 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChunky Post-Training: Data Driven Failures of Generalization
Feb 05, 2026LLM post-training involves many diverse datasets, each targeting a specific behavior. But these datasets encode incidental patterns alongside intended ones: correlations between formatting and content, narrow phrasings across diverse problems, and implicit associations arising from the discrete data curation process. These patterns are often invisible to developers yet salient to models, producing behaviors that surprise their creators, such as rejecting true facts presented in a particular question format. We call this chunky post-training: the model learns spurious correlations as a result of distinct chunks of post-training data. We introduce SURF, a black-box pipeline which surfaces these unintended behaviors at run time, and TURF, a tool that traces these failures back to specific post-training data. Applying these tools to frontier models (Claude 4.5, GPT-5.1, Grok 4.1, Gemini 3) and open models (Tülu 3), we show that chunky post-training produces miscalibrated behaviors, which often result from imbalanced or underspecified chunks of post-training data.
Stress-Testing Model Specs Reveals Character Differences among Language Models
Oct 09, 2025Large language models (LLMs) are increasingly trained from AI constitutions and model specifications that establish behavioral guidelines and ethical principles. However, these specifications face critical challenges, including internal conflicts between principles and insufficient coverage of nuanced scenarios. We present a systematic methodology for stress-testing model character specifications, automatically identifying numerous cases of principle contradictions and interpretive ambiguities in current model specs. We stress test current model specs by generating scenarios that force explicit tradeoffs between competing value-based principles. Using a comprehensive taxonomy we generate diverse value tradeoff scenarios where models must choose between pairs of legitimate principles that cannot be simultaneously satisfied. We evaluate responses from twelve frontier LLMs across major providers (Anthropic, OpenAI, Google, xAI) and measure behavioral disagreement through value classification scores. Among these scenarios, we identify over 70,000 cases exhibiting significant behavioral divergence. Empirically, we show this high divergence in model behavior strongly predicts underlying problems in model specifications. Through qualitative analysis, we provide numerous example issues in current model specs such as direct contradiction and interpretive ambiguities of several principles. Additionally, our generated dataset also reveals both clear misalignment cases and false-positive refusals across all of the frontier models we study. Lastly, we also provide value prioritization patterns and differences of these models.
Reasoning Models Don't Always Say What They Think
May 08, 2025



Chain-of-thought (CoT) offers a potential boon for AI safety as it allows monitoring a model's CoT to try to understand its intentions and reasoning processes. However, the effectiveness of such monitoring hinges on CoTs faithfully representing models' actual reasoning processes. We evaluate CoT faithfulness of state-of-the-art reasoning models across 6 reasoning hints presented in the prompts and find: (1) for most settings and models tested, CoTs reveal their usage of hints in at least 1% of examples where they use the hint, but the reveal rate is often below 20%, (2) outcome-based reinforcement learning initially improves faithfulness but plateaus without saturating, and (3) when reinforcement learning increases how frequently hints are used (reward hacking), the propensity to verbalize them does not increase, even without training against a CoT monitor. These results suggest that CoT monitoring is a promising way of noticing undesired behaviors during training and evaluations, but that it is not sufficient to rule them out. They also suggest that in settings like ours where CoT reasoning is not necessary, test-time monitoring of CoTs is unlikely to reliably catch rare and catastrophic unexpected behaviors.
Measuring short-form factuality in large language models
Nov 07, 2024



We present SimpleQA, a benchmark that evaluates the ability of language models to answer short, fact-seeking questions. We prioritized two properties in designing this eval. First, SimpleQA is challenging, as it is adversarially collected against GPT-4 responses. Second, responses are easy to grade, because questions are created such that there exists only a single, indisputable answer. Each answer in SimpleQA is graded as either correct, incorrect, or not attempted. A model with ideal behavior would get as many questions correct as possible while not attempting the questions for which it is not confident it knows the correct answer. SimpleQA is a simple, targeted evaluation for whether models "know what they know," and our hope is that this benchmark will remain relevant for the next few generations of frontier models. SimpleQA can be found at https://github.com/openai/simple-evals.
Rule Based Rewards for Language Model Safety
Nov 02, 2024Reinforcement learning based fine-tuning of large language models (LLMs) on human preferences has been shown to enhance both their capabilities and safety behavior. However, in cases related to safety, without precise instructions to human annotators, the data collected may cause the model to become overly cautious, or to respond in an undesirable style, such as being judgmental. Additionally, as model capabilities and usage patterns evolve, there may be a costly need to add or relabel data to modify safety behavior. We propose a novel preference modeling approach that utilizes AI feedback and only requires a small amount of human data. Our method, Rule Based Rewards (RBR), uses a collection of rules for desired or undesired behaviors (e.g. refusals should not be judgmental) along with a LLM grader. In contrast to prior methods using AI feedback, our method uses fine-grained, composable, LLM-graded few-shot prompts as reward directly in RL training, resulting in greater control, accuracy and ease of updating. We show that RBRs are an effective training method, achieving an F1 score of 97.1, compared to a human-feedback baseline of 91.7, resulting in much higher safety-behavior accuracy through better balancing usefulness and safety.
GPT-4o System Card
Oct 25, 2024GPT-4o is an autoregressive omni model that accepts as input any combination of text, audio, image, and video, and generates any combination of text, audio, and image outputs. It's trained end-to-end across text, vision, and audio, meaning all inputs and outputs are processed by the same neural network. GPT-4o can respond to audio inputs in as little as 232 milliseconds, with an average of 320 milliseconds, which is similar to human response time in conversation. It matches GPT-4 Turbo performance on text in English and code, with significant improvement on text in non-English languages, while also being much faster and 50\% cheaper in the API. GPT-4o is especially better at vision and audio understanding compared to existing models. In line with our commitment to building AI safely and consistent with our voluntary commitments to the White House, we are sharing the GPT-4o System Card, which includes our Preparedness Framework evaluations. In this System Card, we provide a detailed look at GPT-4o's capabilities, limitations, and safety evaluations across multiple categories, focusing on speech-to-speech while also evaluating text and image capabilities, and measures we've implemented to ensure the model is safe and aligned. We also include third-party assessments on dangerous capabilities, as well as discussion of potential societal impacts of GPT-4o's text and vision capabilities.
Let's Verify Step by Step
May 31, 2023



In recent years, large language models have greatly improved in their ability to perform complex multi-step reasoning. However, even state-of-the-art models still regularly produce logical mistakes. To train more reliable models, we can turn either to outcome supervision, which provides feedback for a final result, or process supervision, which provides feedback for each intermediate reasoning step. Given the importance of training reliable models, and given the high cost of human feedback, it is important to carefully compare the both methods. Recent work has already begun this comparison, but many questions still remain. We conduct our own investigation, finding that process supervision significantly outperforms outcome supervision for training models to solve problems from the challenging MATH dataset. Our process-supervised model solves 78% of problems from a representative subset of the MATH test set. Additionally, we show that active learning significantly improves the efficacy of process supervision. To support related research, we also release PRM800K, the complete dataset of 800,000 step-level human feedback labels used to train our best reward model.
Scaling laws for single-agent reinforcement learning
Jan 31, 2023



Recent work has shown that, in generative modeling, cross-entropy loss improves smoothly with model size and training compute, following a power law plus constant scaling law. One challenge in extending these results to reinforcement learning is that the main performance objective of interest, mean episode return, need not vary smoothly. To overcome this, we introduce *intrinsic performance*, a monotonic function of the return defined as the minimum compute required to achieve the given return across a family of models of different sizes. We find that, across a range of environments, intrinsic performance scales as a power law in model size and environment interactions. Consequently, as in generative modeling, the optimal model size scales as a power law in the training compute budget. Furthermore, we study how this relationship varies with the environment and with other properties of the training setup. In particular, using a toy MNIST-based environment, we show that varying the "horizon length" of the task mostly changes the coefficient but not the exponent of this relationship.
Scaling Laws for Reward Model Overoptimization
Oct 19, 2022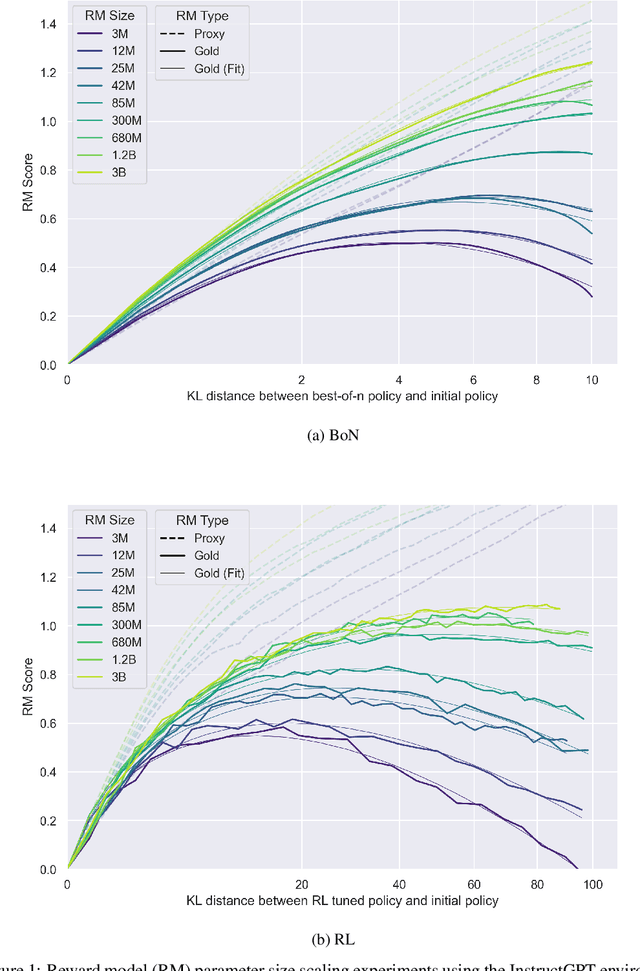

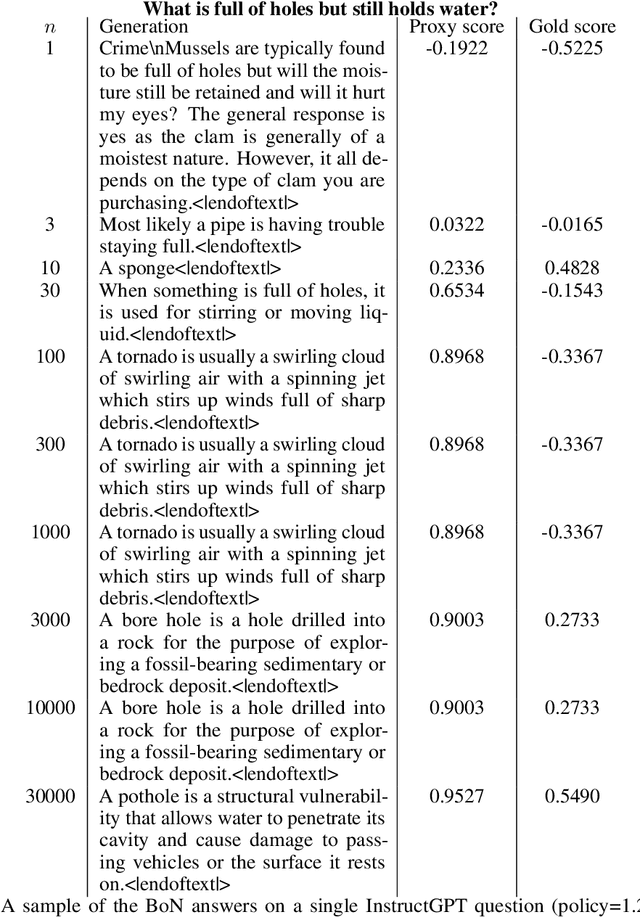
In reinforcement learning from human feedback, it is common to optimize against a reward model trained to predict human preferences. Because the reward model is an imperfect proxy, optimizing its value too much can hinder ground truth performance, in accordance with Goodhart's law. This effect has been frequently observed, but not carefully measured due to the expense of collecting human preference data. In this work, we use a synthetic setup in which a fixed "gold-standard" reward model plays the role of humans, providing labels used to train a proxy reward model. We study how the gold reward model score changes as we optimize against the proxy reward model using either reinforcement learning or best-of-$n$ sampling. We find that this relationship follows a different functional form depending on the method of optimization, and that in both cases its coefficients scale smoothly with the number of reward model parameters. We also study the effect on this relationship of the size of the reward model dataset, the number of reward model and policy parameters, and the coefficient of the KL penalty added to the reward in the reinforcement learning setup. We explore the implications of these empirical results for theoretical considerations in AI alignment.
Efficient Training of Language Models to Fill in the Middle
Jul 28, 2022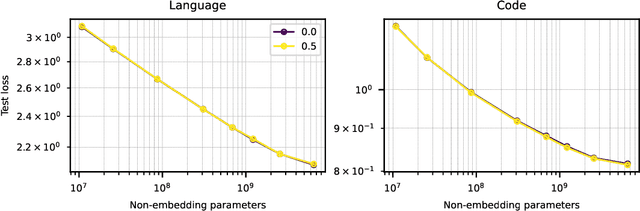
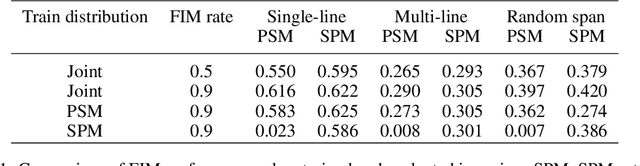
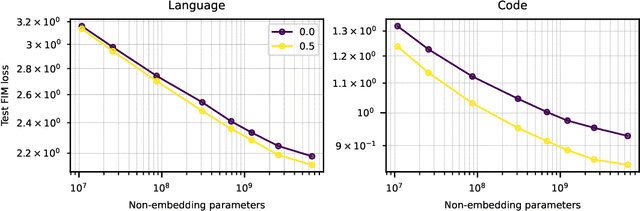

We show that autoregressive language models can learn to infill text after we apply a straightforward transformation to the dataset, which simply moves a span of text from the middle of a document to its end. While this data augmentation has garnered much interest in recent years, we provide extensive evidence that training models with a large fraction of data transformed in this way does not harm the original left-to-right generative capability, as measured by perplexity and sampling evaluations across a wide range of scales. Given the usefulness, simplicity, and efficiency of training models to fill-in-the-middle (FIM), we suggest that future autoregressive language models be trained with FIM by default. To this end, we run a series of ablations on key hyperparameters, such as the data transformation frequency, the structure of the transformation, and the method of selecting the infill span. We use these ablations to prescribe strong default settings and best practices to train FIM models. We have released our best infilling model trained with best practices in our API, and release our infilling benchmarks to aid future research.