 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnlearning in- vs. out-of-distribution data in LLMs under gradient-based method
Nov 07, 2024



Machine unlearning aims to solve the problem of removing the influence of selected training examples from a learned model. Despite the increasing attention to this problem, it remains an open research question how to evaluate unlearning in large language models (LLMs), and what are the critical properties of the data to be unlearned that affect the quality and efficiency of unlearning. This work formalizes a metric to evaluate unlearning quality in generative models, and uses it to assess the trade-offs between unlearning quality and performance. We demonstrate that unlearning out-of-distribution examples requires more unlearning steps but overall presents a better trade-off overall. For in-distribution examples, however, we observe a rapid decay in performance as unlearning progresses. We further evaluate how example's memorization and difficulty affect unlearning under a classical gradient ascent-based approach.
AI-Assisted Assessment of Coding Practices in Modern Code Review
May 22, 2024



Modern code review is a process in which an incremental code contribution made by a code author is reviewed by one or more peers before it is committed to the version control system. An important element of modern code review is verifying that code contributions adhere to best practices. While some of these best practices can be automatically verified, verifying others is commonly left to human reviewers. This paper reports on the development, deployment, and evaluation of AutoCommenter, a system backed by a large language model that automatically learns and enforces coding best practices. We implemented AutoCommenter for four programming languages (C++, Java, Python, and Go) and evaluated its performance and adoption in a large industrial setting. Our evaluation shows that an end-to-end system for learning and enforcing coding best practices is feasible and has a positive impact on the developer workflow. Additionally, this paper reports on the challenges associated with deploying such a system to tens of thousands of developers and the corresponding lessons learned.
Meta-Dataset: A Dataset of Datasets for Learning to Learn from Few Examples
Mar 07, 2019
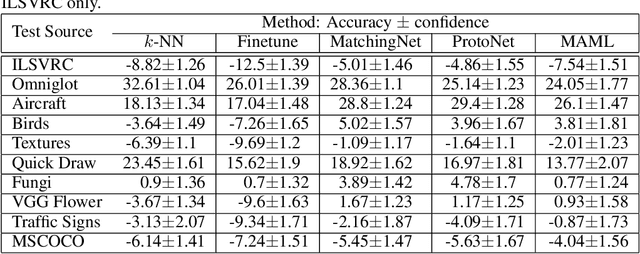

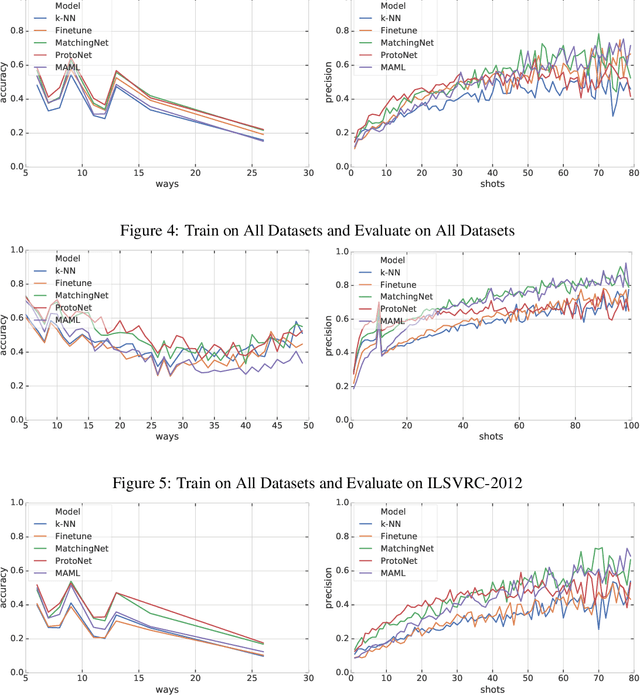
Few-shot classification refers to learning a classifier for new classes given only a few examples. While a plethora of models have emerged to tackle this recently, we find the current procedure and datasets that are used to systematically assess progress in this setting lacking. To address this, we propose Meta-Dataset: a new benchmark for training and evaluating few-shot classifiers that is large-scale, consists of multiple datasets, and presents more natural and realistic tasks. The aim is to measure the ability of state-of-the-art models to leverage diverse sources of data to achieve higher generalization, and to evaluate that generalization ability in a more challenging setting. We additionally measure robustness of current methods to variations in the number of available examples and the number of classes. Finally our extensive empirical evaluation leads us to identify weaknesses in Prototypical Networks and MAML, two popular few-shot classification methods, and to propose a new method, Proto-MAML, which achieves improved performance on our benchmark.
Automatic differentiation in ML: Where we are and where we should be going
Oct 26, 2018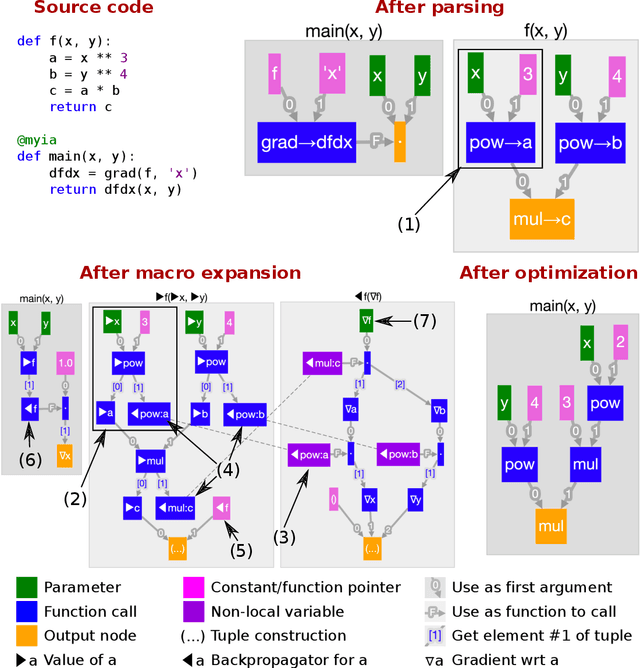
We review the current state of automatic differentiation (AD) for array programming in machine learning (ML), including the different approaches such as operator overloading (OO) and source transformation (ST) used for AD, graph-based intermediate representations for programs, and source languages. Based on these insights, we introduce a new graph-based intermediate representation (IR) which specifically aims to efficiently support fully-general AD for array programming. Unlike existing dataflow programming representations in ML frameworks, our IR naturally supports function calls, higher-order functions and recursion, making ML models easier to implement. The ability to represent closures allows us to perform AD using ST without a tape, making the resulting derivative (adjoint) program amenable to ahead-of-time optimization using tools from functional language compilers, and enabling higher-order derivatives. Lastly, we introduce a proof of concept compiler toolchain called Myia which uses a subset of Python as a front end.
Theano: A Python framework for fast computation of mathematical expressions
May 09, 2016



Theano is a Python library that allows to define, optimize, and evaluate mathematical expressions involving multi-dimensional arrays efficiently. Since its introduction, it has been one of the most used CPU and GPU mathematical compilers - especially in the machine learning community - and has shown steady performance improvements. Theano is being actively and continuously developed since 2008, multiple frameworks have been built on top of it and it has been used to produce many state-of-the-art machine learning models. The present article is structured as follows. Section I provides an overview of the Theano software and its community. Section II presents the principal features of Theano and how to use them, and compares them with other similar projects. Section III focuses on recently-introduced functionalities and improvements. Section IV compares the performance of Theano against Torch7 and TensorFlow on several machine learning models. Section V discusses current limitations of Theano and potential ways of improving it.
EmoNets: Multimodal deep learning approaches for emotion recognition in video
Mar 30, 2015

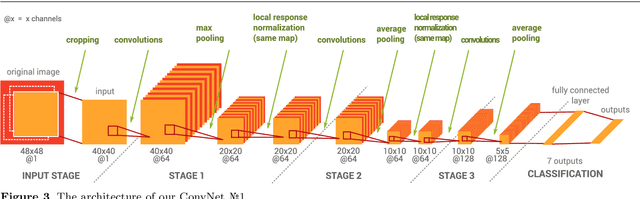
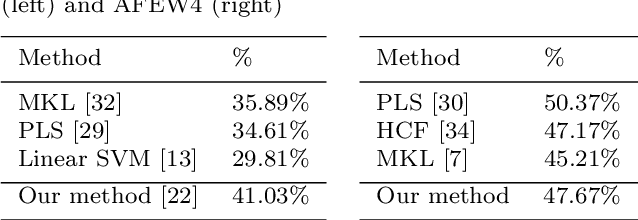
The task of the emotion recognition in the wild (EmotiW) Challenge is to assign one of seven emotions to short video clips extracted from Hollywood style movies. The videos depict acted-out emotions under realistic conditions with a large degree of variation in attributes such as pose and illumination, making it worthwhile to explore approaches which consider combinations of features from multiple modalities for label assignment. In this paper we present our approach to learning several specialist models using deep learning techniques, each focusing on one modality. Among these are a convolutional neural network, focusing on capturing visual information in detected faces, a deep belief net focusing on the representation of the audio stream, a K-Means based "bag-of-mouths" model, which extracts visual features around the mouth region and a relational autoencoder, which addresses spatio-temporal aspects of videos. We explore multiple methods for the combination of cues from these modalities into one common classifier. This achieves a considerably greater accuracy than predictions from our strongest single-modality classifier. Our method was the winning submission in the 2013 EmotiW challenge and achieved a test set accuracy of 47.67% on the 2014 dataset.
Pylearn2: a machine learning research library
Aug 20, 2013Pylearn2 is a machine learning research library. This does not just mean that it is a collection of machine learning algorithms that share a common API; it means that it has been designed for flexibility and extensibility in order to facilitate research projects that involve new or unusual use cases. In this paper we give a brief history of the library, an overview of its basic philosophy, a summary of the library's architecture, and a description of how the Pylearn2 community functions socially.
Theano: new features and speed improvements
Nov 23, 2012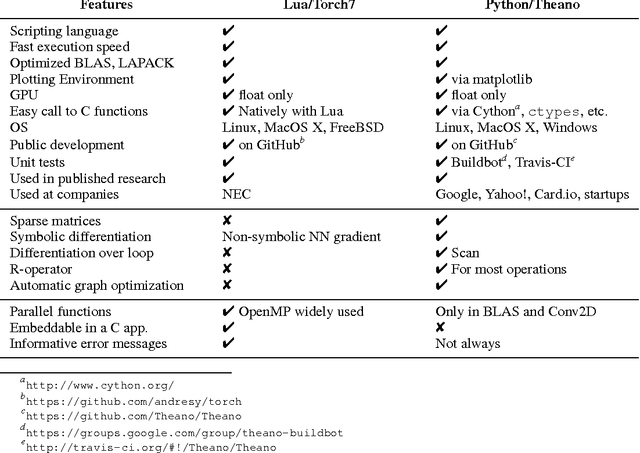
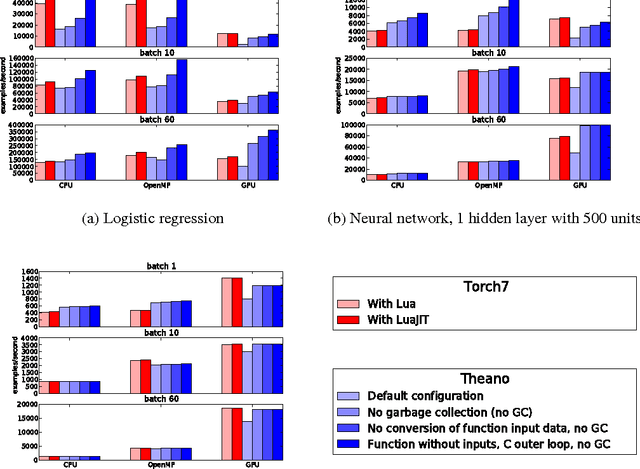
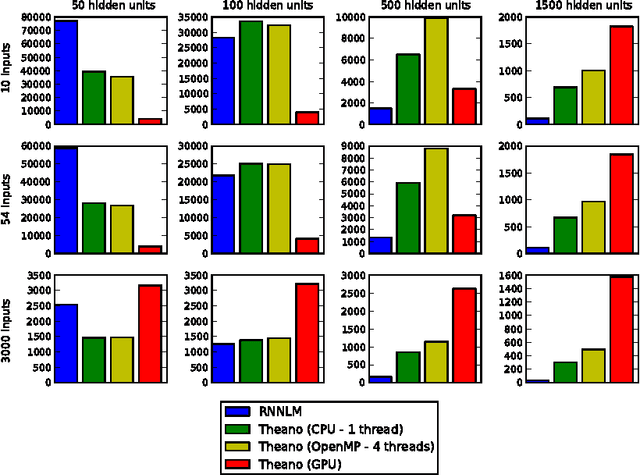
Theano is a linear algebra compiler that optimizes a user's symbolically-specified mathematical computations to produce efficient low-level implementations. In this paper, we present new features and efficiency improvements to Theano, and benchmarks demonstrating Theano's performance relative to Torch7, a recently introduced machine learning library, and to RNNLM, a C++ library targeted at recurrent neural networks.