 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Autonomous Long-Horizon Engineering for ML Research
Apr 14, 2026Autonomous AI research has advanced rapidly, but long-horizon ML research engineering remains difficult: agents must sustain coherent progress across task comprehension, environment setup, implementation, experimentation, and debugging over hours or days. We introduce AiScientist, a system for autonomous long-horizon engineering for ML research built on a simple principle: strong long-horizon performance requires both structured orchestration and durable state continuity. To this end, AiScientist combines hierarchical orchestration with a permission-scoped File-as-Bus workspace: a top-level Orchestrator maintains stage-level control through concise summaries and a workspace map, while specialized agents repeatedly re-ground on durable artifacts such as analyses, plans, code, and experimental evidence rather than relying primarily on conversational handoffs, yielding thin control over thick state. Across two complementary benchmarks, AiScientist improves PaperBench score by 10.54 points on average over the best matched baseline and achieves 81.82 Any Medal% on MLE-Bench Lite. Ablation studies further show that File-as-Bus protocol is a key driver of performance, reducing PaperBench by 6.41 points and MLE-Bench Lite by 31.82 points when removed. These results suggest that long-horizon ML research engineering is a systems problem of coordinating specialized work over durable project state, rather than a purely local reasoning problem.
BeyondSWE: Can Current Code Agent Survive Beyond Single-Repo Bug Fixing?
Mar 03, 2026Current benchmarks for code agents primarily assess narrow, repository-specific fixes, overlooking critical real-world challenges such as cross-repository reasoning, domain-specialized problem solving, dependency-driven migration, and full-repository generation. To address this gap, we introduce BeyondSWE, a comprehensive benchmark that broadens existing evaluations along two axes - resolution scope and knowledge scope - using 500 real-world instances across four distinct settings. Experimental results reveal a significant capability gap: even frontier models plateau below 45% success, and no single model performs consistently across task types. To systematically investigate the role of external knowledge, we develop SearchSWE, a framework that integrates deep search with coding abilities. Our experiments show that search augmentation yields inconsistent gains and can in some cases degrade performance, highlighting the difficulty of emulating developer-like workflows that interleave search and reasoning during coding tasks. This work offers both a realistic, challenging evaluation benchmark and a flexible framework to advance research toward more capable code agents.
Quantize More, Lose Less: Autoregressive Generation from Residually Quantized Speech Representations
Jul 16, 2025



Text-to-speech (TTS) synthesis has seen renewed progress under the discrete modeling paradigm. Existing autoregressive approaches often rely on single-codebook representations, which suffer from significant information loss. Even with post-hoc refinement techniques such as flow matching, these methods fail to recover fine-grained details (e.g., prosodic nuances, speaker-specific timbres), especially in challenging scenarios like singing voice or music synthesis. We propose QTTS, a novel TTS framework built upon our new audio codec, QDAC. The core innovation of QDAC lies in its end-to-end training of an ASR-based auto-regressive network with a GAN, which achieves superior semantic feature disentanglement for scalable, near-lossless compression. QTTS models these discrete codes using two innovative strategies: the Hierarchical Parallel architecture, which uses a dual-AR structure to model inter-codebook dependencies for higher-quality synthesis, and the Delay Multihead approach, which employs parallelized prediction with a fixed delay to accelerate inference speed. Our experiments demonstrate that the proposed framework achieves higher synthesis quality and better preserves expressive content compared to baseline. This suggests that scaling up compression via multi-codebook modeling is a promising direction for high-fidelity, general-purpose speech and audio generation.
Sound Explanation for Trustworthy Machine Learning
Jun 08, 2023

We take a formal approach to the explainability problem of machine learning systems. We argue against the practice of interpreting black-box models via attributing scores to input components due to inherently conflicting goals of attribution-based interpretation. We prove that no attribution algorithm satisfies specificity, additivity, completeness, and baseline invariance. We then formalize the concept, sound explanation, that has been informally adopted in prior work. A sound explanation entails providing sufficient information to causally explain the predictions made by a system. Finally, we present the application of feature selection as a sound explanation for cancer prediction models to cultivate trust among clinicians.
Effective Neural Network $L_0$ Regularization With BinMask
Apr 21, 2023



$L_0$ regularization of neural networks is a fundamental problem. In addition to regularizing models for better generalizability, $L_0$ regularization also applies to selecting input features and training sparse neural networks. There is a large body of research on related topics, some with quite complicated methods. In this paper, we show that a straightforward formulation, BinMask, which multiplies weights with deterministic binary masks and uses the identity straight-through estimator for backpropagation, is an effective $L_0$ regularizer. We evaluate BinMask on three tasks: feature selection, network sparsification, and model regularization. Despite its simplicity, BinMask achieves competitive performance on all the benchmarks without task-specific tuning compared to methods designed for each task. Our results suggest that decoupling weights from mask optimization, which has been widely adopted by previous work, is a key component for effective $L_0$ regularization.
Delving Deep into Pixel Alignment Feature for Accurate Multi-view Human Mesh Recovery
Jan 15, 2023



Regression-based methods have shown high efficiency and effectiveness for multi-view human mesh recovery. The key components of a typical regressor lie in the feature extraction of input views and the fusion of multi-view features. In this paper, we present Pixel-aligned Feedback Fusion (PaFF) for accurate yet efficient human mesh recovery from multi-view images. PaFF is an iterative regression framework that performs feature extraction and fusion alternately. At each iteration, PaFF extracts pixel-aligned feedback features from each input view according to the reprojection of the current estimation and fuses them together with respect to each vertex of the downsampled mesh. In this way, our regressor can not only perceive the misalignment status of each view from the feedback features but also correct the mesh parameters more effectively based on the feature fusion on mesh vertices. Additionally, our regressor disentangles the global orientation and translation of the body mesh from the estimation of mesh parameters such that the camera parameters of input views can be better utilized in the regression process. The efficacy of our method is validated in the Human3.6M dataset via comprehensive ablation experiments, where PaFF achieves 33.02 MPJPE and brings significant improvements over the previous best solutions by more than 29%. The project page with code and video results can be found at https://kairobo.github.io/PaFF/.
Verifying Low-dimensional Input Neural Networks via Input Quantization
Aug 18, 2021

Deep neural networks are an attractive tool for compressing the control policy lookup tables in systems such as the Airborne Collision Avoidance System (ACAS). It is vital to ensure the safety of such neural controllers via verification techniques. The problem of analyzing ACAS Xu networks has motivated many successful neural network verifiers. These verifiers typically analyze the internal computation of neural networks to decide whether a property regarding the input/output holds. The intrinsic complexity of neural network computation renders such verifiers slow to run and vulnerable to floating-point error. This paper revisits the original problem of verifying ACAS Xu networks. The networks take low-dimensional sensory inputs with training data provided by a precomputed lookup table. We propose to prepend an input quantization layer to the network. Quantization allows efficient verification via input state enumeration, whose complexity is bounded by the size of the quantization space. Quantization is equivalent to nearest-neighbor interpolation at run time, which has been shown to provide acceptable accuracy for ACAS in simulation. Moreover, our technique can deliver exact verification results immune to floating-point error if we directly enumerate the network outputs on the target inference implementation or on an accurate simulation of the target implementation.
Deep Retrieval: An End-to-End Learnable Structure Model for Large-Scale Recommendations
Jul 12, 2020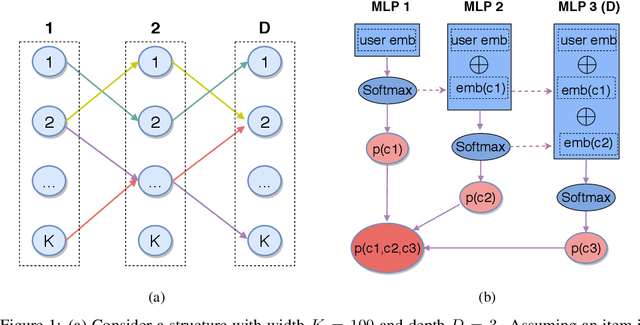
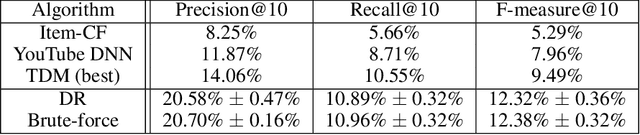
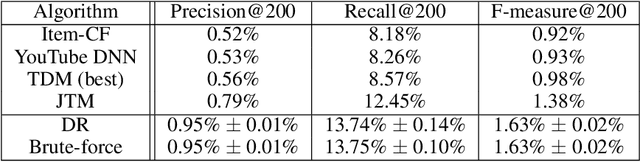
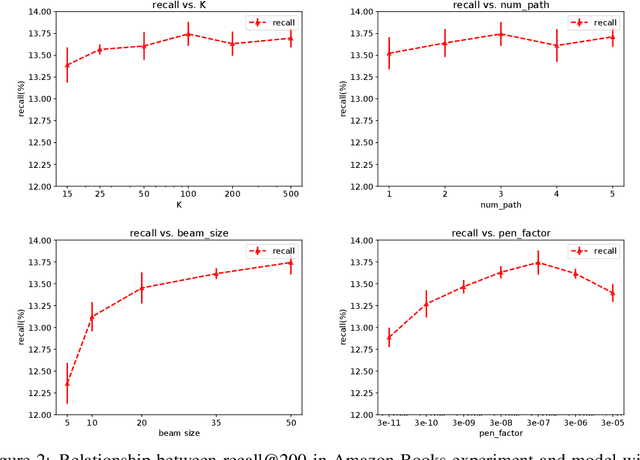
One of the core problems in large-scale recommendations is to retrieve top relevant candidates accurately and efficiently, preferably in sub-linear time. Previous approaches are mostly based on a two-step procedure: first learn an inner-product model and then use maximum inner product search (MIPS) algorithms to search top candidates, leading to potential loss of retrieval accuracy. In this paper, we present Deep Retrieval (DR), an end-to-end learnable structure model for large-scale recommendations. DR encodes all candidates into a discrete latent space. Those latent codes for the candidates are model parameters and to be learnt together with other neural network parameters to maximize the same objective function. With the model learnt, a beam search over the latent codes is performed to retrieve the top candidates. Empirically, we showed that DR, with sub-linear computational complexity, can achieve almost the same accuracy as the brute-force baseline.
Efficient Exact Verification of Binarized Neural Networks
May 07, 2020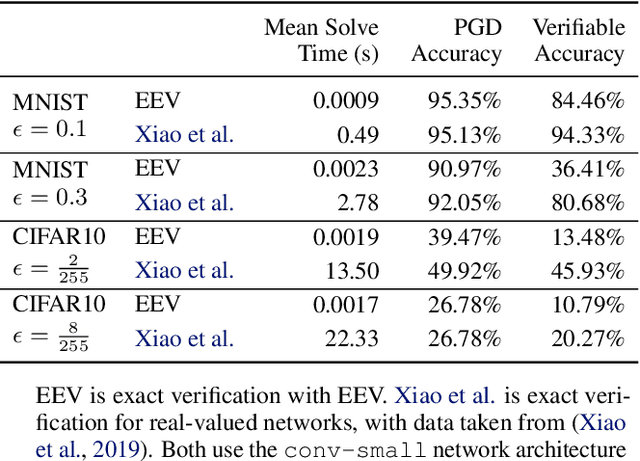
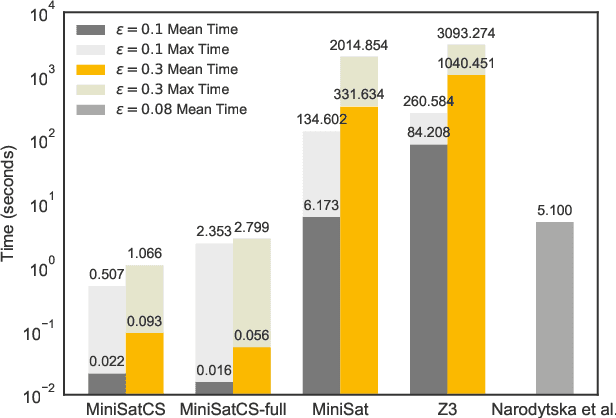
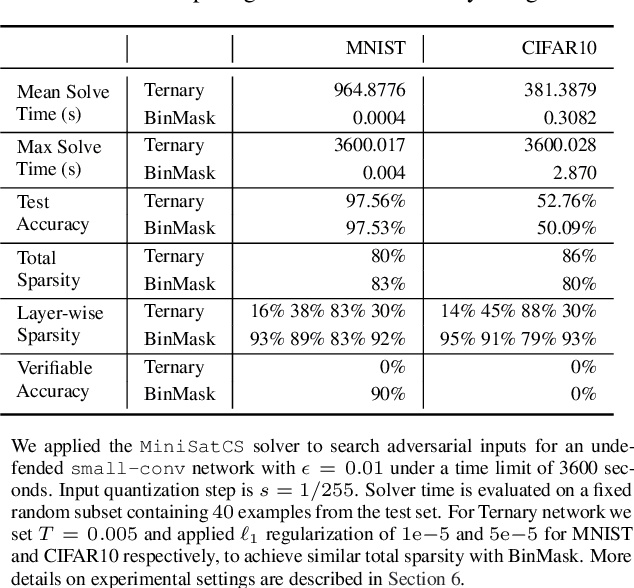
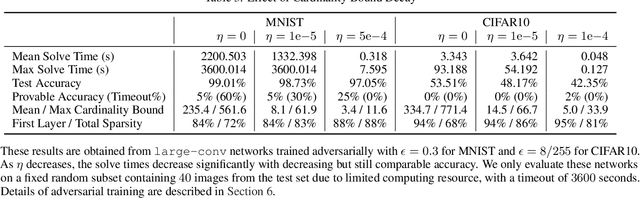
We present a new system, EEV, for verifying binarized neural networks (BNNs). We formulate BNN verification as a Boolean satisfiability problem (SAT) with reified cardinality constraints of the form $y = (x_1 + \cdots + x_n \le b)$, where $x_i$ and $y$ are Boolean variables possibly with negation and $b$ is an integer constant. We also identify two properties, specifically balanced weight sparsity and lower cardinality bounds, that reduce the verification complexity of BNNs. EEV contains both a SAT solver enhanced to handle reified cardinality constraints natively and novel training strategies designed to reduce verification complexity by delivering networks with improved sparsity properties and cardinality bounds. We demonstrate the effectiveness of EEV by presenting the first exact verification results for $\ell_{\infty}$-bounded adversarial robustness of nontrivial convolutional BNNs on the MNIST and CIFAR10 datasets. Our results also show that, depending on the dataset and network architecture, our techniques verify BNNs between a factor of ten to ten thousand times faster than the best previous exact verification techniques for either binarized or real-valued networks.
Exploiting Verified Neural Networks via Floating Point Numerical Error
Mar 06, 2020
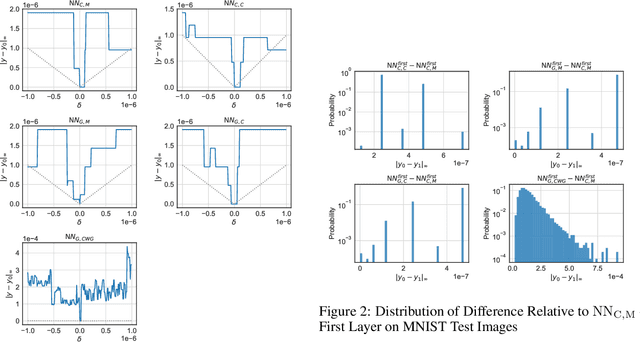


We show how to construct adversarial examples for neural networks with exactly verified robustness against $\ell_{\infty}$-bounded input perturbations by exploiting floating point error. We argue that any exact verification of real-valued neural networks must accurately model the implementation details of any floating point arithmetic used during inference or verification.