMBench: Benchmarking Adaptive Multimodal Reasoning for Mode Selection and Reasoning Process
Feb 02, 2026Adaptive multimodal reasoning has emerged as a promising frontier in Vision-Language Models (VLMs), aiming to dynamically modulate between tool-augmented visual reasoning and text reasoning to enhance both effectiveness and efficiency. However, existing evaluations rely on static difficulty labels and simplistic metrics, which fail to capture the dynamic nature of difficulty relative to varying model capacities. Consequently, they obscure the distinction between adaptive mode selection and general performance while neglecting fine-grained process analyses. In this paper, we propose AdaptMMBench, a comprehensive benchmark for adaptive multimodal reasoning across five domains: real-world, OCR, GUI, knowledge, and math, encompassing both direct perception and complex reasoning tasks. AdaptMMBench utilizes a Matthews Correlation Coefficient (MCC) metric to evaluate the selection rationality of different reasoning modes, isolating this meta-cognition ability by dynamically identifying task difficulties based on models' capability boundaries. Moreover, AdaptMMBench facilitates multi-dimensional process evaluation across key step coverage, tool effectiveness, and computational efficiency. Our evaluation reveals that while adaptive mode selection scales with model capacity, it notably decouples from final accuracy. Conversely, key step coverage aligns with performance, though tool effectiveness remains highly inconsistent across model architectures.
MIGHTY: Hermite Spline-based Efficient Trajectory Planning
Nov 13, 2025



Hard-constraint trajectory planners often rely on commercial solvers and demand substantial computational resources. Existing soft-constraint methods achieve faster computation, but either (1) decouple spatial and temporal optimization or (2) restrict the search space. To overcome these limitations, we introduce MIGHTY, a Hermite spline-based planner that performs spatiotemporal optimization while fully leveraging the continuous search space of a spline. In simulation, MIGHTY achieves a 9.3% reduction in computation time and a 13.1% reduction in travel time over state-of-the-art baselines, with a 100% success rate. In hardware, MIGHTY completes multiple high-speed flights up to 6.7 m/s in a cluttered static environment and long-duration flights with dynamically added obstacles.
Composition-Incremental Learning for Compositional Generalization
Nov 12, 2025Compositional generalization has achieved substantial progress in computer vision on pre-collected training data. Nonetheless, real-world data continually emerges, with possible compositions being nearly infinite, long-tailed, and not entirely visible. Thus, an ideal model is supposed to gradually improve the capability of compositional generalization in an incremental manner. In this paper, we explore Composition-Incremental Learning for Compositional Generalization (CompIL) in the context of the compositional zero-shot learning (CZSL) task, where models need to continually learn new compositions, intending to improve their compositional generalization capability progressively. To quantitatively evaluate CompIL, we develop a benchmark construction pipeline leveraging existing datasets, yielding MIT-States-CompIL and C-GQA-CompIL. Furthermore, we propose a pseudo-replay framework utilizing a visual synthesizer to synthesize visual representations of learned compositions and a linguistic primitive distillation mechanism to maintain aligned primitive representations across the learning process. Extensive experiments demonstrate the effectiveness of the proposed framework.
Modality Alignment across Trees on Heterogeneous Hyperbolic Manifolds
Oct 31, 2025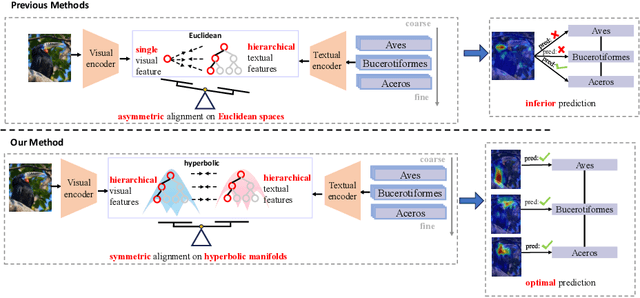
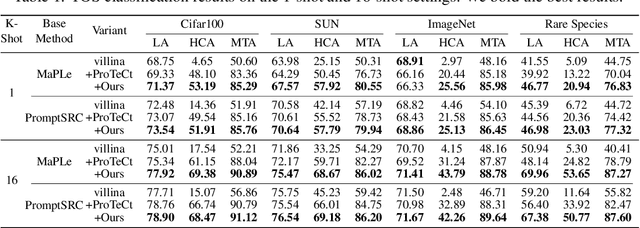
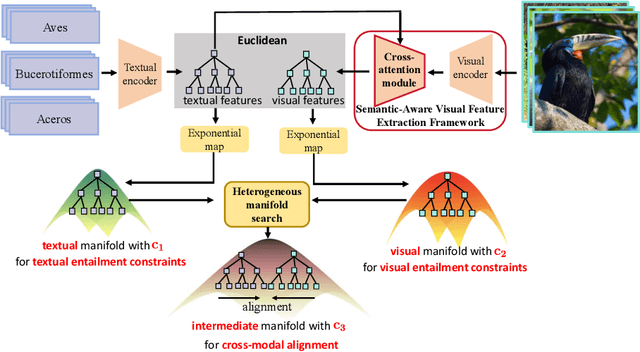

Modality alignment is critical for vision-language models (VLMs) to effectively integrate information across modalities. However, existing methods extract hierarchical features from text while representing each image with a single feature, leading to asymmetric and suboptimal alignment. To address this, we propose Alignment across Trees, a method that constructs and aligns tree-like hierarchical features for both image and text modalities. Specifically, we introduce a semantic-aware visual feature extraction framework that applies a cross-attention mechanism to visual class tokens from intermediate Transformer layers, guided by textual cues to extract visual features with coarse-to-fine semantics. We then embed the feature trees of the two modalities into hyperbolic manifolds with distinct curvatures to effectively model their hierarchical structures. To align across the heterogeneous hyperbolic manifolds with different curvatures, we formulate a KL distance measure between distributions on heterogeneous manifolds, and learn an intermediate manifold for manifold alignment by minimizing the distance. We prove the existence and uniqueness of the optimal intermediate manifold. Experiments on taxonomic open-set classification tasks across multiple image datasets demonstrate that our method consistently outperforms strong baselines under few-shot and cross-domain settings.
GUI Knowledge Bench: Revealing the Knowledge Gap Behind VLM Failures in GUI Tasks
Oct 30, 2025Large vision language models (VLMs) have advanced graphical user interface (GUI) task automation but still lag behind humans. We hypothesize this gap stems from missing core GUI knowledge, which existing training schemes (such as supervised fine tuning and reinforcement learning) alone cannot fully address. By analyzing common failure patterns in GUI task execution, we distill GUI knowledge into three dimensions: (1) interface perception, knowledge about recognizing widgets and system states; (2) interaction prediction, knowledge about reasoning action state transitions; and (3) instruction understanding, knowledge about planning, verifying, and assessing task completion progress. We further introduce GUI Knowledge Bench, a benchmark with multiple choice and yes/no questions across six platforms (Web, Android, MacOS, Windows, Linux, IOS) and 292 applications. Our evaluation shows that current VLMs identify widget functions but struggle with perceiving system states, predicting actions, and verifying task completion. Experiments on real world GUI tasks further validate the close link between GUI knowledge and task success. By providing a structured framework for assessing GUI knowledge, our work supports the selection of VLMs with greater potential prior to downstream training and provides insights for building more capable GUI agents.
PIP-LLM: Integrating PDDL-Integer Programming with LLMs for Coordinating Multi-Robot Teams Using Natural Language
Oct 26, 2025Enabling robot teams to execute natural language commands requires translating high-level instructions into feasible, efficient multi-robot plans. While Large Language Models (LLMs) combined with Planning Domain Description Language (PDDL) offer promise for single-robot scenarios, existing approaches struggle with multi-robot coordination due to brittle task decomposition, poor scalability, and low coordination efficiency. We introduce PIP-LLM, a language-based coordination framework that consists of PDDL-based team-level planning and Integer Programming (IP) based robot-level planning. PIP-LLMs first decomposes the command by translating the command into a team-level PDDL problem and solves it to obtain a team-level plan, abstracting away robot assignment. Each team-level action represents a subtask to be finished by the team. Next, this plan is translated into a dependency graph representing the subtasks' dependency structure. Such a dependency graph is then used to guide the robot-level planning, in which each subtask node will be formulated as an IP-based task allocation problem, explicitly optimizing travel costs and workload while respecting robot capabilities and user-defined constraints. This separation of planning from assignment allows PIP-LLM to avoid the pitfalls of syntax-based decomposition and scale to larger teams. Experiments across diverse tasks show that PIP-LLM improves plan success rate, reduces maximum and average travel costs, and achieves better load balancing compared to state-of-the-art baselines.