 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReasonCACHE: Teaching LLMs To Reason Without Weight Updates
Feb 02, 2026Can Large language models (LLMs) learn to reason without any weight update and only through in-context learning (ICL)? ICL is strikingly sample-efficient, often learning from only a handful of demonstrations, but complex reasoning tasks typically demand many training examples to learn from. However, naively scaling ICL by adding more demonstrations breaks down at this scale: attention costs grow quadratically, performance saturates or degrades with longer contexts, and the approach remains a shallow form of learning. Due to these limitations, practitioners predominantly rely on in-weight learning (IWL) to induce reasoning. In this work, we show that by using Prefix Tuning, LLMs can learn to reason without overloading the context window and without any weight updates. We introduce $\textbf{ReasonCACHE}$, an instantiation of this mechanism that distills demonstrations into a fixed key-value cache. Empirically, across challenging reasoning benchmarks, including GPQA-Diamond, ReasonCACHE outperforms standard ICL and matches or surpasses IWL approaches. Further, it achieves this all while being more efficient across three key axes: data, inference cost, and trainable parameters. We also theoretically prove that ReasonCACHE can be strictly more expressive than low-rank weight update since the latter ties expressivity to input rank, whereas ReasonCACHE bypasses this constraint by directly injecting key-values into the attention mechanism. Together, our findings identify ReasonCACHE as a middle path between in-context and in-weight learning, providing a scalable algorithm for learning reasoning skills beyond the context window without modifying parameters. Our project page: https://reasoncache.github.io/
Why Less is More (Sometimes): A Theory of Data Curation
Nov 05, 2025



This paper introduces a theoretical framework to resolve a central paradox in modern machine learning: When is it better to use less data? This question has become critical as classical scaling laws suggesting ``more is more'' (Sun et al., 2025) are challenged by methods like LIMO (``less is more'') and s1 (Ye et al., 2025; Muenighoff et al., 2025), which achieve superior performance with small, aggressively curated datasets. Here, we study data curation strategies where an imperfect oracle selects the training examples according to their difficulty and correctness. Our results provide exact scaling law curves for test error under both label-agnostic and label-aware curation rules, revealing when and why keeping only a subset of data can improve generalization. In contrast to classical scaling laws, we show that under certain conditions, small curated datasets can outperform full datasets, and we provide analytical conditions for this by deriving precise phase transition curves tied to data size and quality. We validate these theoretical claims with empirical results on ImageNet, confirming our predictions about when curation improves accuracy and can even mitigate model collapse. Furthermore, our framework provides a principled explanation for the contradictory curation strategies recently observed in LLM mathematical reasoning.
Improving the Scaling Laws of Synthetic Data with Deliberate Practice
Feb 21, 2025



Inspired by the principle of deliberate practice in human learning, we propose Deliberate Practice for Synthetic Data Generation (DP), a novel framework that improves sample efficiency through dynamic synthetic data generation. Prior work has shown that scaling synthetic data is inherently challenging, as naively adding new data leads to diminishing returns. To address this, pruning has been identified as a key mechanism for improving scaling, enabling models to focus on the most informative synthetic samples. Rather than generating a large dataset and pruning it afterward, DP efficiently approximates the direct generation of informative samples. We theoretically show how training on challenging, informative examples improves scaling laws and empirically validate that DP achieves better scaling performance with significantly fewer training samples and iterations. On ImageNet-100, DP generates 3.4x fewer samples and requires six times fewer iterations, while on ImageNet-1k, it generates 8x fewer samples with a 30 percent reduction in iterations, all while achieving superior performance compared to prior work.
The Pitfalls of Memorization: When Memorization Hurts Generalization
Dec 10, 2024



Neural networks often learn simple explanations that fit the majority of the data while memorizing exceptions that deviate from these explanations.This behavior leads to poor generalization when the learned explanations rely on spurious correlations. In this work, we formalize the interplay between memorization and generalization, showing that spurious correlations would particularly lead to poor generalization when are combined with memorization. Memorization can reduce training loss to zero, leaving no incentive to learn robust, generalizable patterns. To address this, we propose memorization-aware training (MAT), which uses held-out predictions as a signal of memorization to shift a model's logits. MAT encourages learning robust patterns invariant across distributions, improving generalization under distribution shifts.
Compositional Risk Minimization
Oct 08, 2024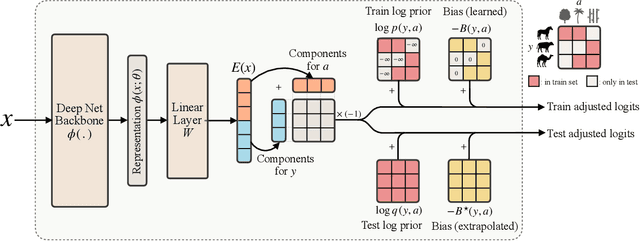


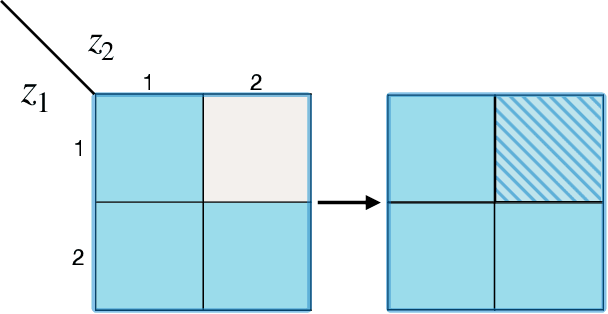
In this work, we tackle a challenging and extreme form of subpopulation shift, which is termed compositional shift. Under compositional shifts, some combinations of attributes are totally absent from the training distribution but present in the test distribution. We model the data with flexible additive energy distributions, where each energy term represents an attribute, and derive a simple alternative to empirical risk minimization termed compositional risk minimization (CRM). We first train an additive energy classifier to predict the multiple attributes and then adjust this classifier to tackle compositional shifts. We provide an extensive theoretical analysis of CRM, where we show that our proposal extrapolates to special affine hulls of seen attribute combinations. Empirical evaluations on benchmark datasets confirms the improved robustness of CRM compared to other methods from the literature designed to tackle various forms of subpopulation shifts.
Feedback-guided Data Synthesis for Imbalanced Classification
Sep 29, 2023Current status quo in machine learning is to use static datasets of real images for training, which often come from long-tailed distributions. With the recent advances in generative models, researchers have started augmenting these static datasets with synthetic data, reporting moderate performance improvements on classification tasks. We hypothesize that these performance gains are limited by the lack of feedback from the classifier to the generative model, which would promote the usefulness of the generated samples to improve the classifier's performance. In this work, we introduce a framework for augmenting static datasets with useful synthetic samples, which leverages one-shot feedback from the classifier to drive the sampling of the generative model. In order for the framework to be effective, we find that the samples must be close to the support of the real data of the task at hand, and be sufficiently diverse. We validate three feedback criteria on a long-tailed dataset (ImageNet-LT) as well as a group-imbalanced dataset (NICO++). On ImageNet-LT, we achieve state-of-the-art results, with over 4 percent improvement on underrepresented classes while being twice efficient in terms of the number of generated synthetic samples. NICO++ also enjoys marked boosts of over 5 percent in worst group accuracy. With these results, our framework paves the path towards effectively leveraging state-of-the-art text-to-image models as data sources that can be queried to improve downstream applications.
Discovering environments with XRM
Sep 28, 2023



Successful out-of-distribution generalization requires environment annotations. Unfortunately, these are resource-intensive to obtain, and their relevance to model performance is limited by the expectations and perceptual biases of human annotators. Therefore, to enable robust AI systems across applications, we must develop algorithms to automatically discover environments inducing broad generalization. Current proposals, which divide examples based on their training error, suffer from one fundamental problem. These methods add hyper-parameters and early-stopping criteria that are impossible to tune without a validation set with human-annotated environments, the very information subject to discovery. In this paper, we propose Cross-Risk-Minimization (XRM) to address this issue. XRM trains two twin networks, each learning from one random half of the training data, while imitating confident held-out mistakes made by its sibling. XRM provides a recipe for hyper-parameter tuning, does not require early-stopping, and can discover environments for all training and validation data. Domain generalization algorithms built on top of XRM environments achieve oracle worst-group-accuracy, solving a long-standing problem in out-of-distribution generalization.
Predicting Grokking Long Before it Happens: A look into the loss landscape of models which grok
Jun 23, 2023



This paper focuses on predicting the occurrence of grokking in neural networks, a phenomenon in which perfect generalization emerges long after signs of overfitting or memorization are observed. It has been reported that grokking can only be observed with certain hyper-parameters. This makes it critical to identify the parameters that lead to grokking. However, since grokking occurs after a large number of epochs, searching for the hyper-parameters that lead to it is time-consuming. In this paper, we propose a low-cost method to predict grokking without training for a large number of epochs. In essence, by studying the learning curve of the first few epochs, we show that one can predict whether grokking will occur later on. Specifically, if certain oscillations occur in the early epochs, one can expect grokking to occur if the model is trained for a much longer period of time. We propose using the spectral signature of a learning curve derived by applying the Fourier transform to quantify the amplitude of low-frequency components to detect the presence of such oscillations. We also present additional experiments aimed at explaining the cause of these oscillations and characterizing the loss landscape.
Multi-scale Feature Learning Dynamics: Insights for Double Descent
Dec 06, 2021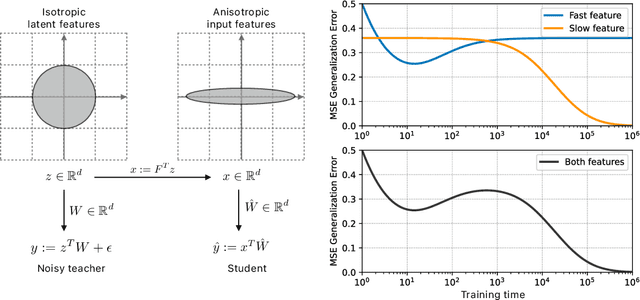
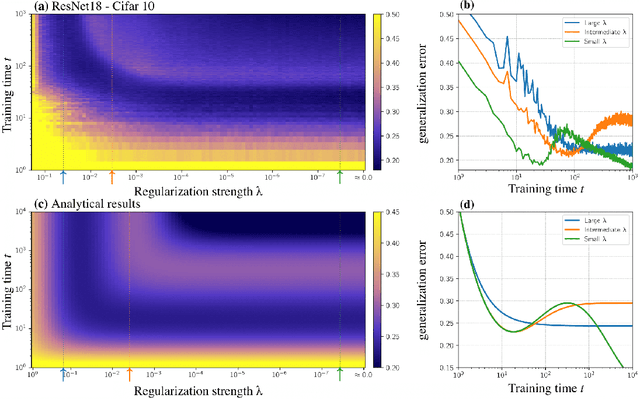
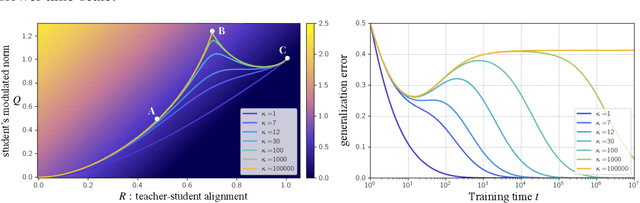
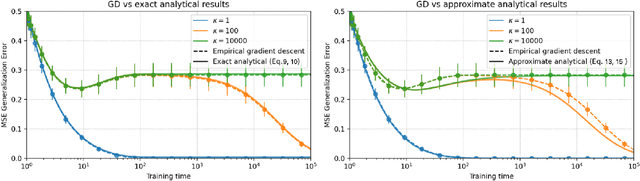
A key challenge in building theoretical foundations for deep learning is the complex optimization dynamics of neural networks, resulting from the high-dimensional interactions between the large number of network parameters. Such non-trivial dynamics lead to intriguing behaviors such as the phenomenon of "double descent" of the generalization error. The more commonly studied aspect of this phenomenon corresponds to model-wise double descent where the test error exhibits a second descent with increasing model complexity, beyond the classical U-shaped error curve. In this work, we investigate the origins of the less studied epoch-wise double descent in which the test error undergoes two non-monotonous transitions, or descents as the training time increases. By leveraging tools from statistical physics, we study a linear teacher-student setup exhibiting epoch-wise double descent similar to that in deep neural networks. In this setting, we derive closed-form analytical expressions for the evolution of generalization error over training. We find that double descent can be attributed to distinct features being learned at different scales: as fast-learning features overfit, slower-learning features start to fit, resulting in a second descent in test error. We validate our findings through numerical experiments where our theory accurately predicts empirical findings and remains consistent with observations in deep neural networks.
Simple data balancing achieves competitive worst-group-accuracy
Oct 27, 2021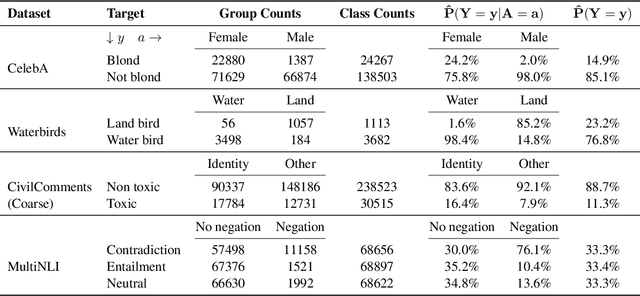
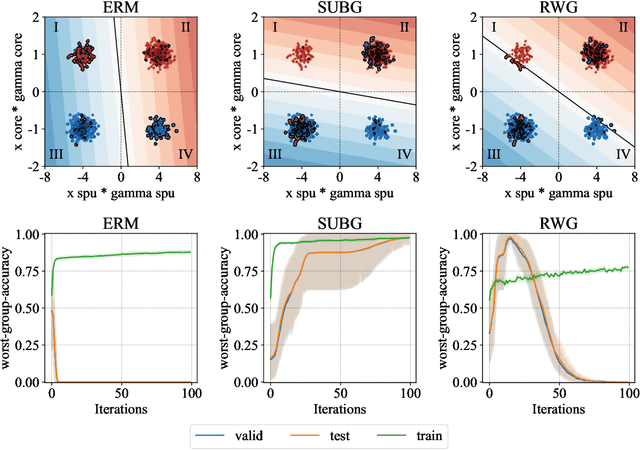
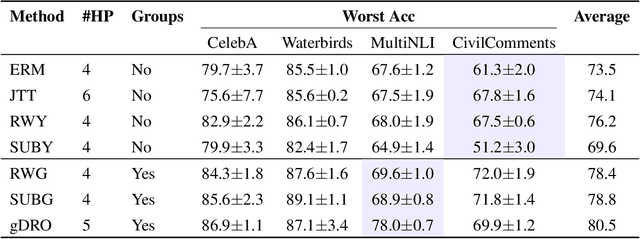
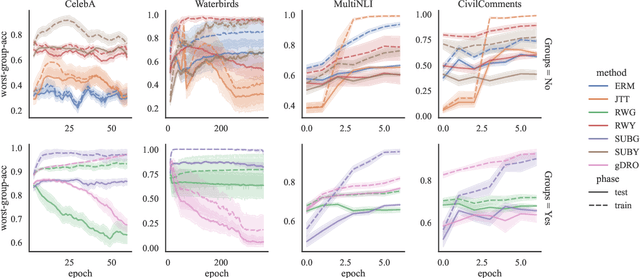
We study the problem of learning classifiers that perform well across (known or unknown) groups of data. After observing that common worst-group-accuracy datasets suffer from substantial imbalances, we set out to compare state-of-the-art methods to simple balancing of classes and groups by either subsampling or reweighting data. Our results show that these data balancing baselines achieve state-of-the-art-accuracy, while being faster to train and requiring no additional hyper-parameters. In addition, we highlight that access to group information is most critical for model selection purposes, and not so much during training. All in all, our findings beg closer examination of benchmarks and methods for research in worst-group-accuracy optimization.