 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntroducing Milabench: Benchmarking Accelerators for AI
Nov 18, 2024



AI workloads, particularly those driven by deep learning, are introducing novel usage patterns to high-performance computing (HPC) systems that are not comprehensively captured by standard HPC benchmarks. As one of the largest academic research centers dedicated to deep learning, Mila identified the need to develop a custom benchmarking suite to address the diverse requirements of its community, which consists of over 1,000 researchers. This report introduces Milabench, the resulting benchmarking suite. Its design was informed by an extensive literature review encompassing 867 papers, as well as surveys conducted with Mila researchers. This rigorous process led to the selection of 26 primary benchmarks tailored for procurement evaluations, alongside 16 optional benchmarks for in-depth analysis. We detail the design methodology, the structure of the benchmarking suite, and provide performance evaluations using GPUs from NVIDIA, AMD, and Intel. The Milabench suite is open source and can be accessed at github.com/mila-iqia/milabench.
DeepDrummer : Generating Drum Loops using Deep Learning and a Human in the Loop
Aug 26, 2020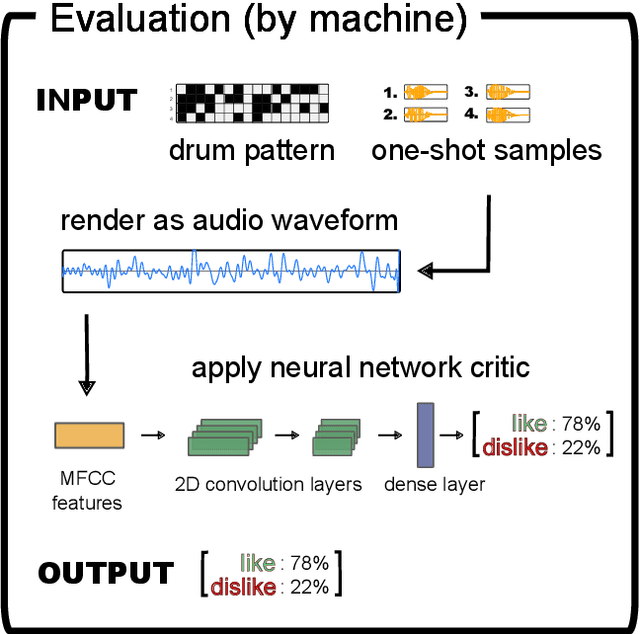
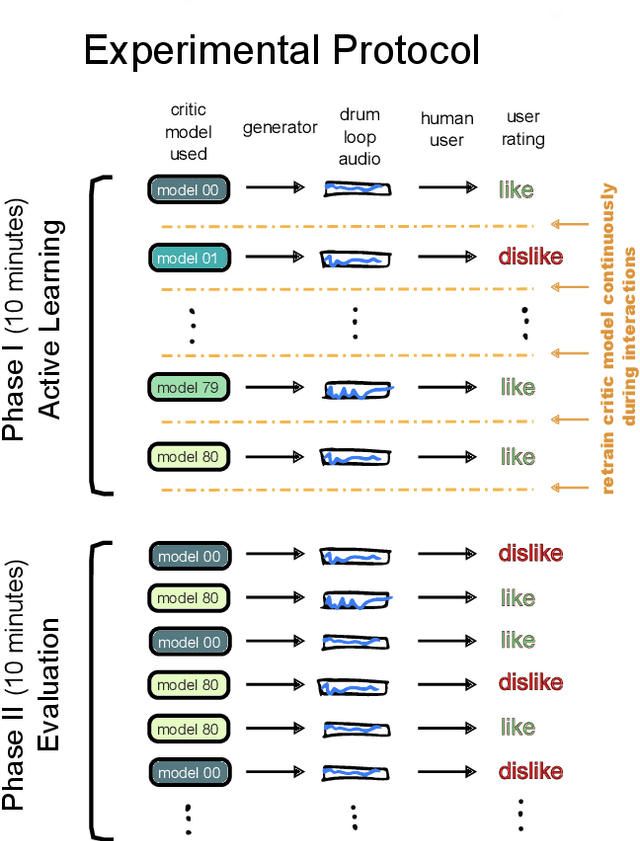

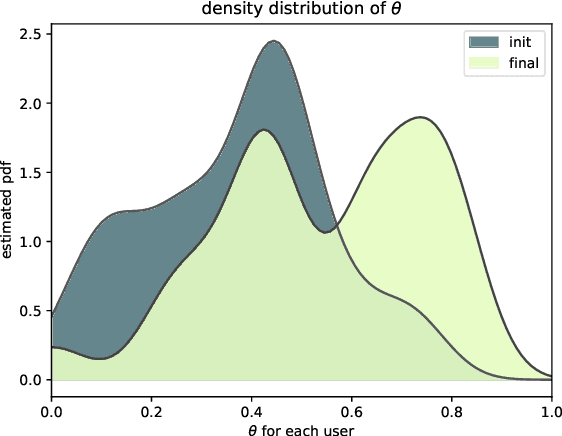
DeepDrummer is a drum loop generation tool that uses active learning to learn the preferences (or current artistic intentions) of a human user from a small number of interactions. The principal goal of this tool is to enable an efficient exploration of new musical ideas. We train a deep neural network classifier on audio data and show how it can be used as the core component of a system that generates drum loops based on few prior beliefs as to how these loops should be structured. We aim to build a system that can converge to meaningful results even with a limited number of interactions with the user. This property enables our method to be used from a cold start situation (no pre-existing dataset), or starting from a collection of audio samples provided by the user. In a proof of concept study with 25 participants, we empirically demonstrate that DeepDrummer is able to converge towards the preference of our subjects after a small number of interactions.
Robo-PlaNet: Learning to Poke in a Day
Nov 19, 2019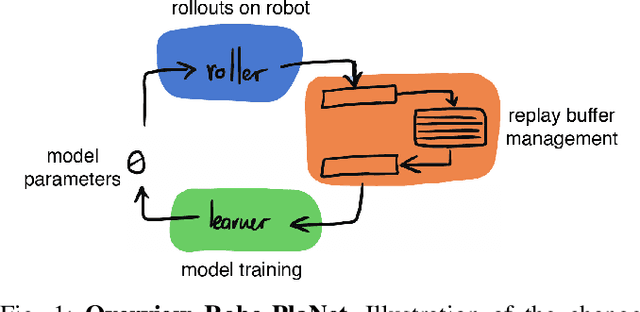

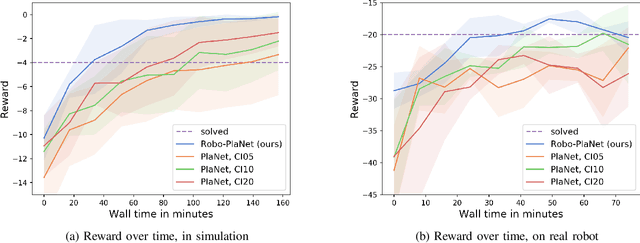
Recently, the Deep Planning Network (PlaNet) approach was introduced as a model-based reinforcement learning method that learns environment dynamics directly from pixel observations. This architecture is useful for learning tasks in which either the agent does not have access to meaningful states (like position/velocity of robotic joints) or where the observed states significantly deviate from the physical state of the agent (which is commonly the case in low-cost robots in the form of backlash or noisy joint readings). PlaNet, by design, interleaves phases of training the dynamics model with phases of collecting more data on the target environment, leading to long training times. In this work, we introduce Robo-PlaNet, an asynchronous version of PlaNet. This algorithm consistently reaches higher performance in the same amount of time, which we demonstrate in both a simulated and a real robotic experiment.
Negative eigenvalues of the Hessian in deep neural networks
Feb 06, 2019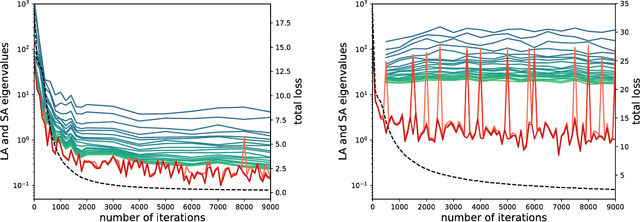
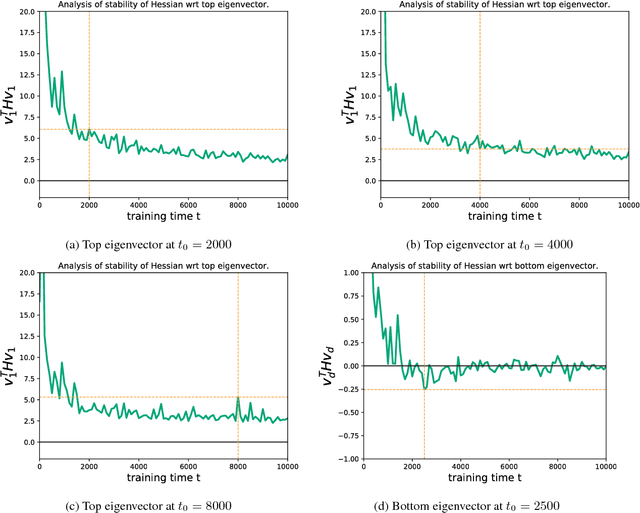
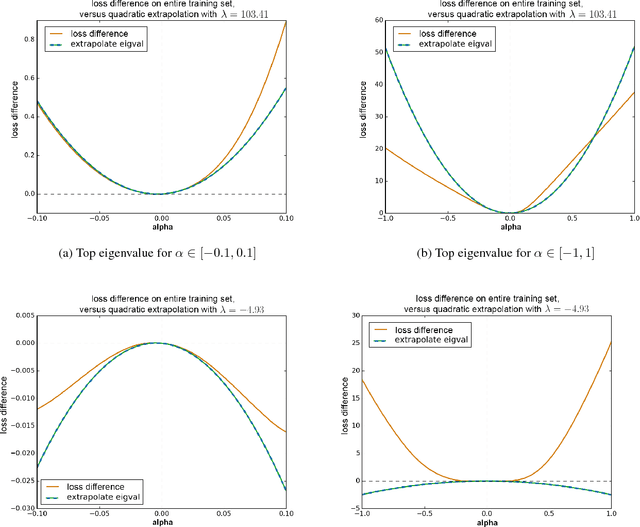
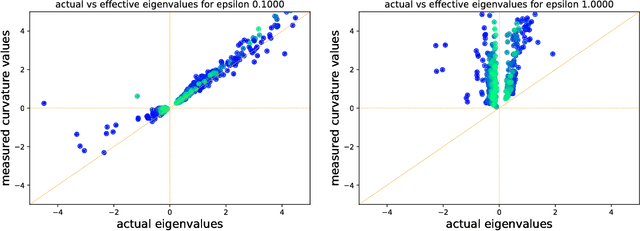
The loss function of deep networks is known to be non-convex but the precise nature of this nonconvexity is still an active area of research. In this work, we study the loss landscape of deep networks through the eigendecompositions of their Hessian matrix. In particular, we examine how important the negative eigenvalues are and the benefits one can observe in handling them appropriately.
Understanding intermediate layers using linear classifier probes
Oct 14, 2016
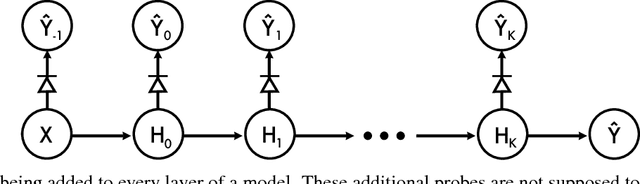
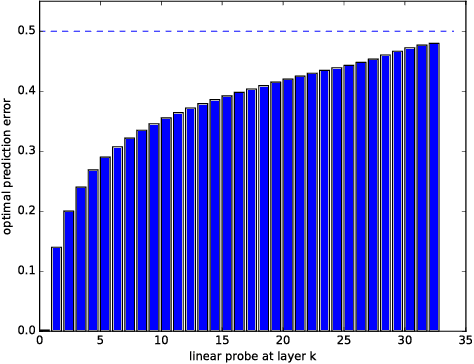

Neural network models have a reputation for being black boxes. We propose a new method to understand better the roles and dynamics of the intermediate layers. This has direct consequences on the design of such models and it enables the expert to be able to justify certain heuristics (such as the auxiliary heads in the Inception model). Our method uses linear classifiers, referred to as "probes", where a probe can only use the hidden units of a given intermediate layer as discriminating features. Moreover, these probes cannot affect the training phase of a model, and they are generally added after training. They allow the user to visualize the state of the model at multiple steps of training. We demonstrate how this can be used to develop a better intuition about a known model and to diagnose potential problems.
Theano: A Python framework for fast computation of mathematical expressions
May 09, 2016



Theano is a Python library that allows to define, optimize, and evaluate mathematical expressions involving multi-dimensional arrays efficiently. Since its introduction, it has been one of the most used CPU and GPU mathematical compilers - especially in the machine learning community - and has shown steady performance improvements. Theano is being actively and continuously developed since 2008, multiple frameworks have been built on top of it and it has been used to produce many state-of-the-art machine learning models. The present article is structured as follows. Section I provides an overview of the Theano software and its community. Section II presents the principal features of Theano and how to use them, and compares them with other similar projects. Section III focuses on recently-introduced functionalities and improvements. Section IV compares the performance of Theano against Torch7 and TensorFlow on several machine learning models. Section V discusses current limitations of Theano and potential ways of improving it.
Variance Reduction in SGD by Distributed Importance Sampling
Apr 16, 2016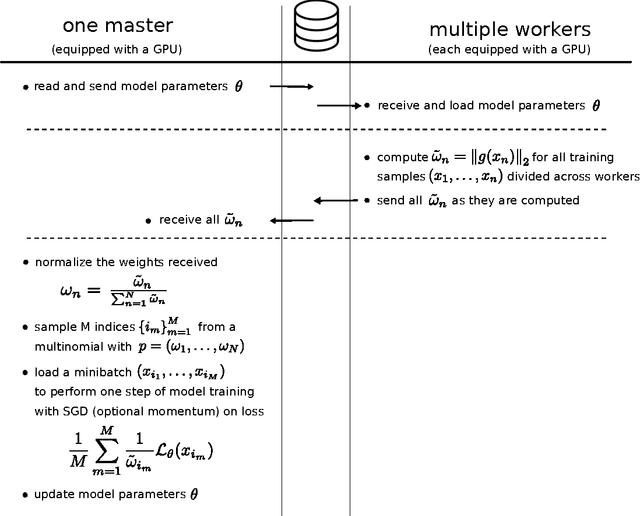
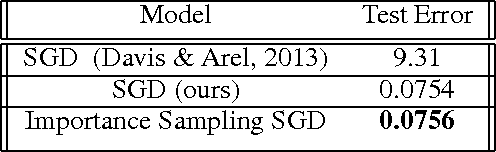
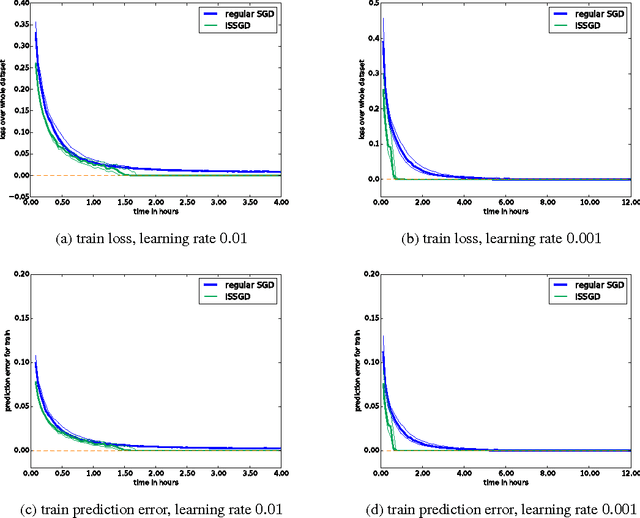
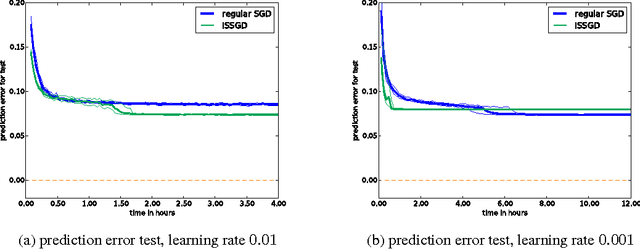
Humans are able to accelerate their learning by selecting training materials that are the most informative and at the appropriate level of difficulty. We propose a framework for distributing deep learning in which one set of workers search for the most informative examples in parallel while a single worker updates the model on examples selected by importance sampling. This leads the model to update using an unbiased estimate of the gradient which also has minimum variance when the sampling proposal is proportional to the L2-norm of the gradient. We show experimentally that this method reduces gradient variance even in a context where the cost of synchronization across machines cannot be ignored, and where the factors for importance sampling are not updated instantly across the training set.
Techniques for Learning Binary Stochastic Feedforward Neural Networks
Apr 09, 2015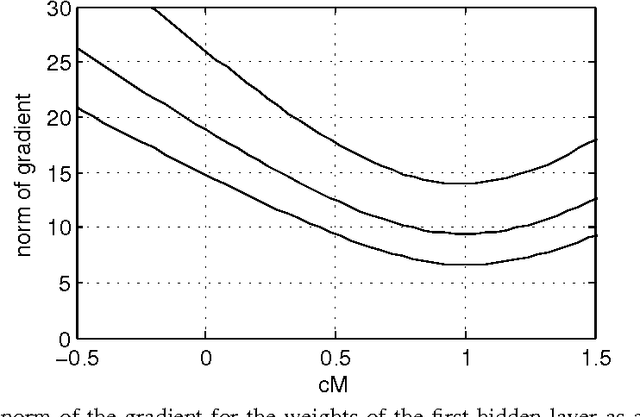
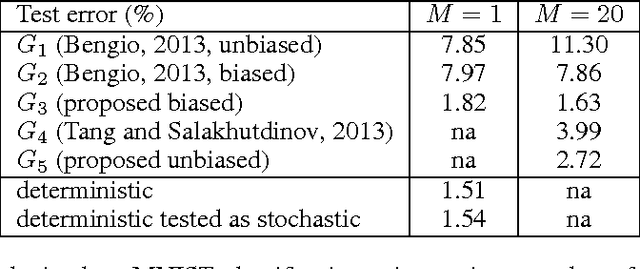
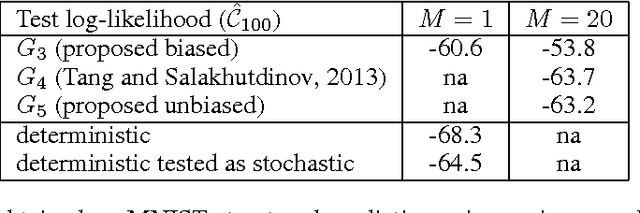
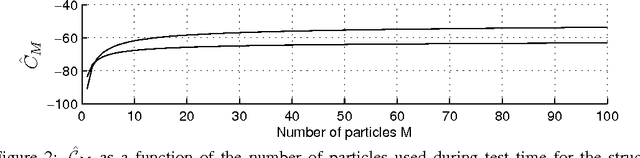
Stochastic binary hidden units in a multi-layer perceptron (MLP) network give at least three potential benefits when compared to deterministic MLP networks. (1) They allow to learn one-to-many type of mappings. (2) They can be used in structured prediction problems, where modeling the internal structure of the output is important. (3) Stochasticity has been shown to be an excellent regularizer, which makes generalization performance potentially better in general. However, training stochastic networks is considerably more difficult. We study training using M samples of hidden activations per input. We show that the case M=1 leads to a fundamentally different behavior where the network tries to avoid stochasticity. We propose two new estimators for the training gradient and propose benchmark tests for comparing training algorithms. Our experiments confirm that training stochastic networks is difficult and show that the proposed two estimators perform favorably among all the five known estimators.
GSNs : Generative Stochastic Networks
Mar 23, 2015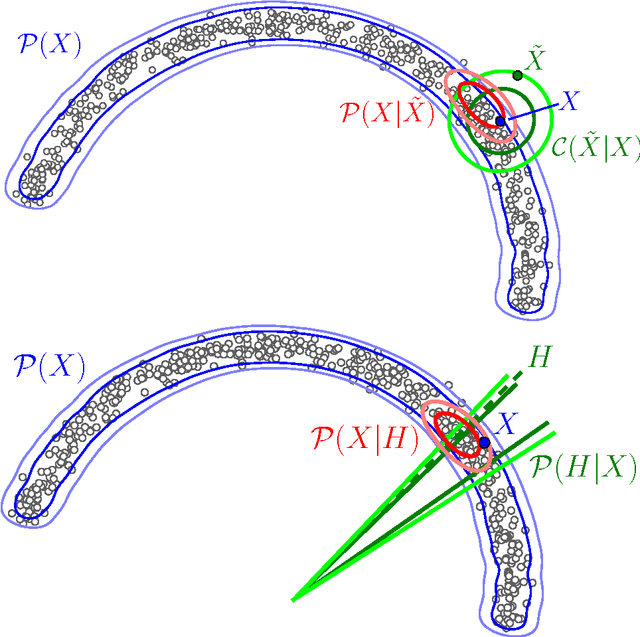

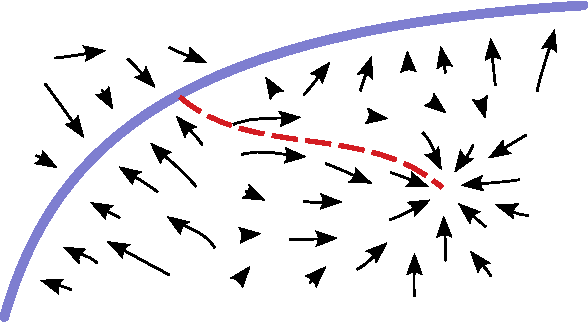
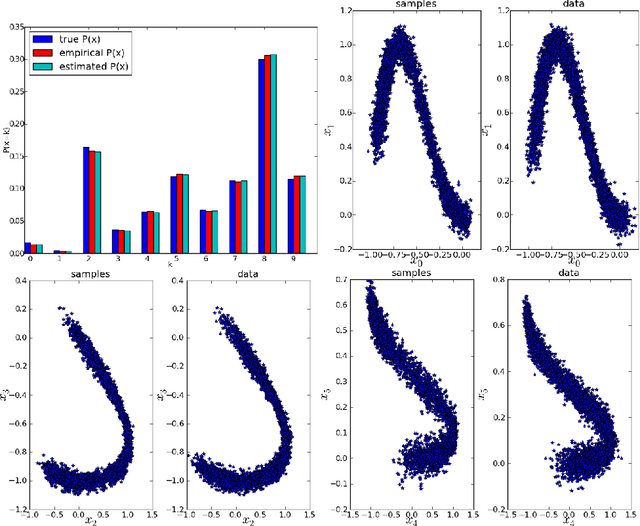
We introduce a novel training principle for probabilistic models that is an alternative to maximum likelihood. The proposed Generative Stochastic Networks (GSN) framework is based on learning the transition operator of a Markov chain whose stationary distribution estimates the data distribution. Because the transition distribution is a conditional distribution generally involving a small move, it has fewer dominant modes, being unimodal in the limit of small moves. Thus, it is easier to learn, more like learning to perform supervised function approximation, with gradients that can be obtained by back-propagation. The theorems provided here generalize recent work on the probabilistic interpretation of denoising auto-encoders and provide an interesting justification for dependency networks and generalized pseudolikelihood (along with defining an appropriate joint distribution and sampling mechanism, even when the conditionals are not consistent). We study how GSNs can be used with missing inputs and can be used to sample subsets of variables given the rest. Successful experiments are conducted, validating these theoretical results, on two image datasets and with a particular architecture that mimics the Deep Boltzmann Machine Gibbs sampler but allows training to proceed with backprop, without the need for layerwise pretraining.
What Regularized Auto-Encoders Learn from the Data Generating Distribution
Aug 19, 2014
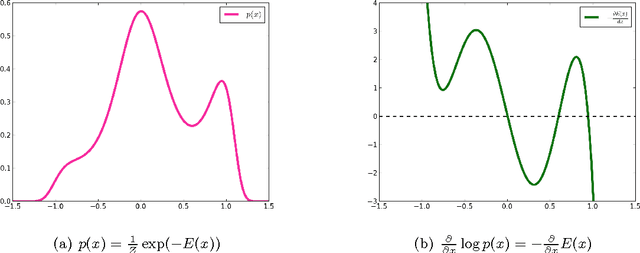
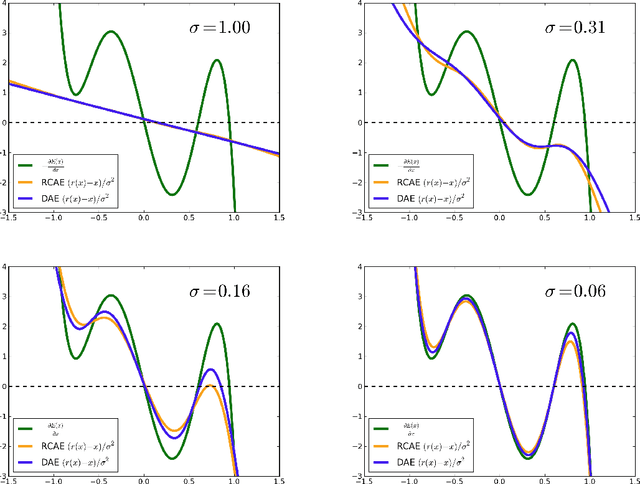
What do auto-encoders learn about the underlying data generating distribution? Recent work suggests that some auto-encoder variants do a good job of capturing the local manifold structure of data. This paper clarifies some of these previous observations by showing that minimizing a particular form of regularized reconstruction error yields a reconstruction function that locally characterizes the shape of the data generating density. We show that the auto-encoder captures the score (derivative of the log-density with respect to the input). It contradicts previous interpretations of reconstruction error as an energy function. Unlike previous results, the theorems provided here are completely generic and do not depend on the parametrization of the auto-encoder: they show what the auto-encoder would tend to if given enough capacity and examples. These results are for a contractive training criterion we show to be similar to the denoising auto-encoder training criterion with small corruption noise, but with contraction applied on the whole reconstruction function rather than just encoder. Similarly to score matching, one can consider the proposed training criterion as a convenient alternative to maximum likelihood because it does not involve a partition function. Finally, we show how an approximate Metropolis-Hastings MCMC can be setup to recover samples from the estimated distribution, and this is confirmed in sampling experiments.