 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeT5Gemma 2: Seeing, Reading, and Understanding Longer
Dec 23, 2025We introduce T5Gemma 2, the next generation of the T5Gemma family of lightweight open encoder-decoder models, featuring strong multilingual, multimodal and long-context capabilities. T5Gemma 2 follows the adaptation recipe (via UL2) in T5Gemma -- adapting a pretrained decoder-only model into an encoder-decoder model, and extends it from text-only regime to multimodal based on the Gemma 3 models. We further propose two methods to improve the efficiency: tied word embedding that shares all embeddings across encoder and decoder, and merged attention that unifies decoder self- and cross-attention into a single joint module. Experiments demonstrate the generality of the adaptation strategy over architectures and modalities as well as the unique strength of the encoder-decoder architecture on long context modeling. Similar to T5Gemma, T5Gemma 2 yields comparable or better pretraining performance and significantly improved post-training performance than its Gemma 3 counterpart. We release the pretrained models (270M-270M, 1B-1B and 4B-4B) to the community for future research.
Gemma 3 Technical Report
Mar 25, 2025We introduce Gemma 3, a multimodal addition to the Gemma family of lightweight open models, ranging in scale from 1 to 27 billion parameters. This version introduces vision understanding abilities, a wider coverage of languages and longer context - at least 128K tokens. We also change the architecture of the model to reduce the KV-cache memory that tends to explode with long context. This is achieved by increasing the ratio of local to global attention layers, and keeping the span on local attention short. The Gemma 3 models are trained with distillation and achieve superior performance to Gemma 2 for both pre-trained and instruction finetuned versions. In particular, our novel post-training recipe significantly improves the math, chat, instruction-following and multilingual abilities, making Gemma3-4B-IT competitive with Gemma2-27B-IT and Gemma3-27B-IT comparable to Gemini-1.5-Pro across benchmarks. We release all our models to the community.
Jackpot! Alignment as a Maximal Lottery
Jan 31, 2025Reinforcement Learning from Human Feedback (RLHF), the standard for aligning Large Language Models (LLMs) with human values, is known to fail to satisfy properties that are intuitively desirable, such as respecting the preferences of the majority \cite{ge2024axioms}. To overcome these issues, we propose the use of a probabilistic Social Choice rule called \emph{maximal lotteries} as a replacement for RLHF. We show that a family of alignment techniques, namely Nash Learning from Human Feedback (NLHF) \cite{munos2023nash} and variants, approximate maximal lottery outcomes and thus inherit its beneficial properties. We confirm experimentally that our proposed methodology handles situations that arise when working with preferences more robustly than standard RLHF, including supporting the preferences of the majority, providing principled ways of handling non-transitivities in the preference data, and robustness to irrelevant alternatives. This results in systems that better incorporate human values and respect human intentions.
Utility-inspired Reward Transformations Improve Reinforcement Learning Training of Language Models
Jan 08, 2025Current methods that train large language models (LLMs) with reinforcement learning feedback, often resort to averaging outputs of multiple rewards functions during training. This overlooks crucial aspects of individual reward dimensions and inter-reward dependencies that can lead to sub-optimal outcomes in generations. In this work, we show how linear aggregation of rewards exhibits some vulnerabilities that can lead to undesired properties of generated text. We then propose a transformation of reward functions inspired by economic theory of utility functions (specifically Inada conditions), that enhances sensitivity to low reward values while diminishing sensitivity to already high values. We compare our approach to the existing baseline methods that linearly aggregate rewards and show how the Inada-inspired reward feedback is superior to traditional weighted averaging. We quantitatively and qualitatively analyse the difference in the methods, and see that models trained with Inada-transformations score as more helpful while being less harmful.
Gemma 2: Improving Open Language Models at a Practical Size
Aug 02, 2024



In this work, we introduce Gemma 2, a new addition to the Gemma family of lightweight, state-of-the-art open models, ranging in scale from 2 billion to 27 billion parameters. In this new version, we apply several known technical modifications to the Transformer architecture, such as interleaving local-global attentions (Beltagy et al., 2020a) and group-query attention (Ainslie et al., 2023). We also train the 2B and 9B models with knowledge distillation (Hinton et al., 2015) instead of next token prediction. The resulting models deliver the best performance for their size, and even offer competitive alternatives to models that are 2-3 times bigger. We release all our models to the community.
Learning rich touch representations through cross-modal self-supervision
Jan 21, 2021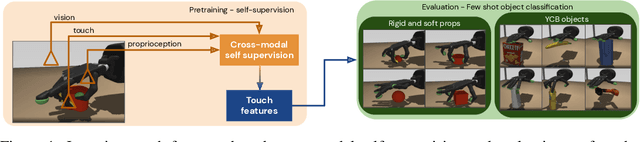
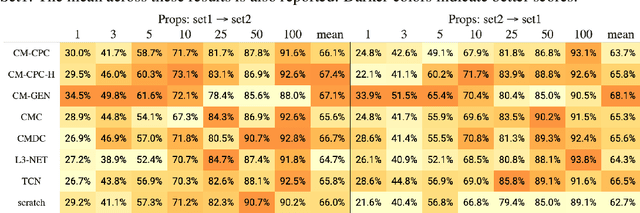
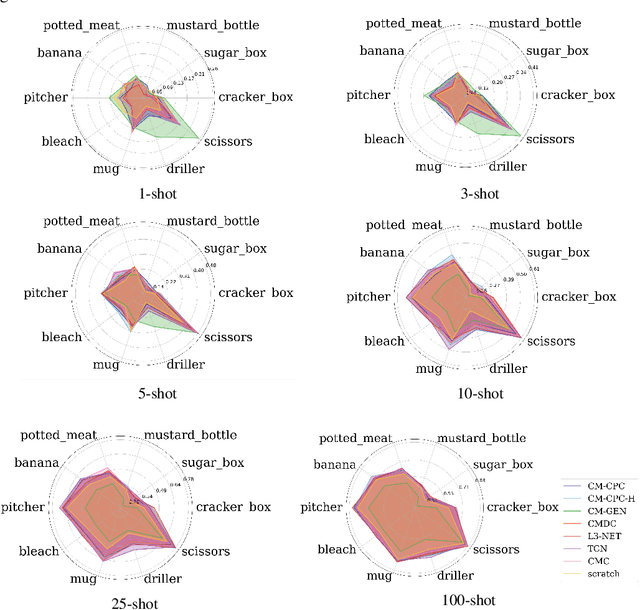
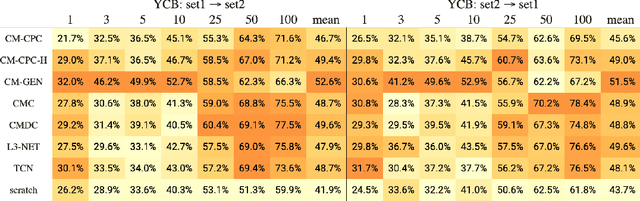
The sense of touch is fundamental in several manipulation tasks, but rarely used in robot manipulation. In this work we tackle the problem of learning rich touch features from cross-modal self-supervision. We evaluate them identifying objects and their properties in a few-shot classification setting. Two new datasets are introduced using a simulated anthropomorphic robotic hand equipped with tactile sensors on both synthetic and daily life objects. Several self-supervised learning methods are benchmarked on these datasets, by evaluating few-shot classification on unseen objects and poses. Our experiments indicate that cross-modal self-supervision effectively improves touch representation, and in turn has great potential to enhance robot manipulation skills.
Temporal Difference Uncertainties as a Signal for Exploration
Oct 05, 2020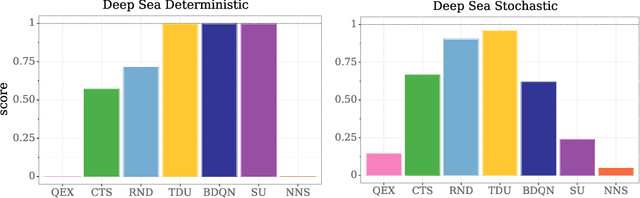
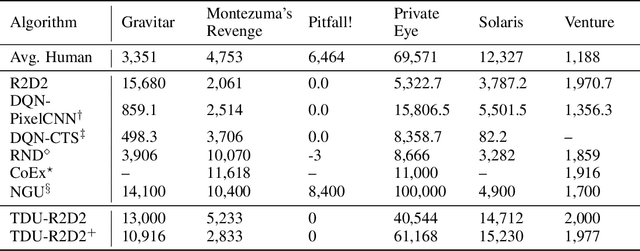
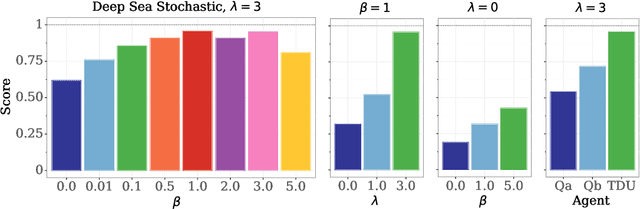

An effective approach to exploration in reinforcement learning is to rely on an agent's uncertainty over the optimal policy, which can yield near-optimal exploration strategies in tabular settings. However, in non-tabular settings that involve function approximators, obtaining accurate uncertainty estimates is almost as challenging a problem. In this paper, we highlight that value estimates are easily biased and temporally inconsistent. In light of this, we propose a novel method for estimating uncertainty over the value function that relies on inducing a distribution over temporal difference errors. This exploration signal controls for state-action transitions so as to isolate uncertainty in value that is due to uncertainty over the agent's parameters. Because our measure of uncertainty conditions on state-action transitions, we cannot act on this measure directly. Instead, we incorporate it as an intrinsic reward and treat exploration as a separate learning problem, induced by the agent's temporal difference uncertainties. We introduce a distinct exploration policy that learns to collect data with high estimated uncertainty, which gives rise to a curriculum that smoothly changes throughout learning and vanishes in the limit of perfect value estimates. We evaluate our method on hard exploration tasks, including Deep Sea and Atari 2600 environments and find that our proposed form of exploration facilitates both diverse and deep exploration.
Small Data, Big Decisions: Model Selection in the Small-Data Regime
Sep 26, 2020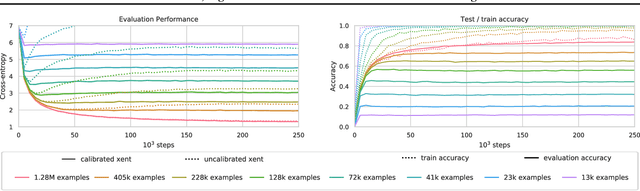

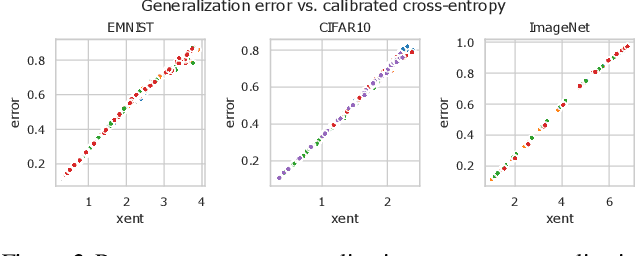

Highly overparametrized neural networks can display curiously strong generalization performance - a phenomenon that has recently garnered a wealth of theoretical and empirical research in order to better understand it. In contrast to most previous work, which typically considers the performance as a function of the model size, in this paper we empirically study the generalization performance as the size of the training set varies over multiple orders of magnitude. These systematic experiments lead to some interesting and potentially very useful observations; perhaps most notably that training on smaller subsets of the data can lead to more reliable model selection decisions whilst simultaneously enjoying smaller computational costs. Our experiments furthermore allow us to estimate Minimum Description Lengths for common datasets given modern neural network architectures, thereby paving the way for principled model selection taking into account Occams-razor.
Continual Unsupervised Representation Learning
Oct 31, 2019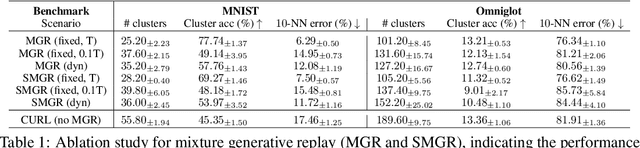
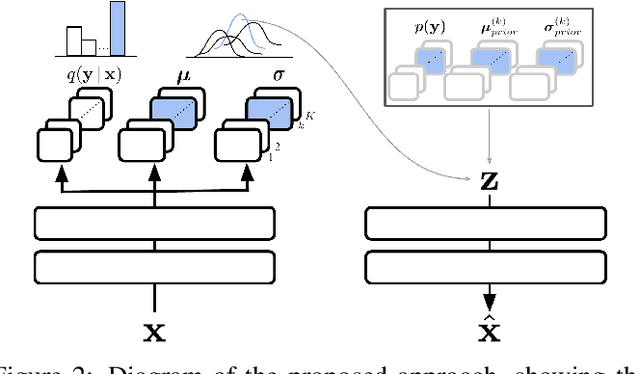

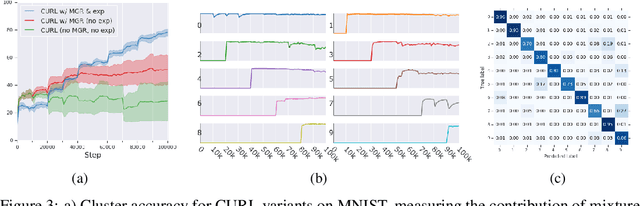
Continual learning aims to improve the ability of modern learning systems to deal with non-stationary distributions, typically by attempting to learn a series of tasks sequentially. Prior art in the field has largely considered supervised or reinforcement learning tasks, and often assumes full knowledge of task labels and boundaries. In this work, we propose an approach (CURL) to tackle a more general problem that we will refer to as unsupervised continual learning. The focus is on learning representations without any knowledge about task identity, and we explore scenarios when there are abrupt changes between tasks, smooth transitions from one task to another, or even when the data is shuffled. The proposed approach performs task inference directly within the model, is able to dynamically expand to capture new concepts over its lifetime, and incorporates additional rehearsal-based techniques to deal with catastrophic forgetting. We demonstrate the efficacy of CURL in an unsupervised learning setting with MNIST and Omniglot, where the lack of labels ensures no information is leaked about the task. Further, we demonstrate strong performance compared to prior art in an i.i.d setting, or when adapting the technique to supervised tasks such as incremental class learning.
ReConvNet: Video Object Segmentation with Spatio-Temporal Features Modulation
Jun 18, 2018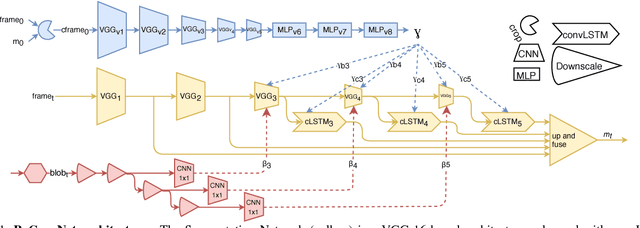
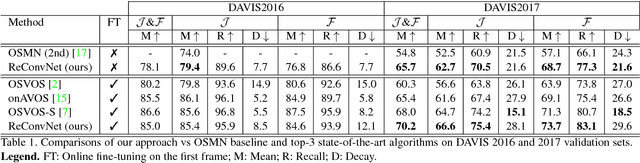
We introduce ReConvNet, a recurrent convolutional architecture for semi-supervised video object segmentation that is able to fast adapt its features to focus on any specific object of interest at inference time. Generalization to new objects never observed during training is known to be a hard task for supervised approaches that would need to be retrained. To tackle this problem, we propose a more efficient solution that learns spatio-temporal features self-adapting to the object of interest via conditional affine transformations. This approach is simple, can be trained end-to-end and does not necessarily require extra training steps at inference time. Our method shows competitive results on DAVIS2016 with respect to state-of-the art approaches that use online fine-tuning, and outperforms them on DAVIS2017. ReConvNet shows also promising results on the DAVIS-Challenge 2018 winning the $10$-th position.