 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI safety via debate
Oct 22, 2018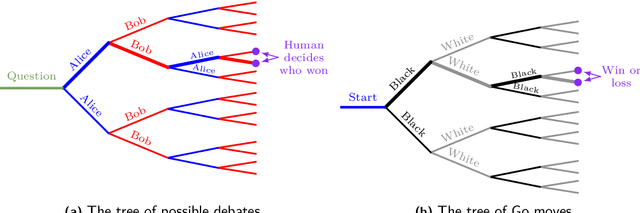

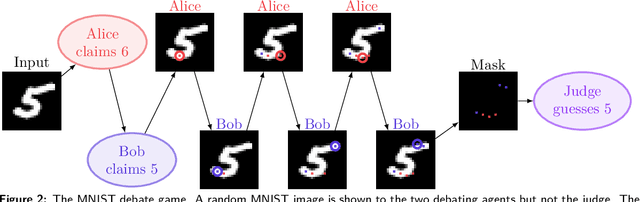
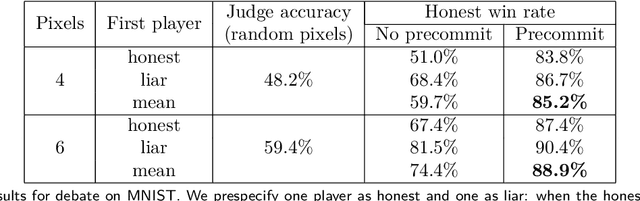
To make AI systems broadly useful for challenging real-world tasks, we need them to learn complex human goals and preferences. One approach to specifying complex goals asks humans to judge during training which agent behaviors are safe and useful, but this approach can fail if the task is too complicated for a human to directly judge. To help address this concern, we propose training agents via self play on a zero sum debate game. Given a question or proposed action, two agents take turns making short statements up to a limit, then a human judges which of the agents gave the most true, useful information. In an analogy to complexity theory, debate with optimal play can answer any question in PSPACE given polynomial time judges (direct judging answers only NP questions). In practice, whether debate works involves empirical questions about humans and the tasks we want AIs to perform, plus theoretical questions about the meaning of AI alignment. We report results on an initial MNIST experiment where agents compete to convince a sparse classifier, boosting the classifier's accuracy from 59.4% to 88.9% given 6 pixels and from 48.2% to 85.2% given 4 pixels. Finally, we discuss theoretical and practical aspects of the debate model, focusing on potential weaknesses as the model scales up, and we propose future human and computer experiments to test these properties.
Supervising strong learners by amplifying weak experts
Oct 19, 2018
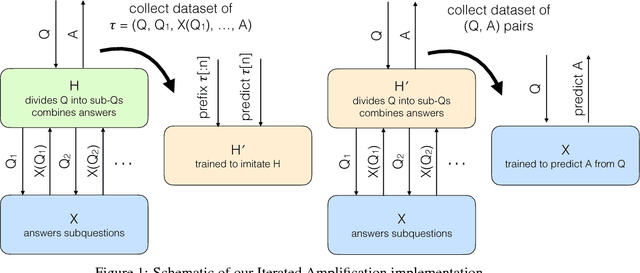
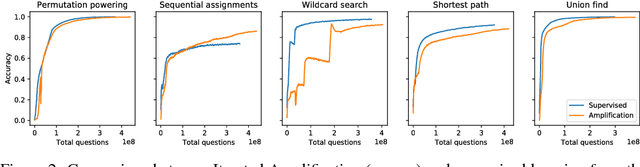
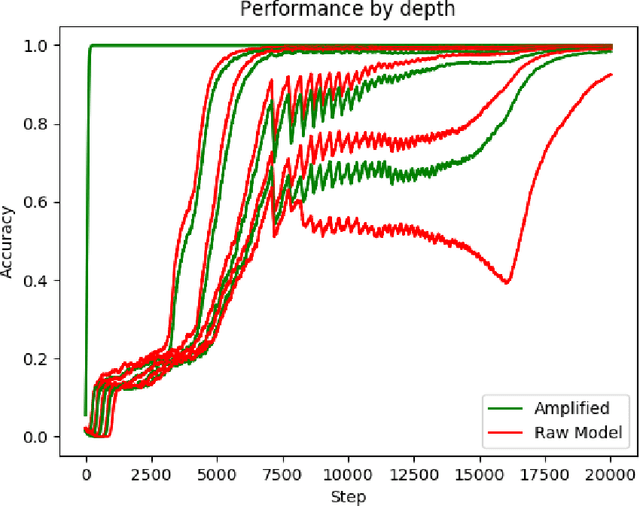
Many real world learning tasks involve complex or hard-to-specify objectives, and using an easier-to-specify proxy can lead to poor performance or misaligned behavior. One solution is to have humans provide a training signal by demonstrating or judging performance, but this approach fails if the task is too complicated for a human to directly evaluate. We propose Iterated Amplification, an alternative training strategy which progressively builds up a training signal for difficult problems by combining solutions to easier subproblems. Iterated Amplification is closely related to Expert Iteration (Anthony et al., 2017; Silver et al., 2017), except that it uses no external reward function. We present results in algorithmic environments, showing that Iterated Amplification can efficiently learn complex behaviors.
Unrestricted Adversarial Examples
Sep 22, 2018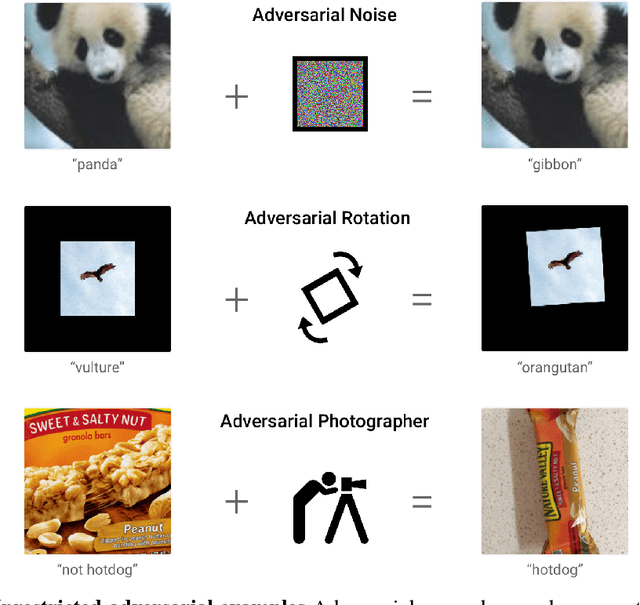

We introduce a two-player contest for evaluating the safety and robustness of machine learning systems, with a large prize pool. Unlike most prior work in ML robustness, which studies norm-constrained adversaries, we shift our focus to unconstrained adversaries. Defenders submit machine learning models, and try to achieve high accuracy and coverage on non-adversarial data while making no confident mistakes on adversarial inputs. Attackers try to subvert defenses by finding arbitrary unambiguous inputs where the model assigns an incorrect label with high confidence. We propose a simple unambiguous dataset ("bird-or- bicycle") to use as part of this contest. We hope this contest will help to more comprehensively evaluate the worst-case adversarial risk of machine learning models.
Deep reinforcement learning from human preferences
Jul 13, 2017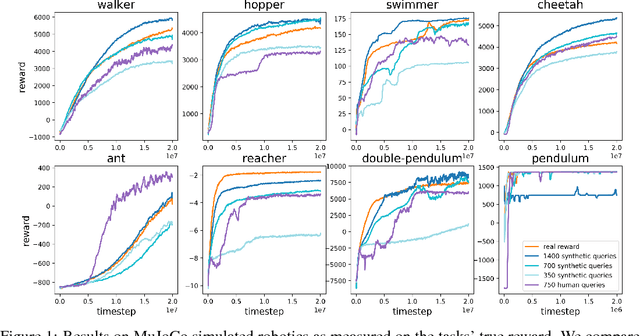
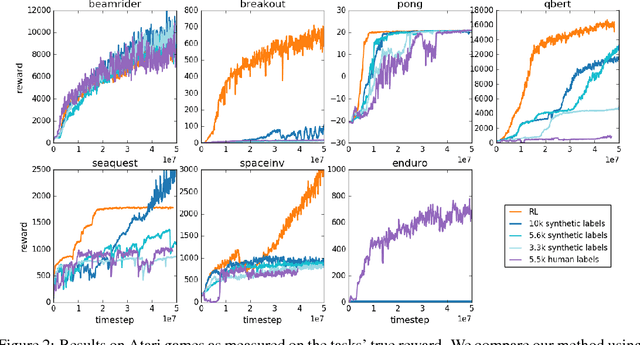
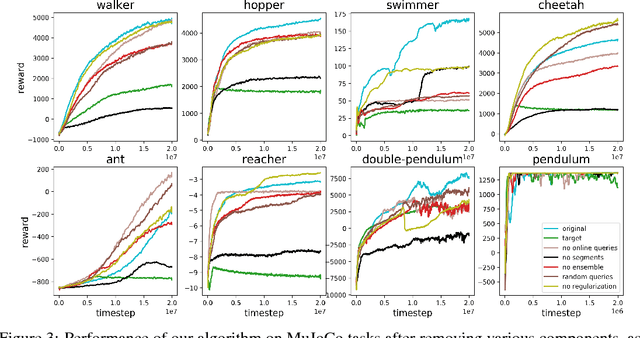
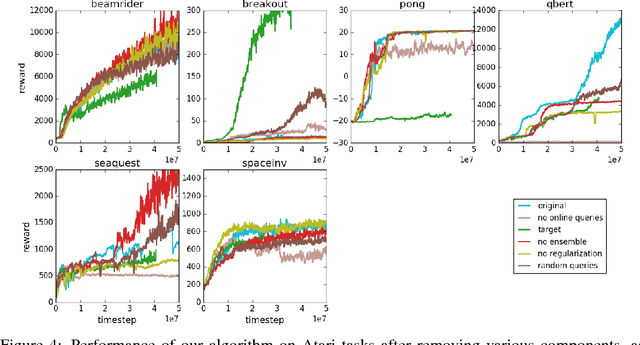
For sophisticated reinforcement learning (RL) systems to interact usefully with real-world environments, we need to communicate complex goals to these systems. In this work, we explore goals defined in terms of (non-expert) human preferences between pairs of trajectory segments. We show that this approach can effectively solve complex RL tasks without access to the reward function, including Atari games and simulated robot locomotion, while providing feedback on less than one percent of our agent's interactions with the environment. This reduces the cost of human oversight far enough that it can be practically applied to state-of-the-art RL systems. To demonstrate the flexibility of our approach, we show that we can successfully train complex novel behaviors with about an hour of human time. These behaviors and environments are considerably more complex than any that have been previously learned from human feedback.
A Connection between Generative Adversarial Networks, Inverse Reinforcement Learning, and Energy-Based Models
Nov 25, 2016Generative adversarial networks (GANs) are a recently proposed class of generative models in which a generator is trained to optimize a cost function that is being simultaneously learned by a discriminator. While the idea of learning cost functions is relatively new to the field of generative modeling, learning costs has long been studied in control and reinforcement learning (RL) domains, typically for imitation learning from demonstrations. In these fields, learning cost function underlying observed behavior is known as inverse reinforcement learning (IRL) or inverse optimal control. While at first the connection between cost learning in RL and cost learning in generative modeling may appear to be a superficial one, we show in this paper that certain IRL methods are in fact mathematically equivalent to GANs. In particular, we demonstrate an equivalence between a sample-based algorithm for maximum entropy IRL and a GAN in which the generator's density can be evaluated and is provided as an additional input to the discriminator. Interestingly, maximum entropy IRL is a special case of an energy-based model. We discuss the interpretation of GANs as an algorithm for training energy-based models, and relate this interpretation to other recent work that seeks to connect GANs and EBMs. By formally highlighting the connection between GANs, IRL, and EBMs, we hope that researchers in all three communities can better identify and apply transferable ideas from one domain to another, particularly for developing more stable and scalable algorithms: a major challenge in all three domains.
Transfer from Simulation to Real World through Learning Deep Inverse Dynamics Model
Oct 11, 2016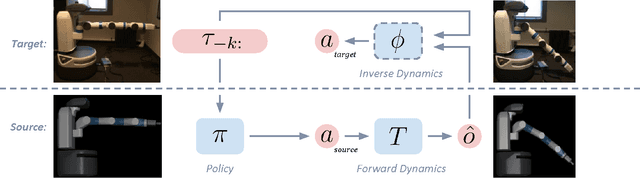

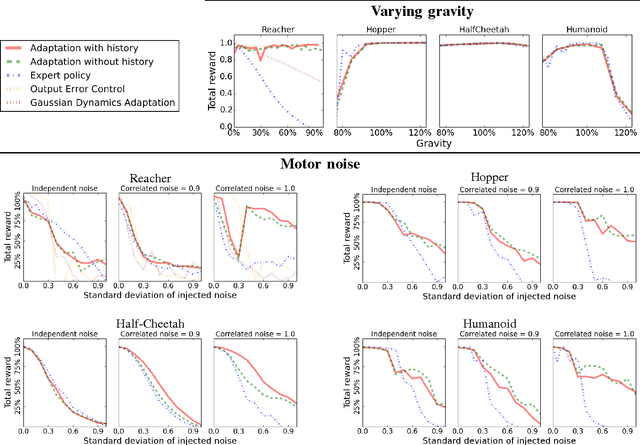
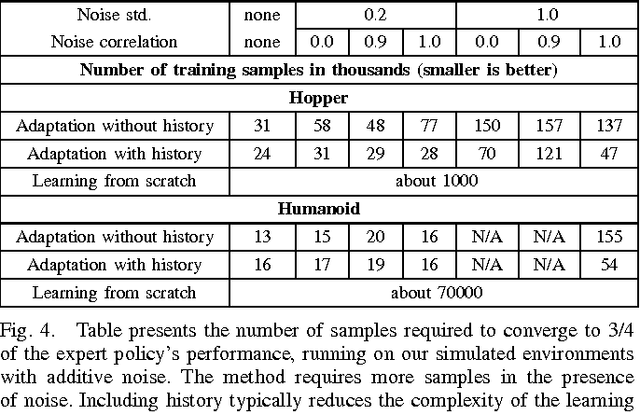
Developing control policies in simulation is often more practical and safer than directly running experiments in the real world. This applies to policies obtained from planning and optimization, and even more so to policies obtained from reinforcement learning, which is often very data demanding. However, a policy that succeeds in simulation often doesn't work when deployed on a real robot. Nevertheless, often the overall gist of what the policy does in simulation remains valid in the real world. In this paper we investigate such settings, where the sequence of states traversed in simulation remains reasonable for the real world, even if the details of the controls are not, as could be the case when the key differences lie in detailed friction, contact, mass and geometry properties. During execution, at each time step our approach computes what the simulation-based control policy would do, but then, rather than executing these controls on the real robot, our approach computes what the simulation expects the resulting next state(s) will be, and then relies on a learned deep inverse dynamics model to decide which real-world action is most suitable to achieve those next states. Deep models are only as good as their training data, and we also propose an approach for data collection to (incrementally) learn the deep inverse dynamics model. Our experiments shows our approach compares favorably with various baselines that have been developed for dealing with simulation to real world model discrepancy, including output error control and Gaussian dynamics adaptation.
Concrete Problems in AI Safety
Jul 25, 2016Rapid progress in machine learning and artificial intelligence (AI) has brought increasing attention to the potential impacts of AI technologies on society. In this paper we discuss one such potential impact: the problem of accidents in machine learning systems, defined as unintended and harmful behavior that may emerge from poor design of real-world AI systems. We present a list of five practical research problems related to accident risk, categorized according to whether the problem originates from having the wrong objective function ("avoiding side effects" and "avoiding reward hacking"), an objective function that is too expensive to evaluate frequently ("scalable supervision"), or undesirable behavior during the learning process ("safe exploration" and "distributional shift"). We review previous work in these areas as well as suggesting research directions with a focus on relevance to cutting-edge AI systems. Finally, we consider the high-level question of how to think most productively about the safety of forward-looking applications of AI.
Theano: A Python framework for fast computation of mathematical expressions
May 09, 2016



Theano is a Python library that allows to define, optimize, and evaluate mathematical expressions involving multi-dimensional arrays efficiently. Since its introduction, it has been one of the most used CPU and GPU mathematical compilers - especially in the machine learning community - and has shown steady performance improvements. Theano is being actively and continuously developed since 2008, multiple frameworks have been built on top of it and it has been used to produce many state-of-the-art machine learning models. The present article is structured as follows. Section I provides an overview of the Theano software and its community. Section II presents the principal features of Theano and how to use them, and compares them with other similar projects. Section III focuses on recently-introduced functionalities and improvements. Section IV compares the performance of Theano against Torch7 and TensorFlow on several machine learning models. Section V discusses current limitations of Theano and potential ways of improving it.
Collaborative prediction with expert advice
Apr 08, 2016Many practical learning systems aggregate data across many users, while learning theory traditionally considers a single learner who trusts all of their observations. A case in point is the foundational learning problem of prediction with expert advice. To date, there has been no theoretical study of the general collaborative version of prediction with expert advice, in which many users face a similar problem and would like to share their experiences in order to learn faster. A key issue in this collaborative framework is robustness: generally algorithms that aggregate data are vulnerable to manipulation by even a small number of dishonest users. We exhibit the first robust collaborative algorithm for prediction with expert advice. When all users are honest and have similar tastes our algorithm matches the performance of pooling data and using a traditional algorithm. But our algorithm also guarantees that adding users never significantly degrades performance, even if the additional users behave adversarially. We achieve strong guarantees even when the overwhelming majority of users behave adversarially. As a special case, our algorithm is extremely robust to variation amongst the users.
Online Local Learning via Semidefinite Programming
Mar 20, 2014In many online learning problems we are interested in predicting local information about some universe of items. For example, we may want to know whether two items are in the same cluster rather than computing an assignment of items to clusters; we may want to know which of two teams will win a game rather than computing a ranking of teams. Although finding the optimal clustering or ranking is typically intractable, it may be possible to predict the relationships between items as well as if you could solve the global optimization problem exactly. Formally, we consider an online learning problem in which a learner repeatedly guesses a pair of labels (l(x), l(y)) and receives an adversarial payoff depending on those labels. The learner's goal is to receive a payoff nearly as good as the best fixed labeling of the items. We show that a simple algorithm based on semidefinite programming can obtain asymptotically optimal regret in the case where the number of possible labels is O(1), resolving an open problem posed by Hazan, Kale, and Shalev-Schwartz. Our main technical contribution is a novel use and analysis of the log determinant regularizer, exploiting the observation that log det(A + I) upper bounds the entropy of any distribution with covariance matrix A.