 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParametric and Multivariate Uncertainty Calibration for Regression and Object Detection
Jul 04, 2022
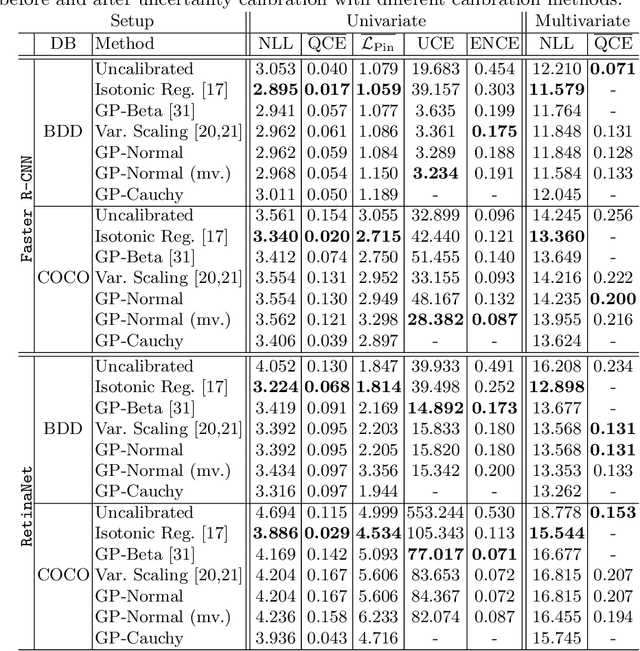
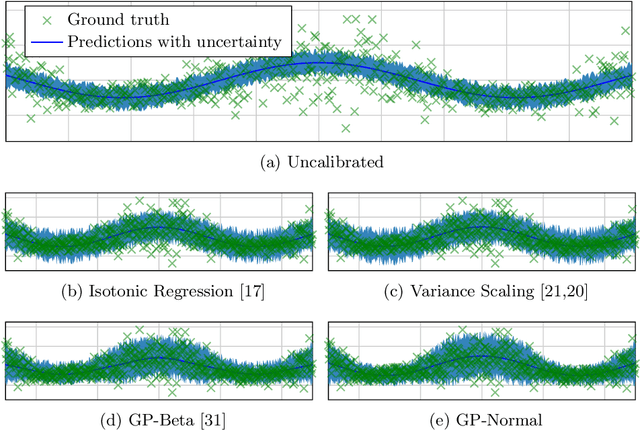
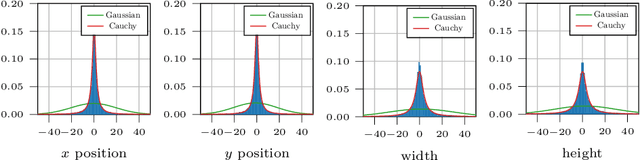
Reliable spatial uncertainty evaluation of object detection models is of special interest and has been subject of recent work. In this work, we review the existing definitions for uncertainty calibration of probabilistic regression tasks. We inspect the calibration properties of common detection networks and extend state-of-the-art recalibration methods. Our methods use a Gaussian process (GP) recalibration scheme that yields parametric distributions as output (e.g. Gaussian or Cauchy). The usage of GP recalibration allows for a local (conditional) uncertainty calibration by capturing dependencies between neighboring samples. The use of parametric distributions such as as Gaussian allows for a simplified adaption of calibration in subsequent processes, e.g., for Kalman filtering in the scope of object tracking. In addition, we use the GP recalibration scheme to perform covariance estimation which allows for post-hoc introduction of local correlations between the output quantities, e.g., position, width, or height in object detection. To measure the joint calibration of multivariate and possibly correlated data, we introduce the quantile calibration error which is based on the Mahalanobis distance between the predicted distribution and the ground truth to determine whether the ground truth is within a predicted quantile. Our experiments show that common detection models overestimate the spatial uncertainty in comparison to the observed error. We show that the simple Isotonic Regression recalibration method is sufficient to achieve a good uncertainty quantification in terms of calibrated quantiles. In contrast, if normal distributions are required for subsequent processes, our GP-Normal recalibration method yields the best results. Finally, we show that our covariance estimation method is able to achieve best calibration results for joint multivariate calibration.
Confidence Calibration for Object Detection and Segmentation
Mar 02, 2022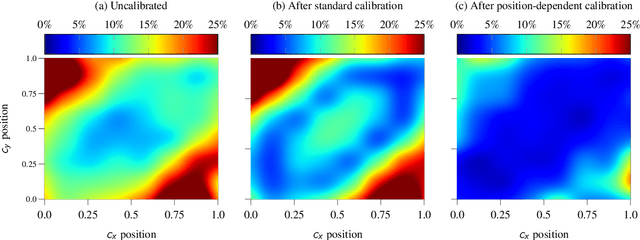
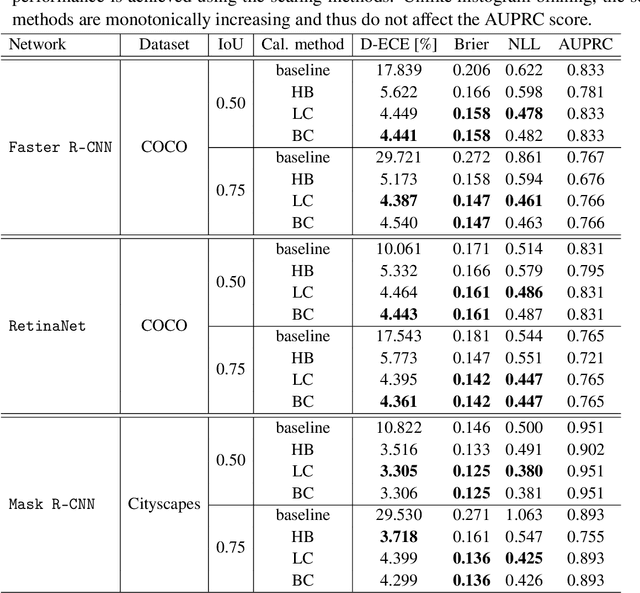
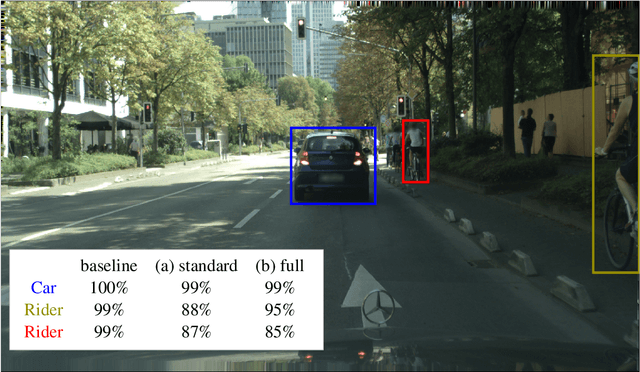
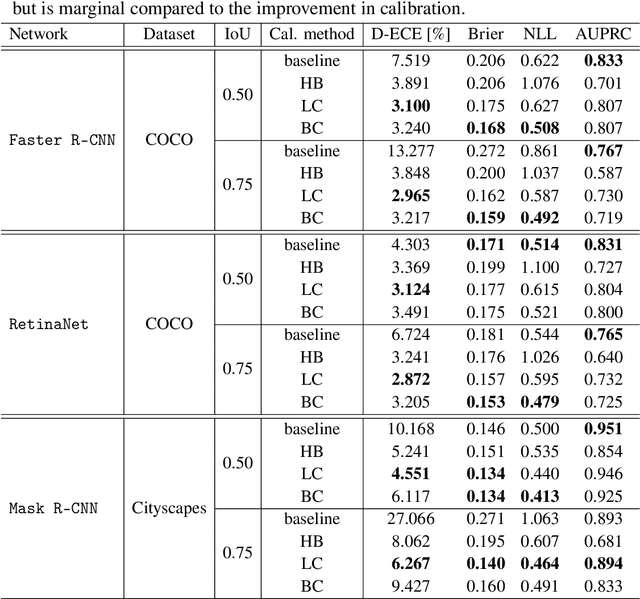
Calibrated confidence estimates obtained from neural networks are crucial, particularly for safety-critical applications such as autonomous driving or medical image diagnosis. However, although the task of confidence calibration has been investigated on classification problems, thorough investigations on object detection and segmentation problems are still missing. Therefore, we focus on the investigation of confidence calibration for object detection and segmentation models in this chapter. We introduce the concept of multivariate confidence calibration that is an extension of well-known calibration methods to the task of object detection and segmentation. This allows for an extended confidence calibration that is also aware of additional features such as bounding box/pixel position, shape information, etc. Furthermore, we extend the expected calibration error (ECE) to measure miscalibration of object detection and segmentation models. We examine several network architectures on MS COCO as well as on Cityscapes and show that especially object detection as well as instance segmentation models are intrinsically miscalibrated given the introduced definition of calibration. Using our proposed calibration methods, we have been able to improve calibration so that it also has a positive impact on the quality of segmentation masks as well.
Bayesian Confidence Calibration for Epistemic Uncertainty Modelling
Sep 21, 2021
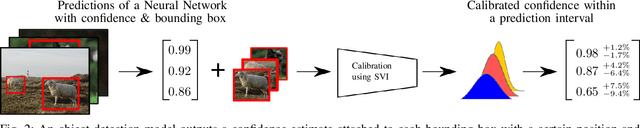
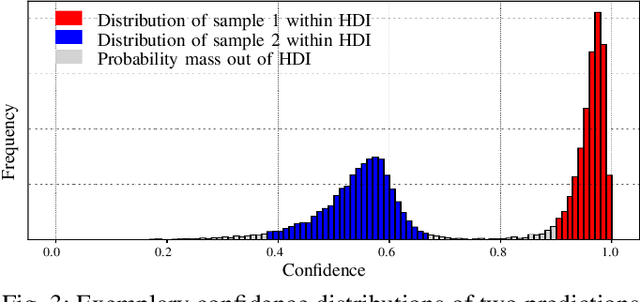
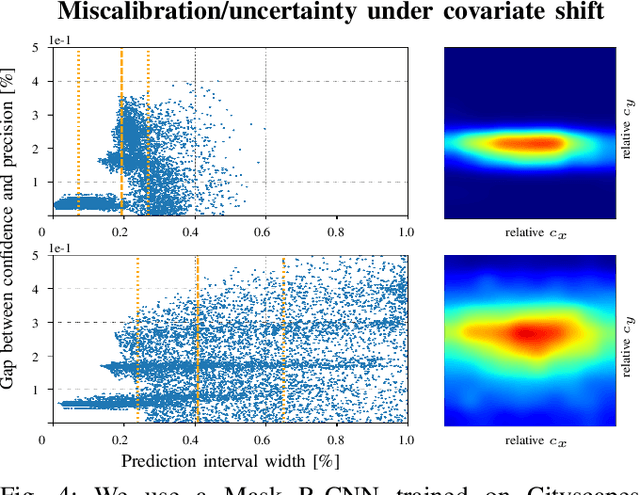
Modern neural networks have found to be miscalibrated in terms of confidence calibration, i.e., their predicted confidence scores do not reflect the observed accuracy or precision. Recent work has introduced methods for post-hoc confidence calibration for classification as well as for object detection to address this issue. Especially in safety critical applications, it is crucial to obtain a reliable self-assessment of a model. But what if the calibration method itself is uncertain, e.g., due to an insufficient knowledge base? We introduce Bayesian confidence calibration - a framework to obtain calibrated confidence estimates in conjunction with an uncertainty of the calibration method. Commonly, Bayesian neural networks (BNN) are used to indicate a network's uncertainty about a certain prediction. BNNs are interpreted as neural networks that use distributions instead of weights for inference. We transfer this idea of using distributions to confidence calibration. For this purpose, we use stochastic variational inference to build a calibration mapping that outputs a probability distribution rather than a single calibrated estimate. Using this approach, we achieve state-of-the-art calibration performance for object detection calibration. Finally, we show that this additional type of uncertainty can be used as a sufficient criterion for covariate shift detection. All code is open source and available at https://github.com/EFS-OpenSource/calibration-framework.
On Feature Relevance Uncertainty: A Monte Carlo Dropout Sampling Approach
Aug 04, 2020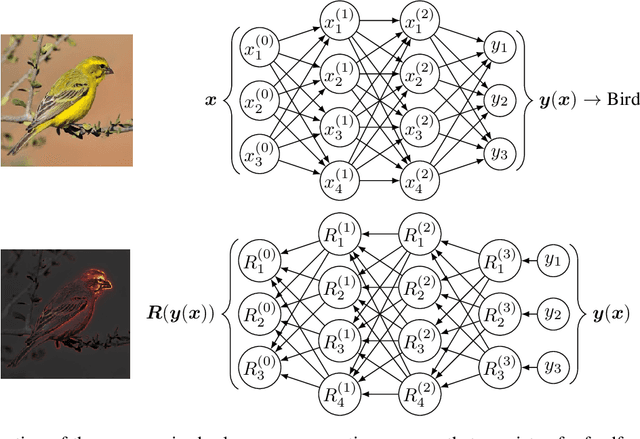
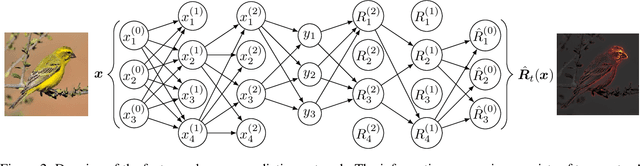


Understanding decisions made by neural networks is key for the deployment of intelligent systems in real world applications. However, the opaque decision making process of these systems is a disadvantage where interpretability is essential. Many feature-based explanation techniques have been introduced over the last few years in the field of machine learning to better understand decisions made by neural networks and have become an important component to verify their reasoning capabilities. However, existing methods do not allow statements to be made about the uncertainty regarding a feature's relevance for the prediction. In this paper, we introduce Monte Carlo Relevance Propagation (MCRP) for feature relevance uncertainty estimation. A simple but powerful method based on Monte Carlo estimation of the feature relevance distribution to compute feature relevance uncertainty scores that allow a deeper understanding of a neural network's perception and reasoning.
Dota 2 with Large Scale Deep Reinforcement Learning
Dec 13, 2019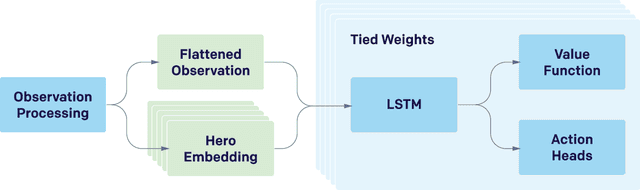
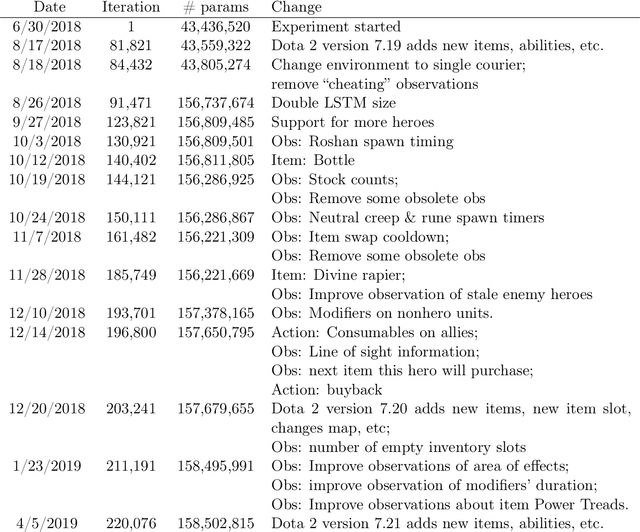
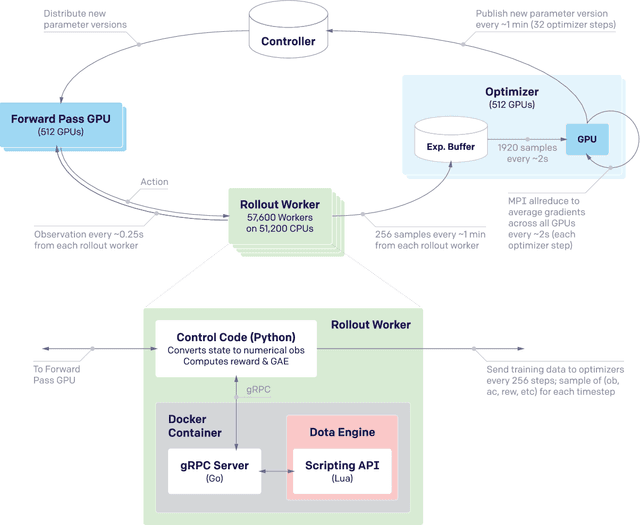
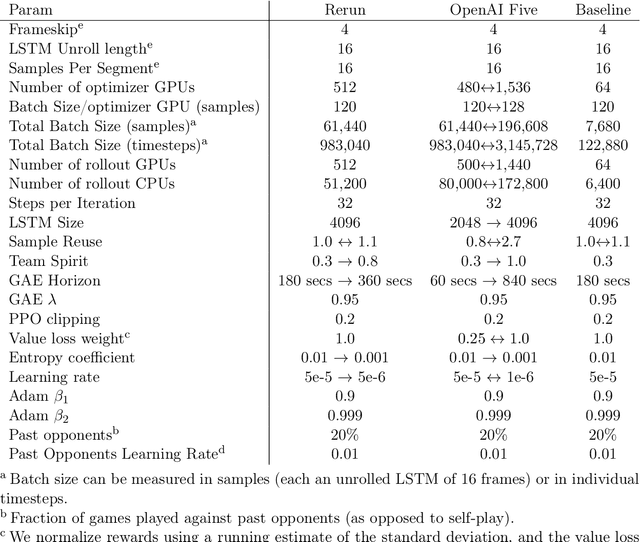
On April 13th, 2019, OpenAI Five became the first AI system to defeat the world champions at an esports game. The game of Dota 2 presents novel challenges for AI systems such as long time horizons, imperfect information, and complex, continuous state-action spaces, all challenges which will become increasingly central to more capable AI systems. OpenAI Five leveraged existing reinforcement learning techniques, scaled to learn from batches of approximately 2 million frames every 2 seconds. We developed a distributed training system and tools for continual training which allowed us to train OpenAI Five for 10 months. By defeating the Dota 2 world champion (Team OG), OpenAI Five demonstrates that self-play reinforcement learning can achieve superhuman performance on a difficult task.
Solving Rubik's Cube with a Robot Hand
Oct 16, 2019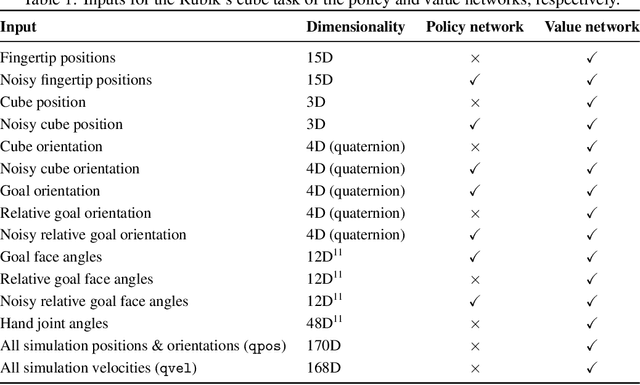
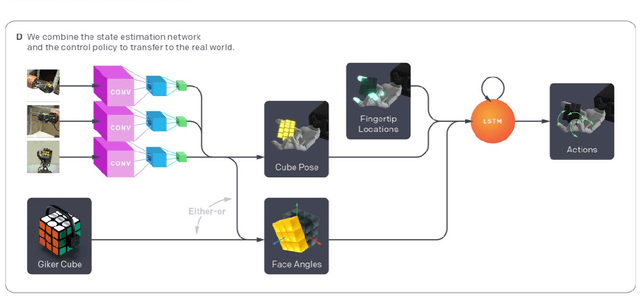
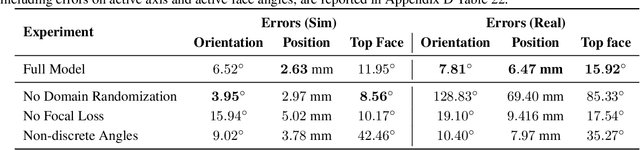

We demonstrate that models trained only in simulation can be used to solve a manipulation problem of unprecedented complexity on a real robot. This is made possible by two key components: a novel algorithm, which we call automatic domain randomization (ADR) and a robot platform built for machine learning. ADR automatically generates a distribution over randomized environments of ever-increasing difficulty. Control policies and vision state estimators trained with ADR exhibit vastly improved sim2real transfer. For control policies, memory-augmented models trained on an ADR-generated distribution of environments show clear signs of emergent meta-learning at test time. The combination of ADR with our custom robot platform allows us to solve a Rubik's cube with a humanoid robot hand, which involves both control and state estimation problems. Videos summarizing our results are available: https://openai.com/blog/solving-rubiks-cube/
Learning Dexterous In-Hand Manipulation
Jan 18, 2019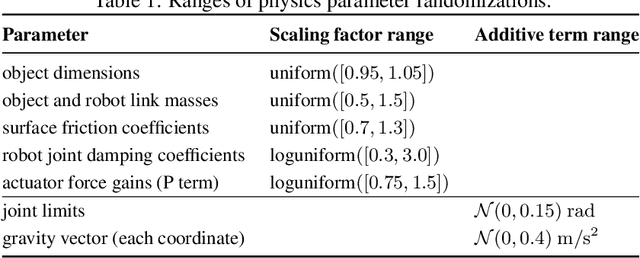
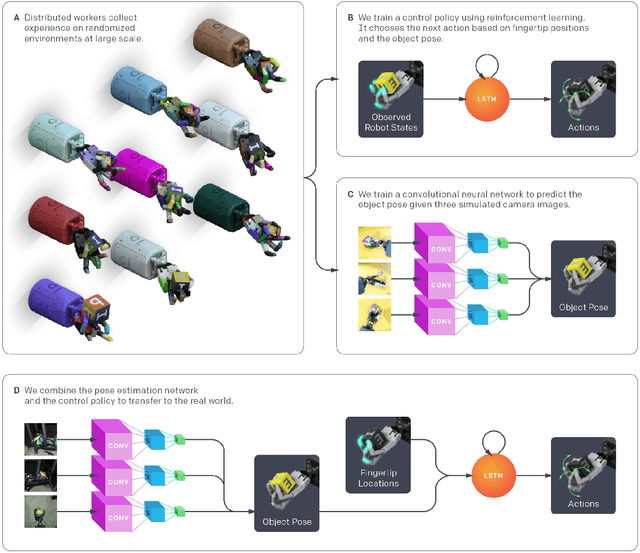
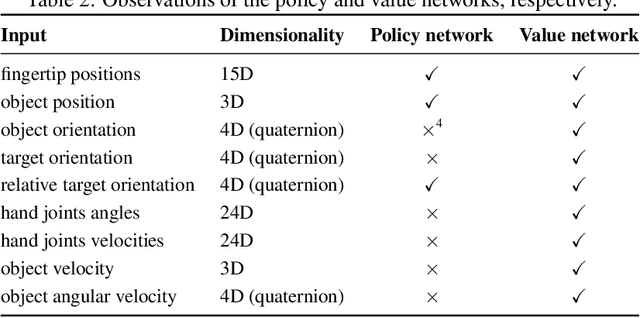

We use reinforcement learning (RL) to learn dexterous in-hand manipulation policies which can perform vision-based object reorientation on a physical Shadow Dexterous Hand. The training is performed in a simulated environment in which we randomize many of the physical properties of the system like friction coefficients and an object's appearance. Our policies transfer to the physical robot despite being trained entirely in simulation. Our method does not rely on any human demonstrations, but many behaviors found in human manipulation emerge naturally, including finger gaiting, multi-finger coordination, and the controlled use of gravity. Our results were obtained using the same distributed RL system that was used to train OpenAI Five. We also include a video of our results: https://youtu.be/jwSbzNHGflM
Domain Randomization and Generative Models for Robotic Grasping
Apr 03, 2018
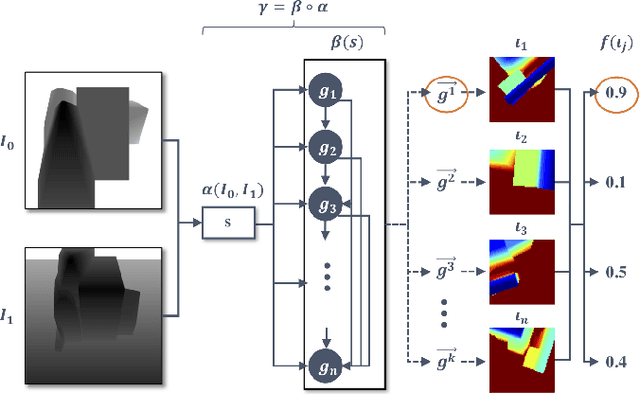
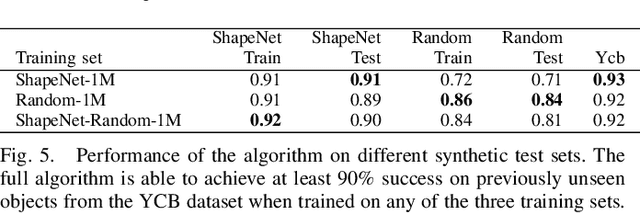
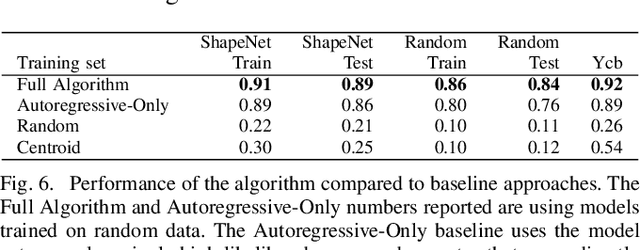
Deep learning-based robotic grasping has made significant progress thanks to algorithmic improvements and increased data availability. However, state-of-the-art models are often trained on as few as hundreds or thousands of unique object instances, and as a result generalization can be a challenge. In this work, we explore a novel data generation pipeline for training a deep neural network to perform grasp planning that applies the idea of domain randomization to object synthesis. We generate millions of unique, unrealistic procedurally generated objects, and train a deep neural network to perform grasp planning on these objects. Since the distribution of successful grasps for a given object can be highly multimodal, we propose an autoregressive grasp planning model that maps sensor inputs of a scene to a probability distribution over possible grasps. This model allows us to sample grasps efficiently at test time (or avoid sampling entirely). We evaluate our model architecture and data generation pipeline in simulation and the real world. We find we can achieve a $>$90% success rate on previously unseen realistic objects at test time in simulation despite having only been trained on random objects. We also demonstrate an 80% success rate on real-world grasp attempts despite having only been trained on random simulated objects.
Multi-Goal Reinforcement Learning: Challenging Robotics Environments and Request for Research
Mar 10, 2018

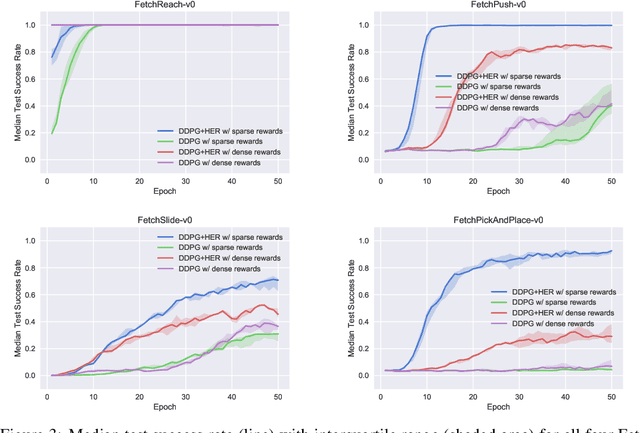
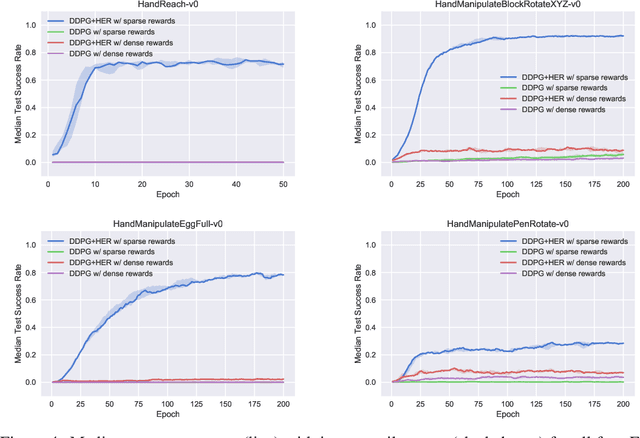
The purpose of this technical report is two-fold. First of all, it introduces a suite of challenging continuous control tasks (integrated with OpenAI Gym) based on currently existing robotics hardware. The tasks include pushing, sliding and pick & place with a Fetch robotic arm as well as in-hand object manipulation with a Shadow Dexterous Hand. All tasks have sparse binary rewards and follow a Multi-Goal Reinforcement Learning (RL) framework in which an agent is told what to do using an additional input. The second part of the paper presents a set of concrete research ideas for improving RL algorithms, most of which are related to Multi-Goal RL and Hindsight Experience Replay.
Hindsight Experience Replay
Feb 23, 2018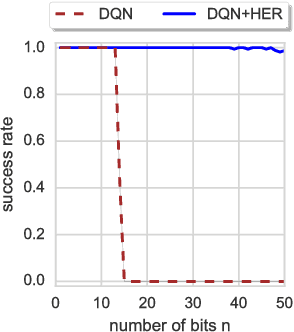
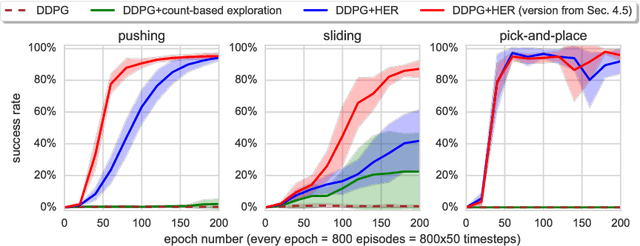
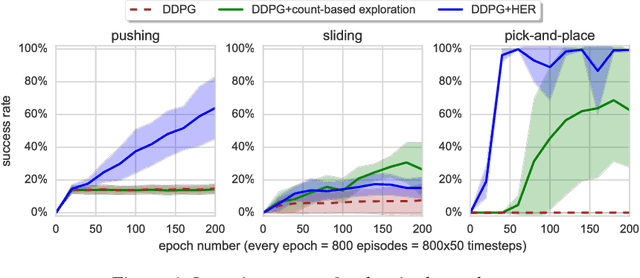
Dealing with sparse rewards is one of the biggest challenges in Reinforcement Learning (RL). We present a novel technique called Hindsight Experience Replay which allows sample-efficient learning from rewards which are sparse and binary and therefore avoid the need for complicated reward engineering. It can be combined with an arbitrary off-policy RL algorithm and may be seen as a form of implicit curriculum. We demonstrate our approach on the task of manipulating objects with a robotic arm. In particular, we run experiments on three different tasks: pushing, sliding, and pick-and-place, in each case using only binary rewards indicating whether or not the task is completed. Our ablation studies show that Hindsight Experience Replay is a crucial ingredient which makes training possible in these challenging environments. We show that our policies trained on a physics simulation can be deployed on a physical robot and successfully complete the task.