 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscovering Latent Groups for Robust Classification
Jun 22, 2026Machine learning models exploit spurious correlations, achieving high average accuracy but failing disproportionately on underrepresented subgroups. Existing methods address this by adjusting network parameters, guided either by subgroup annotations or inferred pseudo-group labels. Yet at inference, these methods produce only a class prediction, with no insight into a sample's latent subgroup. We propose neural classification trees (NCT), a framework that achieves robustness by encoding subgroup structure in its tree-shaped architecture. By routing each sample to an "easy" or "hard" node of this tree -- based on prediction correctness -- and reusing these routes as pseudo-labels for the next iteration, NCT disentangles conflicting subgroups, without requiring subgroup supervision. We evaluate NCT on five benchmarks spanning binary and multi-class spurious correlations. Our experiments show that the learned tree topology provides strong interpretability by consistently isolating minority subgroups, which provides a transparent mapping between the model architecture and the data's latent group structure, while yielding competitive robustness with state-of-the-art methods.
Behaviour Discovery and Attribution for Explainable Reinforcement Learning
Mar 19, 2025Explaining the decisions made by reinforcement learning (RL) agents is critical for building trust and ensuring reliability in real-world applications. Traditional approaches to explainability often rely on saliency analysis, which can be limited in providing actionable insights. Recently, there has been growing interest in attributing RL decisions to specific trajectories within a dataset. However, these methods often generalize explanations to long trajectories, potentially involving multiple distinct behaviors. Often, providing multiple more fine grained explanations would improve clarity. In this work, we propose a framework for behavior discovery and action attribution to behaviors in offline RL trajectories. Our method identifies meaningful behavioral segments, enabling more precise and granular explanations associated with high level agent behaviors. This approach is adaptable across diverse environments with minimal modifications, offering a scalable and versatile solution for behavior discovery and attribution for explainable RL.
Empowering Clinicians with Medical Decision Transformers: A Framework for Sepsis Treatment
Jul 28, 2024Offline reinforcement learning has shown promise for solving tasks in safety-critical settings, such as clinical decision support. Its application, however, has been limited by the lack of interpretability and interactivity for clinicians. To address these challenges, we propose the medical decision transformer (MeDT), a novel and versatile framework based on the goal-conditioned reinforcement learning paradigm for sepsis treatment recommendation. MeDT uses the decision transformer architecture to learn a policy for drug dosage recommendation. During offline training, MeDT utilizes collected treatment trajectories to predict administered treatments for each time step, incorporating known treatment outcomes, target acuity scores, past treatment decisions, and current and past medical states. This analysis enables MeDT to capture complex dependencies among a patient's medical history, treatment decisions, outcomes, and short-term effects on stability. Our proposed conditioning uses acuity scores to address sparse reward issues and to facilitate clinician-model interactions, enhancing decision-making. Following training, MeDT can generate tailored treatment recommendations by conditioning on the desired positive outcome (survival) and user-specified short-term stability improvements. We carry out rigorous experiments on data from the MIMIC-III dataset and use off-policy evaluation to demonstrate that MeDT recommends interventions that outperform or are competitive with existing offline reinforcement learning methods while enabling a more interpretable, personalized and clinician-directed approach.
On the Limits of Multi-modal Meta-Learning with Auxiliary Task Modulation Using Conditional Batch Normalization
May 29, 2024


Few-shot learning aims to learn representations that can tackle novel tasks given a small number of examples. Recent studies show that cross-modal learning can improve representations for few-shot classification. More specifically, language is a rich modality that can be used to guide visual learning. In this work, we experiment with a multi-modal architecture for few-shot learning that consists of three components: a classifier, an auxiliary network, and a bridge network. While the classifier performs the main classification task, the auxiliary network learns to predict language representations from the same input, and the bridge network transforms high-level features of the auxiliary network into modulation parameters for layers of the few-shot classifier using conditional batch normalization. The bridge should encourage a form of lightweight semantic alignment between language and vision which could be useful for the classifier. However, after evaluating the proposed approach on two popular few-shot classification benchmarks we find that a) the improvements do not reproduce across benchmarks, and b) when they do, the improvements are due to the additional compute and parameters introduced by the bridge network. We contribute insights and recommendations for future work in multi-modal meta-learning, especially when using language representations.
Accounting for Variance in Machine Learning Benchmarks
Mar 01, 2021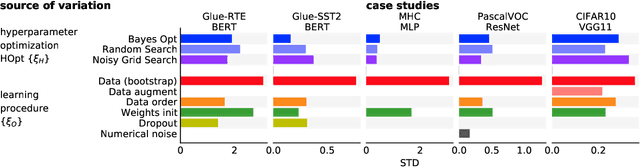
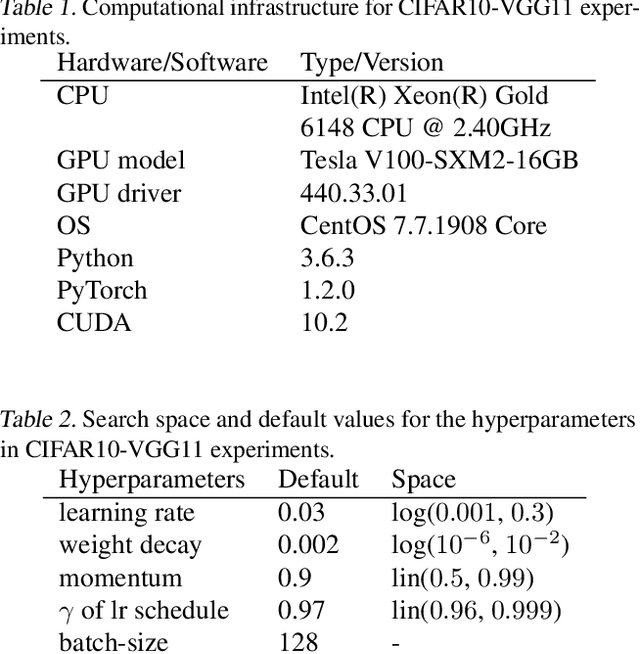
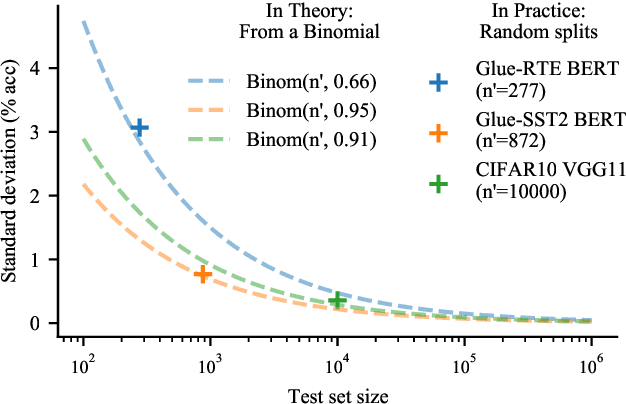
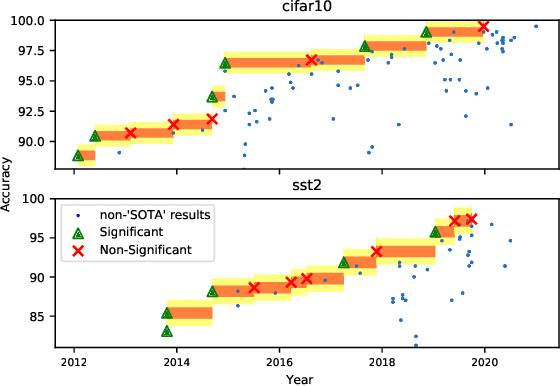
Strong empirical evidence that one machine-learning algorithm A outperforms another one B ideally calls for multiple trials optimizing the learning pipeline over sources of variation such as data sampling, data augmentation, parameter initialization, and hyperparameters choices. This is prohibitively expensive, and corners are cut to reach conclusions. We model the whole benchmarking process, revealing that variance due to data sampling, parameter initialization and hyperparameter choice impact markedly the results. We analyze the predominant comparison methods used today in the light of this variance. We show a counter-intuitive result that adding more sources of variation to an imperfect estimator approaches better the ideal estimator at a 51 times reduction in compute cost. Building on these results, we study the error rate of detecting improvements, on five different deep-learning tasks/architectures. This study leads us to propose recommendations for performance comparisons.
HighRes-net: Recursive Fusion for Multi-Frame Super-Resolution of Satellite Imagery
Feb 15, 2020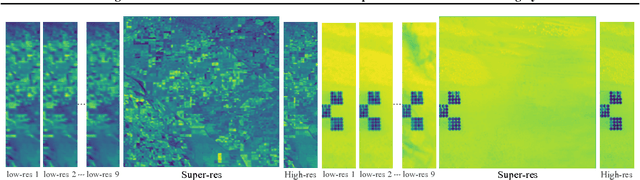
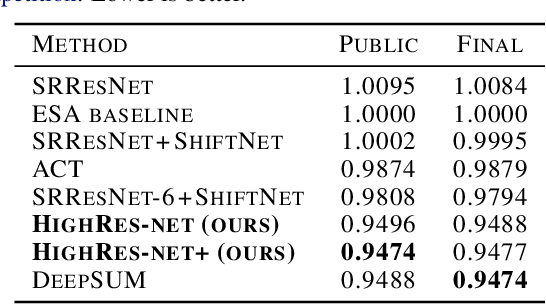
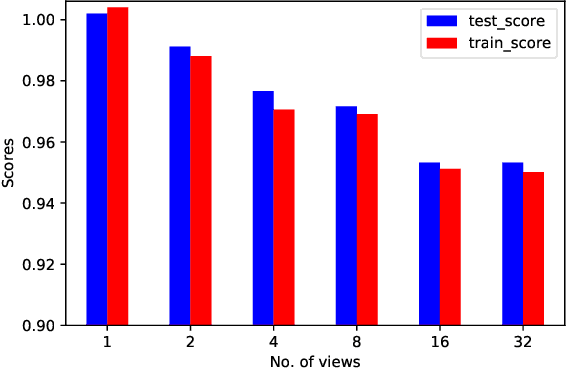
Generative deep learning has sparked a new wave of Super-Resolution (SR) algorithms that enhance single images with impressive aesthetic results, albeit with imaginary details. Multi-frame Super-Resolution (MFSR) offers a more grounded approach to the ill-posed problem, by conditioning on multiple low-resolution views. This is important for satellite monitoring of human impact on the planet -- from deforestation, to human rights violations -- that depend on reliable imagery. To this end, we present HighRes-net, the first deep learning approach to MFSR that learns its sub-tasks in an end-to-end fashion: (i) co-registration, (ii) fusion, (iii) up-sampling, and (iv) registration-at-the-loss. Co-registration of low-resolution views is learned implicitly through a reference-frame channel, with no explicit registration mechanism. We learn a global fusion operator that is applied recursively on an arbitrary number of low-resolution pairs. We introduce a registered loss, by learning to align the SR output to a ground-truth through ShiftNet. We show that by learning deep representations of multiple views, we can super-resolve low-resolution signals and enhance Earth Observation data at scale. Our approach recently topped the European Space Agency's MFSR competition on real-world satellite imagery.
An Empirical Study of Batch Normalization and Group Normalization in Conditional Computation
Jul 31, 2019


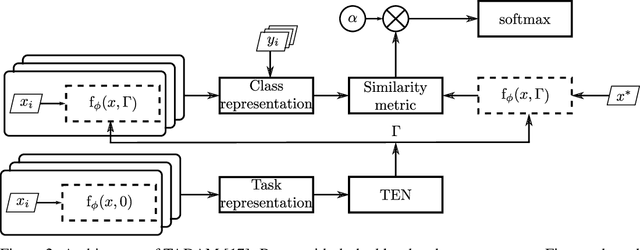
Batch normalization has been widely used to improve optimization in deep neural networks. While the uncertainty in batch statistics can act as a regularizer, using these dataset statistics specific to the training set impairs generalization in certain tasks. Recently, alternative methods for normalizing feature activations in neural networks have been proposed. Among them, group normalization has been shown to yield similar, in some domains even superior performance to batch normalization. All these methods utilize a learned affine transformation after the normalization operation to increase representational power. Methods used in conditional computation define the parameters of these transformations as learnable functions of conditioning information. In this work, we study whether and where the conditional formulation of group normalization can improve generalization compared to conditional batch normalization. We evaluate performances on the tasks of visual question answering, few-shot learning, and conditional image generation.
Towards Deep Conversational Recommendations
Dec 18, 2018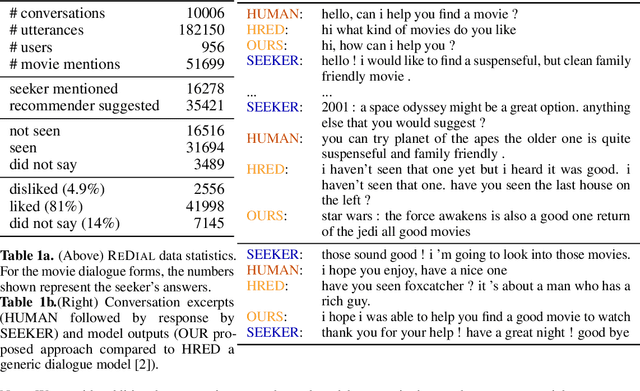
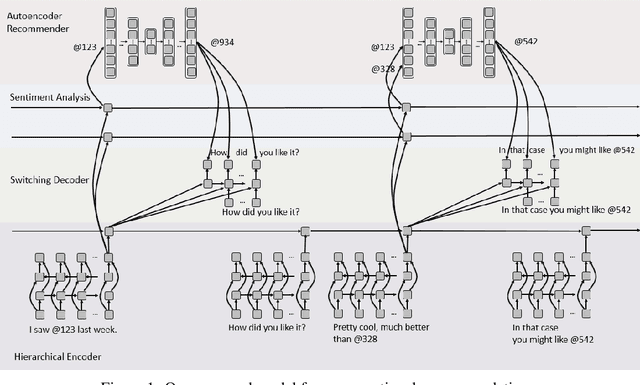


There has been growing interest in using neural networks and deep learning techniques to create dialogue systems. Conversational recommendation is an interesting setting for the scientific exploration of dialogue with natural language as the associated discourse involves goal-driven dialogue that often transforms naturally into more free-form chat. This paper provides two contributions. First, until now there has been no publicly available large-scale dataset consisting of real-world dialogues centered around recommendations. To address this issue and to facilitate our exploration here, we have collected ReDial, a dataset consisting of over 10,000 conversations centered around the theme of providing movie recommendations. We make this data available to the community for further research. Second, we use this dataset to explore multiple facets of conversational recommendations. In particular we explore new neural architectures, mechanisms, and methods suitable for composing conversational recommendation systems. Our dataset allows us to systematically probe model sub-components addressing different parts of the overall problem domain ranging from: sentiment analysis and cold-start recommendation generation to detailed aspects of how natural language is used in this setting in the real world. We combine such sub-components into a full-blown dialogue system and examine its behavior.
FigureQA: An Annotated Figure Dataset for Visual Reasoning
Feb 22, 2018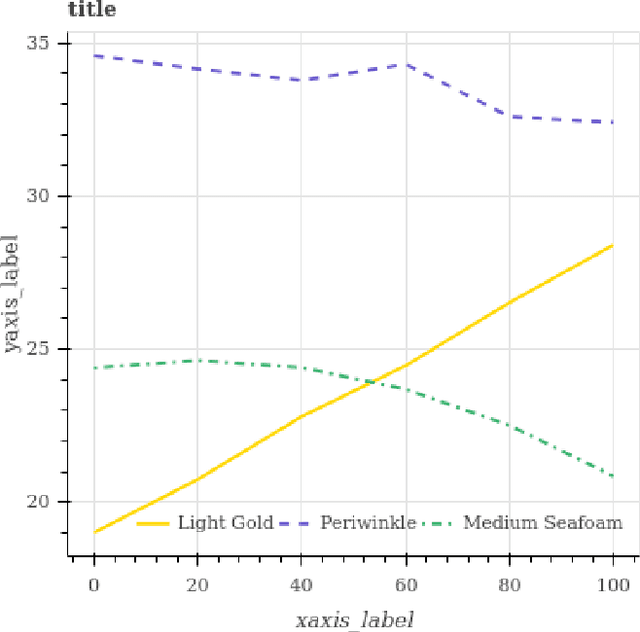


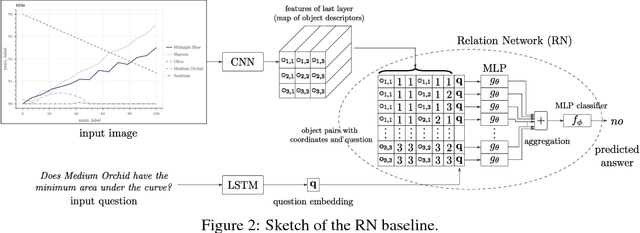
We introduce FigureQA, a visual reasoning corpus of over one million question-answer pairs grounded in over 100,000 images. The images are synthetic, scientific-style figures from five classes: line plots, dot-line plots, vertical and horizontal bar graphs, and pie charts. We formulate our reasoning task by generating questions from 15 templates; questions concern various relationships between plot elements and examine characteristics like the maximum, the minimum, area-under-the-curve, smoothness, and intersection. To resolve, such questions often require reference to multiple plot elements and synthesis of information distributed spatially throughout a figure. To facilitate the training of machine learning systems, the corpus also includes side data that can be used to formulate auxiliary objectives. In particular, we provide the numerical data used to generate each figure as well as bounding-box annotations for all plot elements. We study the proposed visual reasoning task by training several models, including the recently proposed Relation Network as a strong baseline. Preliminary results indicate that the task poses a significant machine learning challenge. We envision FigureQA as a first step towards developing models that can intuitively recognize patterns from visual representations of data.
ChatPainter: Improving Text to Image Generation using Dialogue
Feb 22, 2018

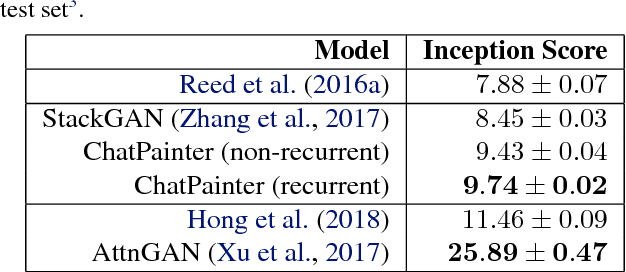
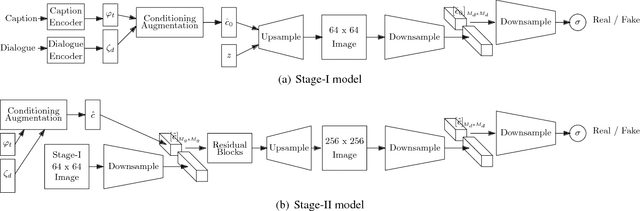
Synthesizing realistic images from text descriptions on a dataset like Microsoft Common Objects in Context (MS COCO), where each image can contain several objects, is a challenging task. Prior work has used text captions to generate images. However, captions might not be informative enough to capture the entire image and insufficient for the model to be able to understand which objects in the images correspond to which words in the captions. We show that adding a dialogue that further describes the scene leads to significant improvement in the inception score and in the quality of generated images on the MS COCO dataset.