 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProving Theorems using Incremental Learning and Hindsight Experience Replay
Dec 20, 2021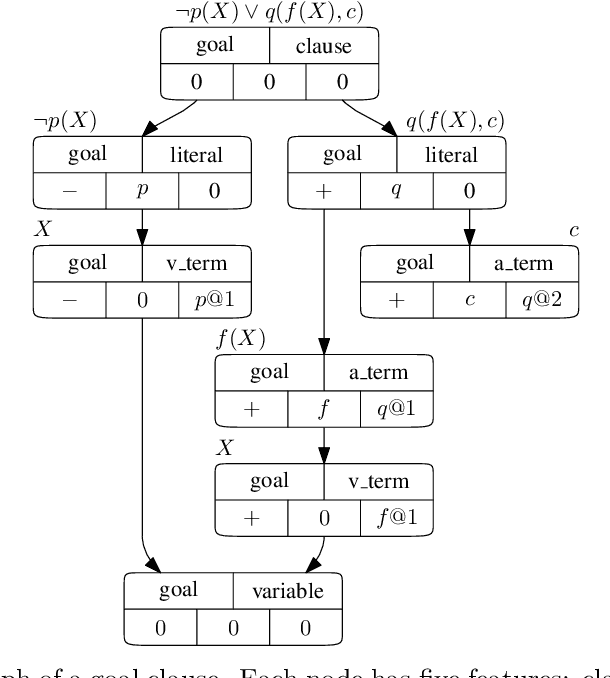
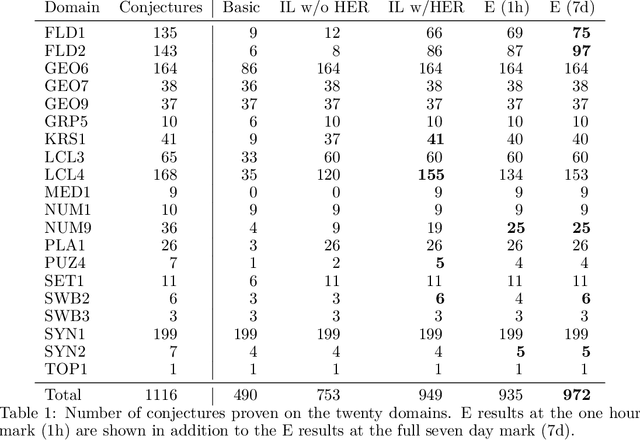
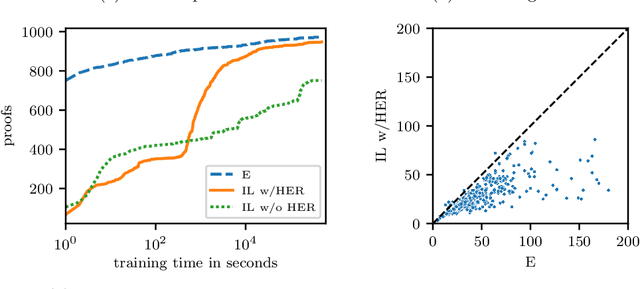
Traditional automated theorem provers for first-order logic depend on speed-optimized search and many handcrafted heuristics that are designed to work best over a wide range of domains. Machine learning approaches in literature either depend on these traditional provers to bootstrap themselves or fall short on reaching comparable performance. In this paper, we propose a general incremental learning algorithm for training domain specific provers for first-order logic without equality, based only on a basic given-clause algorithm, but using a learned clause-scoring function. Clauses are represented as graphs and presented to transformer networks with spectral features. To address the sparsity and the initial lack of training data as well as the lack of a natural curriculum, we adapt hindsight experience replay to theorem proving, so as to be able to learn even when no proof can be found. We show that provers trained this way can match and sometimes surpass state-of-the-art traditional provers on the TPTP dataset in terms of both quantity and quality of the proofs.
Training a First-Order Theorem Prover from Synthetic Data
Mar 05, 2021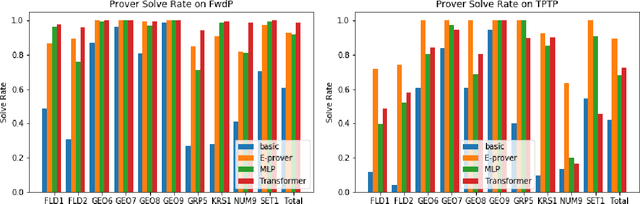
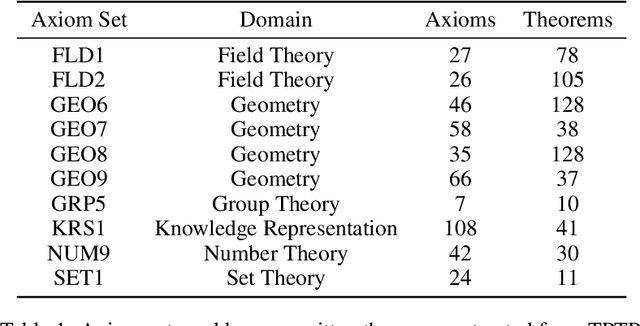
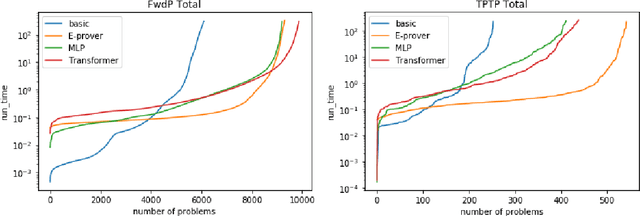
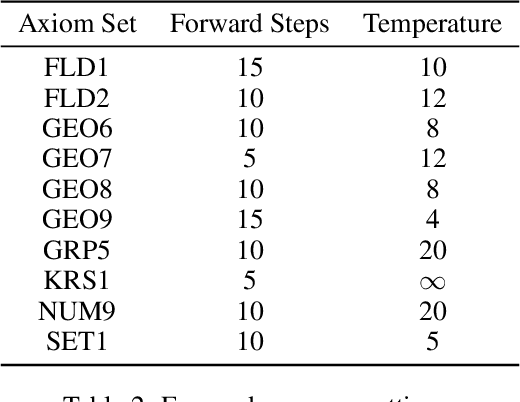
A major challenge in applying machine learning to automated theorem proving is the scarcity of training data, which is a key ingredient in training successful deep learning models. To tackle this problem, we propose an approach that relies on training purely with synthetically generated theorems, without any human data aside from axioms. We use these theorems to train a neurally-guided saturation-based prover. Our neural prover outperforms the state-of-the-art E-prover on this synthetic data in both time and search steps, and shows significant transfer to the unseen human-written theorems from the TPTP library, where it solves 72\% of first-order problems without equality.
Learning to Prove from Synthetic Theorems
Jun 19, 2020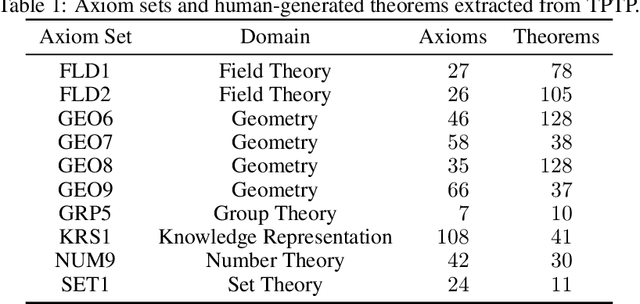
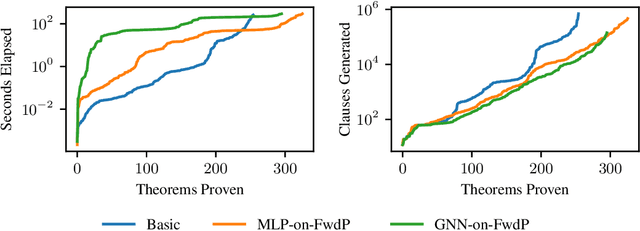
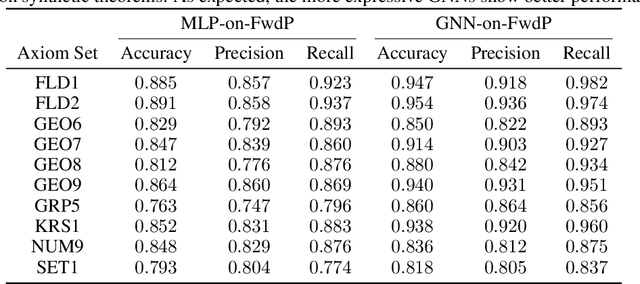
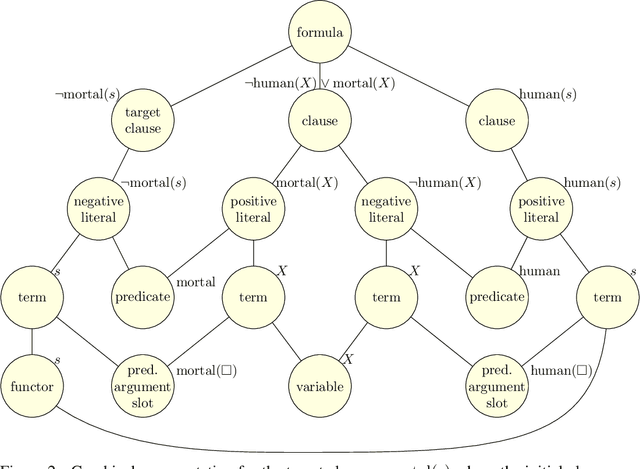
A major challenge in applying machine learning to automated theorem proving is the scarcity of training data, which is a key ingredient in training successful deep learning models. To tackle this problem, we propose an approach that relies on training with synthetic theorems, generated from a set of axioms. We show that such theorems can be used to train an automated prover and that the learned prover transfers successfully to human-generated theorems. We demonstrate that a prover trained exclusively on synthetic theorems can solve a substantial fraction of problems in TPTP, a benchmark dataset that is used to compare state-of-the-art heuristic provers. Our approach outperforms a model trained on human-generated problems in most axiom sets, thereby showing the promise of using synthetic data for this task.
Early Visual Concept Learning with Unsupervised Deep Learning
Sep 20, 2016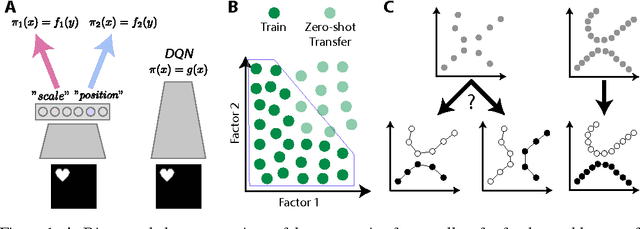
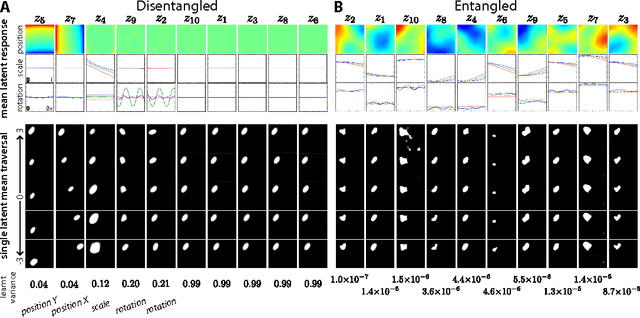

Automated discovery of early visual concepts from raw image data is a major open challenge in AI research. Addressing this problem, we propose an unsupervised approach for learning disentangled representations of the underlying factors of variation. We draw inspiration from neuroscience, and show how this can be achieved in an unsupervised generative model by applying the same learning pressures as have been suggested to act in the ventral visual stream in the brain. By enforcing redundancy reduction, encouraging statistical independence, and exposure to data with transform continuities analogous to those to which human infants are exposed, we obtain a variational autoencoder (VAE) framework capable of learning disentangled factors. Our approach makes few assumptions and works well across a wide variety of datasets. Furthermore, our solution has useful emergent properties, such as zero-shot inference and an intuitive understanding of "objectness".
Theano: A Python framework for fast computation of mathematical expressions
May 09, 2016



Theano is a Python library that allows to define, optimize, and evaluate mathematical expressions involving multi-dimensional arrays efficiently. Since its introduction, it has been one of the most used CPU and GPU mathematical compilers - especially in the machine learning community - and has shown steady performance improvements. Theano is being actively and continuously developed since 2008, multiple frameworks have been built on top of it and it has been used to produce many state-of-the-art machine learning models. The present article is structured as follows. Section I provides an overview of the Theano software and its community. Section II presents the principal features of Theano and how to use them, and compares them with other similar projects. Section III focuses on recently-introduced functionalities and improvements. Section IV compares the performance of Theano against Torch7 and TensorFlow on several machine learning models. Section V discusses current limitations of Theano and potential ways of improving it.
A Semantic Matching Energy Function for Learning with Multi-relational Data
Mar 21, 2013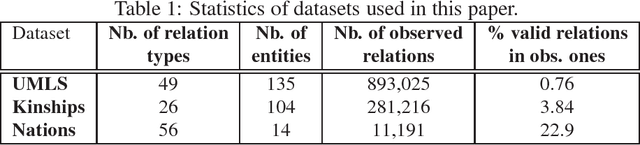
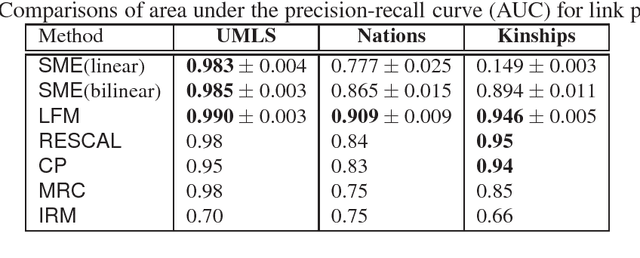
Large-scale relational learning becomes crucial for handling the huge amounts of structured data generated daily in many application domains ranging from computational biology or information retrieval, to natural language processing. In this paper, we present a new neural network architecture designed to embed multi-relational graphs into a flexible continuous vector space in which the original data is kept and enhanced. The network is trained to encode the semantics of these graphs in order to assign high probabilities to plausible components. We empirically show that it reaches competitive performance in link prediction on standard datasets from the literature.
Towards Open-Text Semantic Parsing via Multi-Task Learning of Structured Embeddings
Jul 19, 2011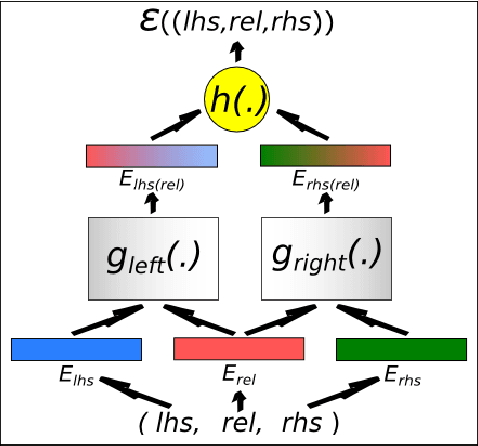
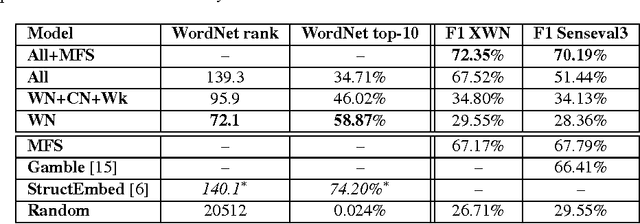

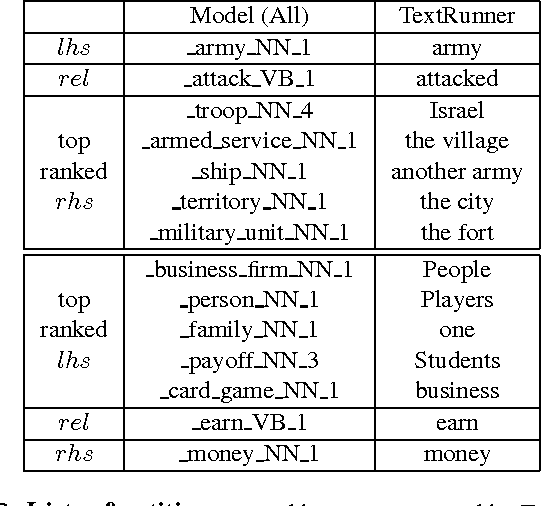
Open-text (or open-domain) semantic parsers are designed to interpret any statement in natural language by inferring a corresponding meaning representation (MR). Unfortunately, large scale systems cannot be easily machine-learned due to lack of directly supervised data. We propose here a method that learns to assign MRs to a wide range of text (using a dictionary of more than 70,000 words, which are mapped to more than 40,000 entities) thanks to a training scheme that combines learning from WordNet and ConceptNet with learning from raw text. The model learns structured embeddings of words, entities and MRs via a multi-task training process operating on these diverse sources of data that integrates all the learnt knowledge into a single system. This work ends up combining methods for knowledge acquisition, semantic parsing, and word-sense disambiguation. Experiments on various tasks indicate that our approach is indeed successful and can form a basis for future more sophisticated systems.
Learning invariant features through local space contraction
Apr 21, 2011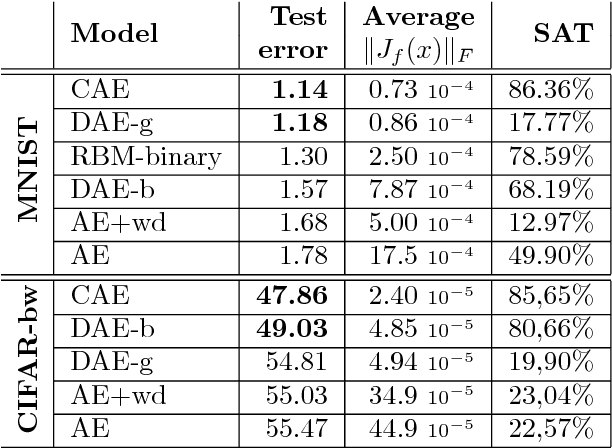
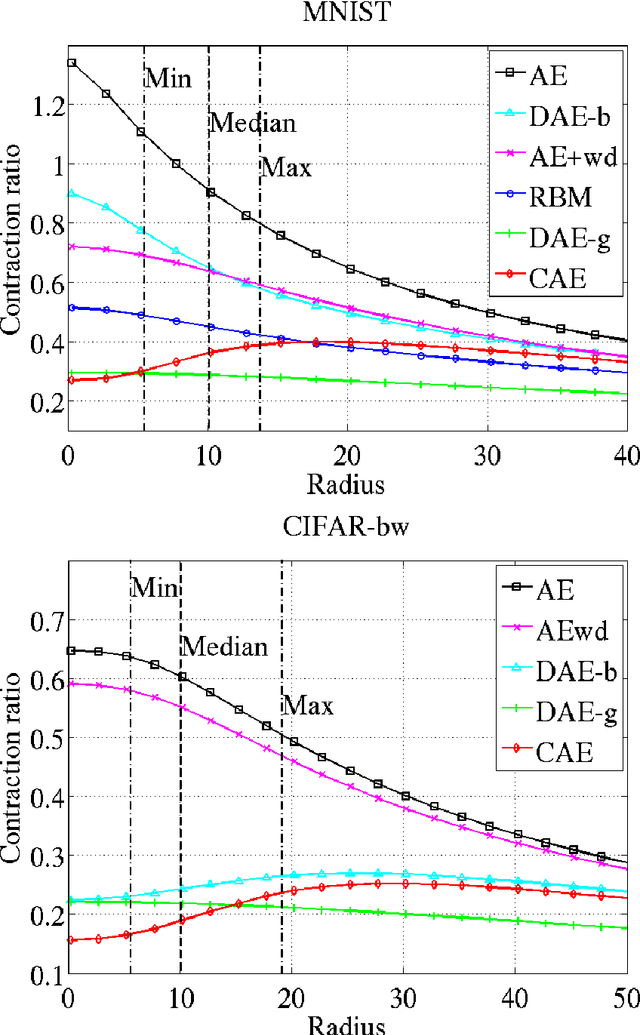
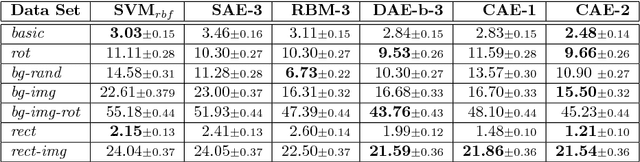
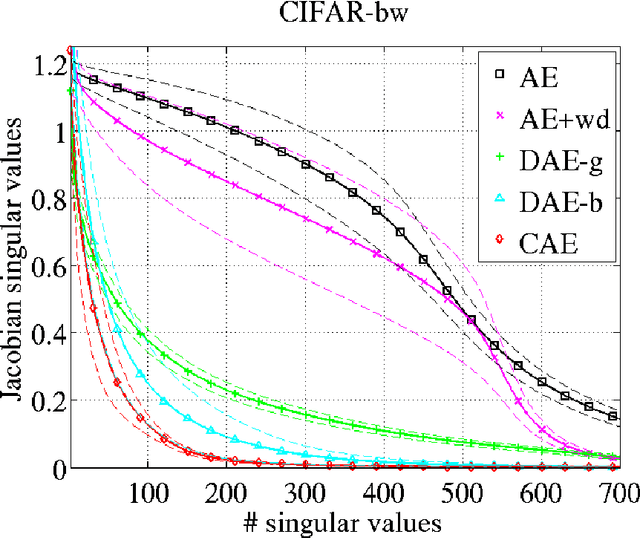
We present in this paper a novel approach for training deterministic auto-encoders. We show that by adding a well chosen penalty term to the classical reconstruction cost function, we can achieve results that equal or surpass those attained by other regularized auto-encoders as well as denoising auto-encoders on a range of datasets. This penalty term corresponds to the Frobenius norm of the Jacobian matrix of the encoder activations with respect to the input. We show that this penalty term results in a localized space contraction which in turn yields robust features on the activation layer. Furthermore, we show how this penalty term is related to both regularized auto-encoders and denoising encoders and how it can be seen as a link between deterministic and non-deterministic auto-encoders. We find empirically that this penalty helps to carve a representation that better captures the local directions of variation dictated by the data, corresponding to a lower-dimensional non-linear manifold, while being more invariant to the vast majority of directions orthogonal to the manifold. Finally, we show that by using the learned features to initialize a MLP, we achieve state of the art classification error on a range of datasets, surpassing other methods of pre-training.
Adding noise to the input of a model trained with a regularized objective
Apr 16, 2011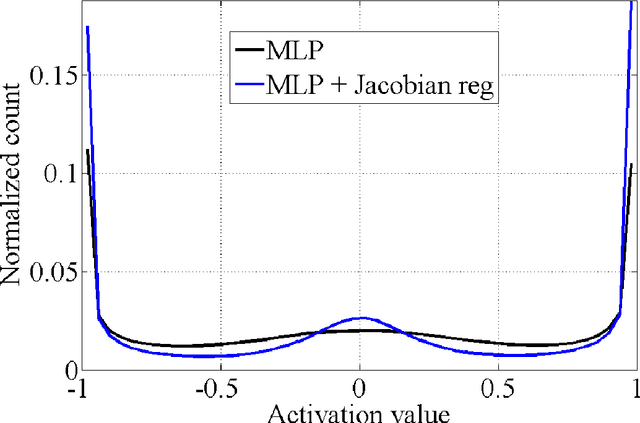
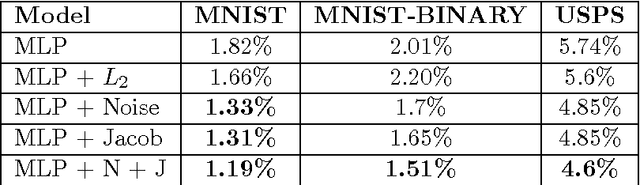
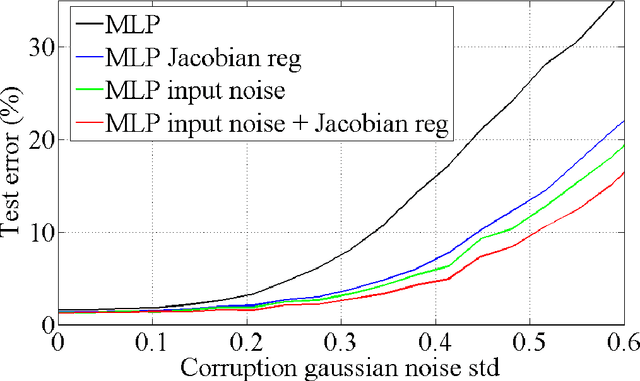
Regularization is a well studied problem in the context of neural networks. It is usually used to improve the generalization performance when the number of input samples is relatively small or heavily contaminated with noise. The regularization of a parametric model can be achieved in different manners some of which are early stopping (Morgan and Bourlard, 1990), weight decay, output smoothing that are used to avoid overfitting during the training of the considered model. From a Bayesian point of view, many regularization techniques correspond to imposing certain prior distributions on model parameters (Krogh and Hertz, 1991). Using Bishop's approximation (Bishop, 1995) of the objective function when a restricted type of noise is added to the input of a parametric function, we derive the higher order terms of the Taylor expansion and analyze the coefficients of the regularization terms induced by the noisy input. In particular we study the effect of penalizing the Hessian of the mapping function with respect to the input in terms of generalization performance. We also show how we can control independently this coefficient by explicitly penalizing the Jacobian of the mapping function on corrupted inputs.
Deep Self-Taught Learning for Handwritten Character Recognition
Sep 18, 2010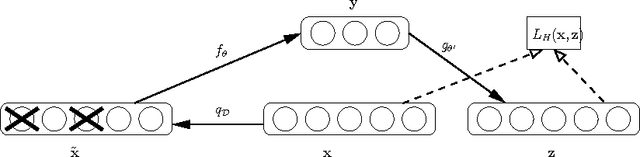
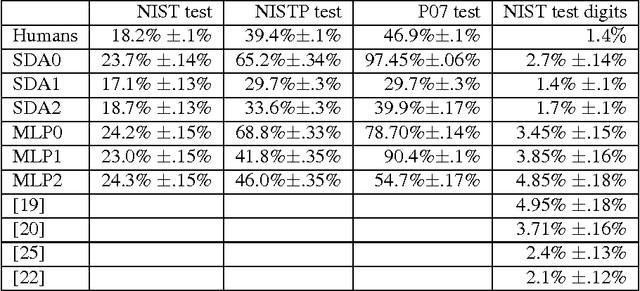
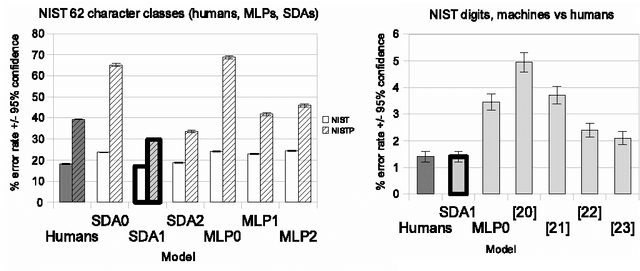
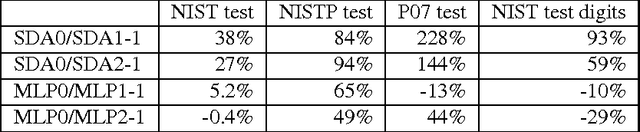
Recent theoretical and empirical work in statistical machine learning has demonstrated the importance of learning algorithms for deep architectures, i.e., function classes obtained by composing multiple non-linear transformations. Self-taught learning (exploiting unlabeled examples or examples from other distributions) has already been applied to deep learners, but mostly to show the advantage of unlabeled examples. Here we explore the advantage brought by {\em out-of-distribution examples}. For this purpose we developed a powerful generator of stochastic variations and noise processes for character images, including not only affine transformations but also slant, local elastic deformations, changes in thickness, background images, grey level changes, contrast, occlusion, and various types of noise. The out-of-distribution examples are obtained from these highly distorted images or by including examples of object classes different from those in the target test set. We show that {\em deep learners benefit more from out-of-distribution examples than a corresponding shallow learner}, at least in the area of handwritten character recognition. In fact, we show that they beat previously published results and reach human-level performance on both handwritten digit classification and 62-class handwritten character recognition.