 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Accompaniment with ReaLchords
Jun 17, 2025Jamming requires coordination, anticipation, and collaborative creativity between musicians. Current generative models of music produce expressive output but are not able to generate in an \emph{online} manner, meaning simultaneously with other musicians (human or otherwise). We propose ReaLchords, an online generative model for improvising chord accompaniment to user melody. We start with an online model pretrained by maximum likelihood, and use reinforcement learning to finetune the model for online use. The finetuning objective leverages both a novel reward model that provides feedback on both harmonic and temporal coherency between melody and chord, and a divergence term that implements a novel type of distillation from a teacher model that can see the future melody. Through quantitative experiments and listening tests, we demonstrate that the resulting model adapts well to unfamiliar input and produce fitting accompaniment. ReaLchords opens the door to live jamming, as well as simultaneous co-creation in other modalities.
ReaLJam: Real-Time Human-AI Music Jamming with Reinforcement Learning-Tuned Transformers
Feb 28, 2025Recent advances in generative artificial intelligence (AI) have created models capable of high-quality musical content generation. However, little consideration is given to how to use these models for real-time or cooperative jamming musical applications because of crucial required features: low latency, the ability to communicate planned actions, and the ability to adapt to user input in real-time. To support these needs, we introduce ReaLJam, an interface and protocol for live musical jamming sessions between a human and a Transformer-based AI agent trained with reinforcement learning. We enable real-time interactions using the concept of anticipation, where the agent continually predicts how the performance will unfold and visually conveys its plan to the user. We conduct a user study where experienced musicians jam in real-time with the agent through ReaLJam. Our results demonstrate that ReaLJam enables enjoyable and musically interesting sessions, and we uncover important takeaways for future work.
Advantage Alignment Algorithms
Jun 20, 2024



The growing presence of artificially intelligent agents in everyday decision-making, from LLM assistants to autonomous vehicles, hints at a future in which conflicts may arise from each agent optimizing individual interests. In general-sum games these conflicts are apparent, where naive Reinforcement Learning agents get stuck in Pareto-suboptimal Nash equilibria. Consequently, opponent shaping has been introduced as a method with success at finding socially beneficial equilibria in social dilemmas. In this work, we introduce Advantage Alignment, a family of algorithms derived from first principles that perform opponent shaping efficiently and intuitively. This is achieved by aligning the advantages of conflicting agents in a given game by increasing the probability of mutually-benefiting actions. We prove that existing opponent shaping methods, including LOLA and LOQA, implicitly perform Advantage Alignment. Compared to these works, Advantage Alignment mathematically simplifies the formulation of opponent shaping and seamlessly works for continuous action domains. We also demonstrate the effectiveness of our algorithm in a wide range of social dilemmas, achieving state of the art results in each case, including a social dilemma version of the Negotiation Game.
LOQA: Learning with Opponent Q-Learning Awareness
May 02, 2024



In various real-world scenarios, interactions among agents often resemble the dynamics of general-sum games, where each agent strives to optimize its own utility. Despite the ubiquitous relevance of such settings, decentralized machine learning algorithms have struggled to find equilibria that maximize individual utility while preserving social welfare. In this paper we introduce Learning with Opponent Q-Learning Awareness (LOQA), a novel, decentralized reinforcement learning algorithm tailored to optimizing an agent's individual utility while fostering cooperation among adversaries in partially competitive environments. LOQA assumes the opponent samples actions proportionally to their action-value function Q. Experimental results demonstrate the effectiveness of LOQA at achieving state-of-the-art performance in benchmark scenarios such as the Iterated Prisoner's Dilemma and the Coin Game. LOQA achieves these outcomes with a significantly reduced computational footprint, making it a promising approach for practical multi-agent applications.
Best Response Shaping
Apr 05, 2024



We investigate the challenge of multi-agent deep reinforcement learning in partially competitive environments, where traditional methods struggle to foster reciprocity-based cooperation. LOLA and POLA agents learn reciprocity-based cooperative policies by differentiation through a few look-ahead optimization steps of their opponent. However, there is a key limitation in these techniques. Because they consider a few optimization steps, a learning opponent that takes many steps to optimize its return may exploit them. In response, we introduce a novel approach, Best Response Shaping (BRS), which differentiates through an opponent approximating the best response, termed the "detective." To condition the detective on the agent's policy for complex games we propose a state-aware differentiable conditioning mechanism, facilitated by a question answering (QA) method that extracts a representation of the agent based on its behaviour on specific environment states. To empirically validate our method, we showcase its enhanced performance against a Monte Carlo Tree Search (MCTS) opponent, which serves as an approximation to the best response in the Coin Game. This work expands the applicability of multi-agent RL in partially competitive environments and provides a new pathway towards achieving improved social welfare in general sum games.
Meta-Value Learning: a General Framework for Learning with Learning Awareness
Jul 17, 2023



Gradient-based learning in multi-agent systems is difficult because the gradient derives from a first-order model which does not account for the interaction between agents' learning processes. LOLA (arXiv:1709.04326) accounts for this by differentiating through one step of optimization. We extend the ideas of LOLA and develop a fully-general value-based approach to optimization. At the core is a function we call the meta-value, which at each point in joint-policy space gives for each agent a discounted sum of its objective over future optimization steps. We argue that the gradient of the meta-value gives a more reliable improvement direction than the gradient of the original objective, because the meta-value derives from empirical observations of the effects of optimization. We show how the meta-value can be approximated by training a neural network to minimize TD error along optimization trajectories in which agents follow the gradient of the meta-value. We analyze the behavior of our method on the Logistic Game and on the Iterated Prisoner's Dilemma.
MIDI-DDSP: Detailed Control of Musical Performance via Hierarchical Modeling
Dec 17, 2021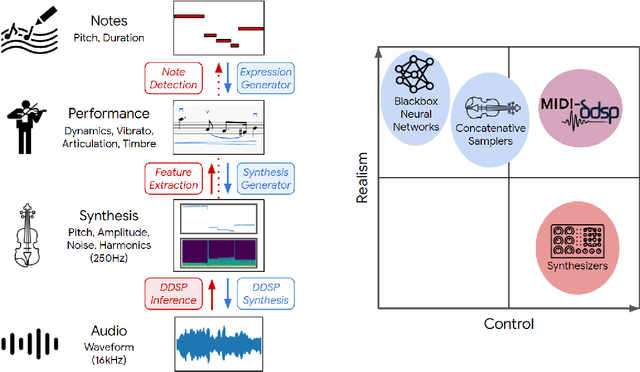
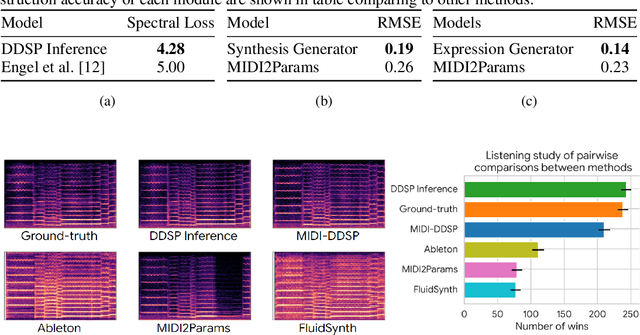
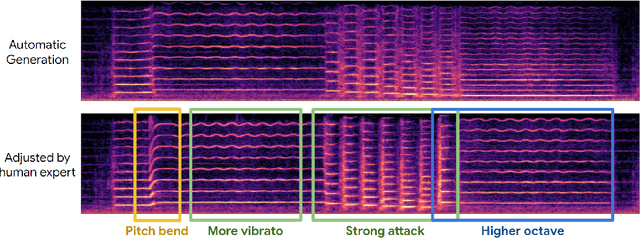
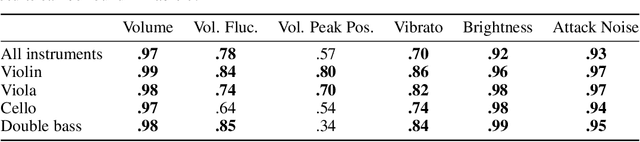
Musical expression requires control of both what notes are played, and how they are performed. Conventional audio synthesizers provide detailed expressive controls, but at the cost of realism. Black-box neural audio synthesis and concatenative samplers can produce realistic audio, but have few mechanisms for control. In this work, we introduce MIDI-DDSP a hierarchical model of musical instruments that enables both realistic neural audio synthesis and detailed user control. Starting from interpretable Differentiable Digital Signal Processing (DDSP) synthesis parameters, we infer musical notes and high-level properties of their expressive performance (such as timbre, vibrato, dynamics, and articulation). This creates a 3-level hierarchy (notes, performance, synthesis) that affords individuals the option to intervene at each level, or utilize trained priors (performance given notes, synthesis given performance) for creative assistance. Through quantitative experiments and listening tests, we demonstrate that this hierarchy can reconstruct high-fidelity audio, accurately predict performance attributes for a note sequence, independently manipulate the attributes of a given performance, and as a complete system, generate realistic audio from a novel note sequence. By utilizing an interpretable hierarchy, with multiple levels of granularity, MIDI-DDSP opens the door to assistive tools to empower individuals across a diverse range of musical experience.
Counterpoint by Convolution
Mar 18, 2019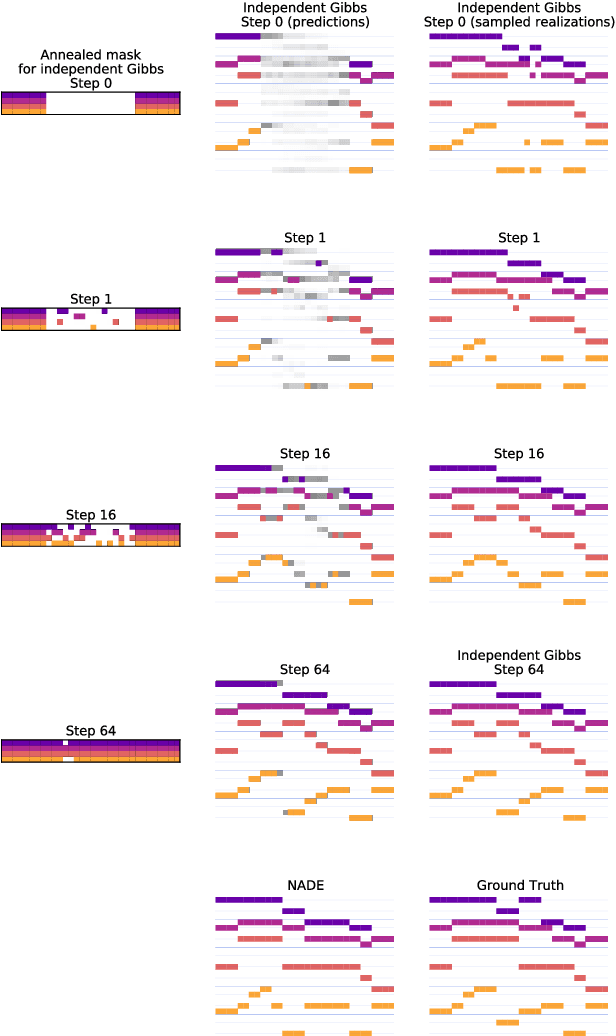
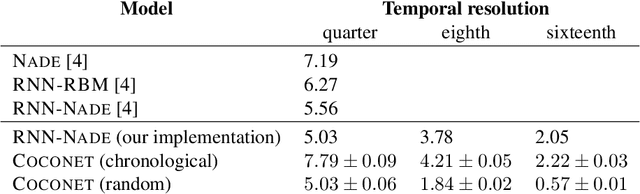
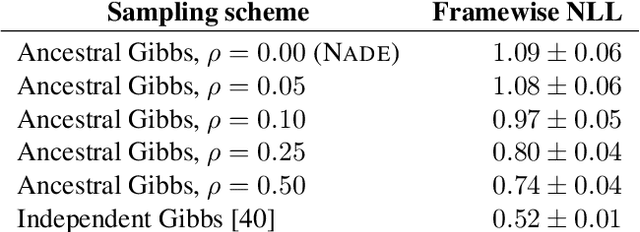
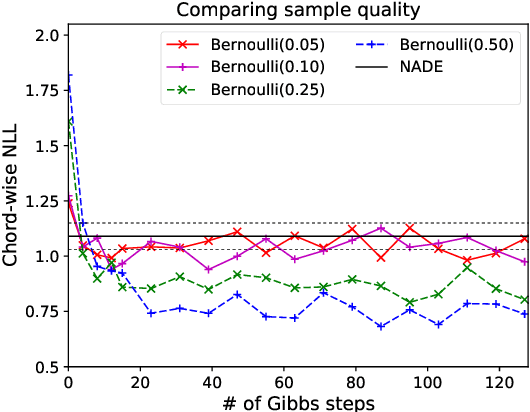
Machine learning models of music typically break up the task of composition into a chronological process, composing a piece of music in a single pass from beginning to end. On the contrary, human composers write music in a nonlinear fashion, scribbling motifs here and there, often revisiting choices previously made. In order to better approximate this process, we train a convolutional neural network to complete partial musical scores, and explore the use of blocked Gibbs sampling as an analogue to rewriting. Neither the model nor the generative procedure are tied to a particular causal direction of composition. Our model is an instance of orderless NADE (Uria et al., 2014), which allows more direct ancestral sampling. However, we find that Gibbs sampling greatly improves sample quality, which we demonstrate to be due to some conditional distributions being poorly modeled. Moreover, we show that even the cheap approximate blocked Gibbs procedure from Yao et al. (2014) yields better samples than ancestral sampling, based on both log-likelihood and human evaluation.
On the Variance of Unbiased Online Recurrent Optimization
Feb 06, 2019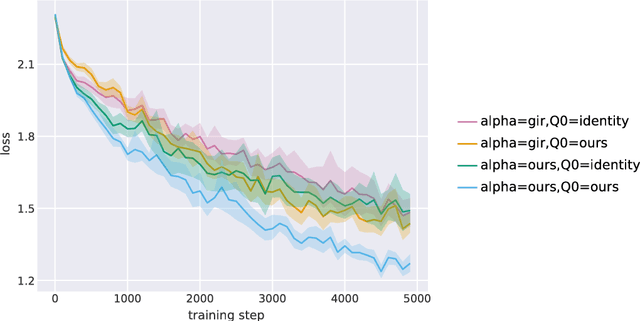
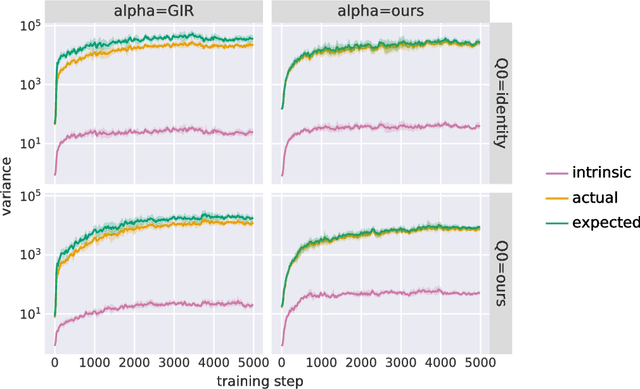
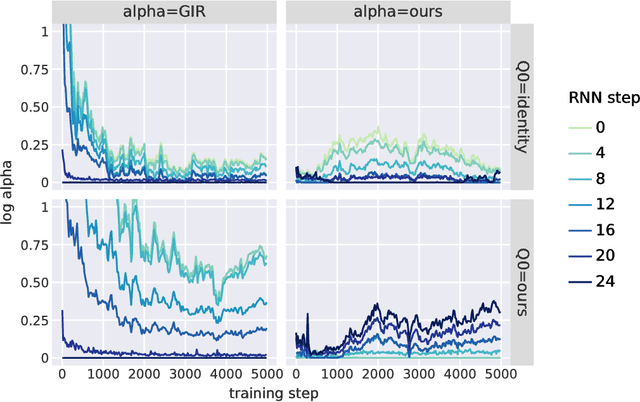
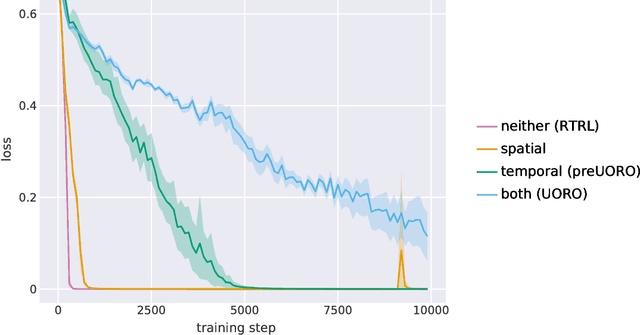
The recently proposed Unbiased Online Recurrent Optimization algorithm (UORO, arXiv:1702.05043) uses an unbiased approximation of RTRL to achieve fully online gradient-based learning in RNNs. In this work we analyze the variance of the gradient estimate computed by UORO, and propose several possible changes to the method which reduce this variance both in theory and practice. We also contribute significantly to the theoretical and intuitive understanding of UORO (and its existing variance reduction technique), and demonstrate a fundamental connection between its gradient estimate and the one that would be computed by REINFORCE if small amounts of noise were added to the RNN's hidden units.
Harmonic Recomposition using Conditional Autoregressive Modeling
Nov 18, 2018
We demonstrate a conditional autoregressive pipeline for efficient music recomposition, based on methods presented in van den Oord et al.(2017). Recomposition (Casal & Casey, 2010) focuses on reworking existing musical pieces, adhering to structure at a high level while also re-imagining other aspects of the work. This can involve reuse of pre-existing themes or parts of the original piece, while also requiring the flexibility to generate new content at different levels of granularity. Applying the aforementioned modeling pipeline to recomposition, we show diverse and structured generation conditioned on chord sequence annotations.