 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Product Image Generation and Recommendation at Scale for Personalized E-commerce
Aug 22, 2024Coupling latent diffusion based image generation with contextual bandits enables the creation of eye-catching personalized product images at scale that was previously either impossible or too expensive. In this paper we showcase how we utilized these technologies to increase user engagement with recommendations in online retargeting campaigns for e-commerce.
Widespread Flaws in Offline Evaluation of Recommender Systems
Jul 27, 2023Even though offline evaluation is just an imperfect proxy of online performance -- due to the interactive nature of recommenders -- it will probably remain the primary way of evaluation in recommender systems research for the foreseeable future, since the proprietary nature of production recommenders prevents independent validation of A/B test setups and verification of online results. Therefore, it is imperative that offline evaluation setups are as realistic and as flawless as they can be. Unfortunately, evaluation flaws are quite common in recommender systems research nowadays, due to later works copying flawed evaluation setups from their predecessors without questioning their validity. In the hope of improving the quality of offline evaluation of recommender systems, we discuss four of these widespread flaws and why researchers should avoid them.
The Effect of Third Party Implementations on Reproducibility
Jul 27, 2023Reproducibility of recommender systems research has come under scrutiny during recent years. Along with works focusing on repeating experiments with certain algorithms, the research community has also started discussing various aspects of evaluation and how these affect reproducibility. We add a novel angle to this discussion by examining how unofficial third-party implementations could benefit or hinder reproducibility. Besides giving a general overview, we thoroughly examine six third-party implementations of a popular recommender algorithm and compare them to the official version on five public datasets. In the light of our alarming findings we aim to draw the attention of the research community to this neglected aspect of reproducibility.
Recurrent Neural Networks with Top-k Gains for Session-based Recommendations
Aug 28, 2018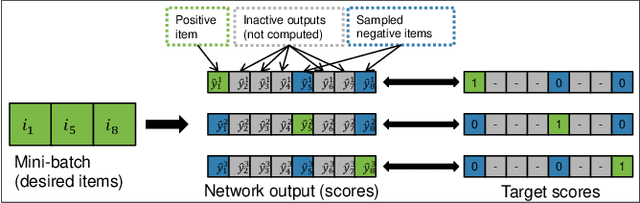
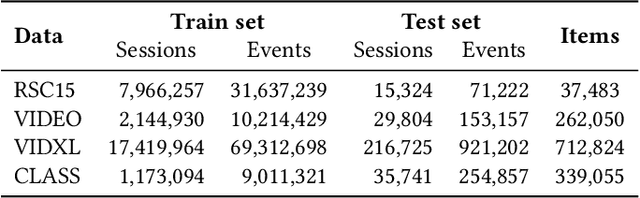
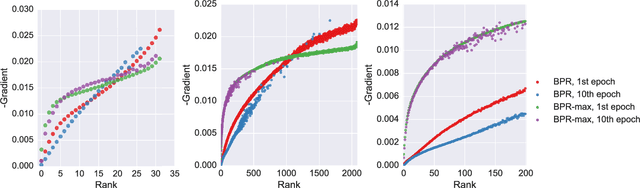
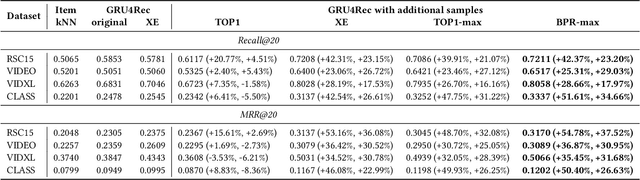
RNNs have been shown to be excellent models for sequential data and in particular for data that is generated by users in an session-based manner. The use of RNNs provides impressive performance benefits over classical methods in session-based recommendations. In this work we introduce novel ranking loss functions tailored to RNNs in the recommendation setting. The improved performance of these losses over alternatives, along with further tricks and refinements described in this work, allow for an overall improvement of up to 35% in terms of MRR and Recall@20 over previous session-based RNN solutions and up to 53% over classical collaborative filtering approaches. Unlike data augmentation-based improvements, our method does not increase training times significantly. We further demonstrate the performance gain of the RNN over baselines in an online A/B test.
Personalizing Session-based Recommendations with Hierarchical Recurrent Neural Networks
Aug 23, 2017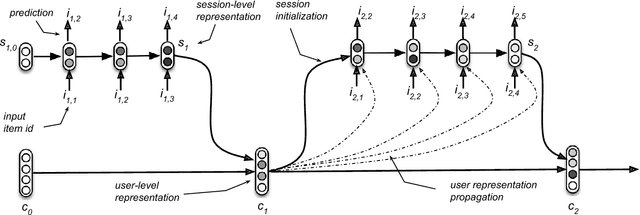
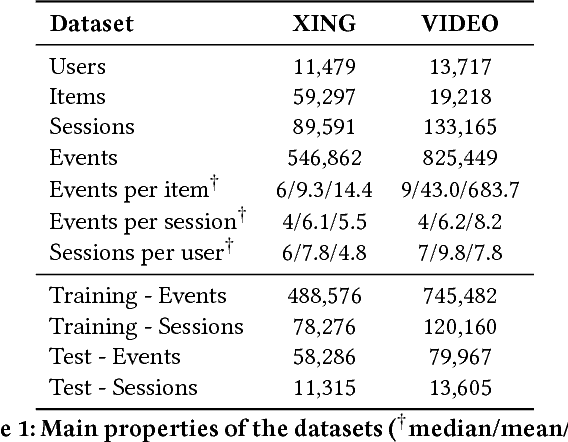
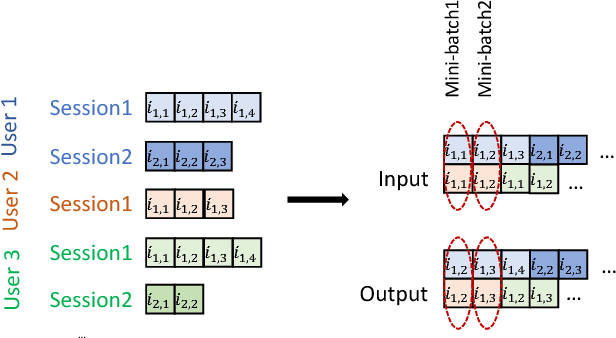
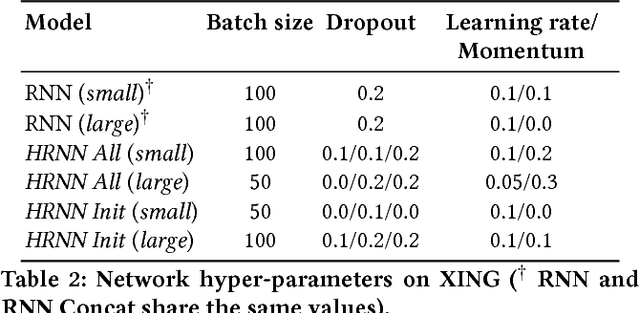
Session-based recommendations are highly relevant in many modern on-line services (e.g. e-commerce, video streaming) and recommendation settings. Recently, Recurrent Neural Networks have been shown to perform very well in session-based settings. While in many session-based recommendation domains user identifiers are hard to come by, there are also domains in which user profiles are readily available. We propose a seamless way to personalize RNN models with cross-session information transfer and devise a Hierarchical RNN model that relays end evolves latent hidden states of the RNNs across user sessions. Results on two industry datasets show large improvements over the session-only RNNs.
Theano: A Python framework for fast computation of mathematical expressions
May 09, 2016



Theano is a Python library that allows to define, optimize, and evaluate mathematical expressions involving multi-dimensional arrays efficiently. Since its introduction, it has been one of the most used CPU and GPU mathematical compilers - especially in the machine learning community - and has shown steady performance improvements. Theano is being actively and continuously developed since 2008, multiple frameworks have been built on top of it and it has been used to produce many state-of-the-art machine learning models. The present article is structured as follows. Section I provides an overview of the Theano software and its community. Section II presents the principal features of Theano and how to use them, and compares them with other similar projects. Section III focuses on recently-introduced functionalities and improvements. Section IV compares the performance of Theano against Torch7 and TensorFlow on several machine learning models. Section V discusses current limitations of Theano and potential ways of improving it.
Session-based Recommendations with Recurrent Neural Networks
Mar 29, 2016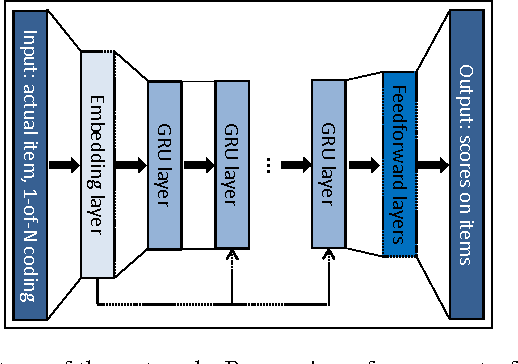
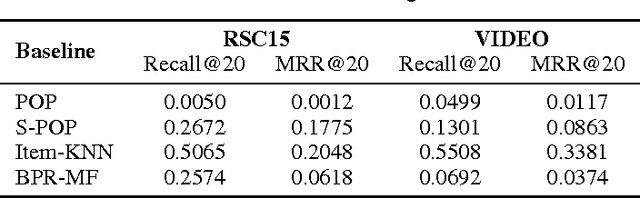
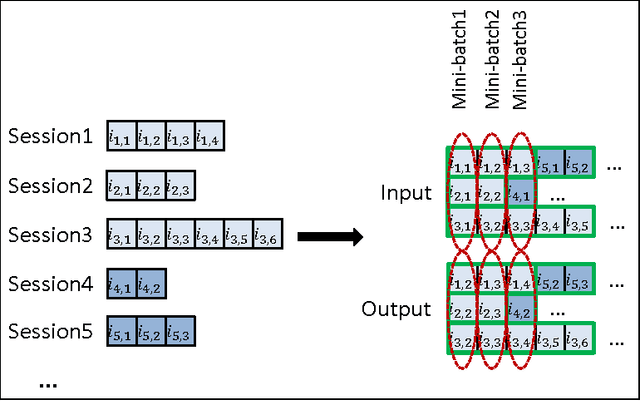
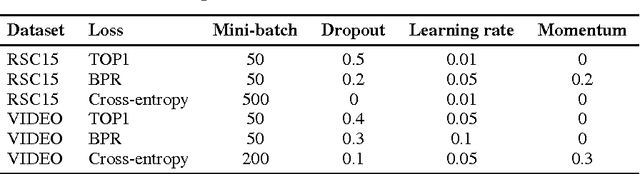
We apply recurrent neural networks (RNN) on a new domain, namely recommender systems. Real-life recommender systems often face the problem of having to base recommendations only on short session-based data (e.g. a small sportsware website) instead of long user histories (as in the case of Netflix). In this situation the frequently praised matrix factorization approaches are not accurate. This problem is usually overcome in practice by resorting to item-to-item recommendations, i.e. recommending similar items. We argue that by modeling the whole session, more accurate recommendations can be provided. We therefore propose an RNN-based approach for session-based recommendations. Our approach also considers practical aspects of the task and introduces several modifications to classic RNNs such as a ranking loss function that make it more viable for this specific problem. Experimental results on two data-sets show marked improvements over widely used approaches.
General factorization framework for context-aware recommendations
May 19, 2015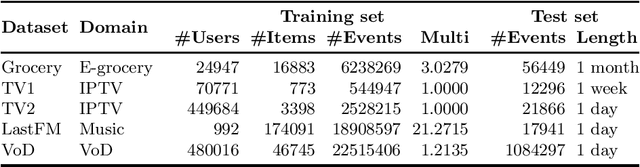
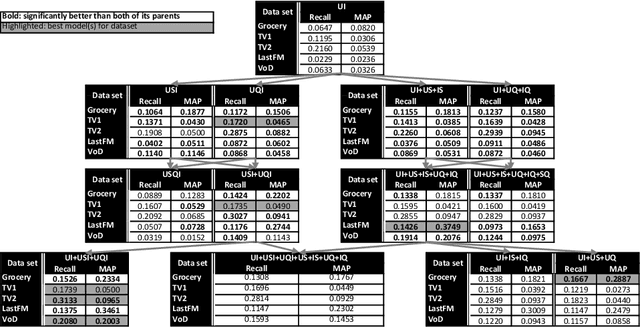

Context-aware recommendation algorithms focus on refining recommendations by considering additional information, available to the system. This topic has gained a lot of attention recently. Among others, several factorization methods were proposed to solve the problem, although most of them assume explicit feedback which strongly limits their real-world applicability. While these algorithms apply various loss functions and optimization strategies, the preference modeling under context is less explored due to the lack of tools allowing for easy experimentation with various models. As context dimensions are introduced beyond users and items, the space of possible preference models and the importance of proper modeling largely increases. In this paper we propose a General Factorization Framework (GFF), a single flexible algorithm that takes the preference model as an input and computes latent feature matrices for the input dimensions. GFF allows us to easily experiment with various linear models on any context-aware recommendation task, be it explicit or implicit feedback based. The scaling properties makes it usable under real life circumstances as well. We demonstrate the framework's potential by exploring various preference models on a 4-dimensional context-aware problem with contexts that are available for almost any real life datasets. We show in our experiments -- performed on five real life, implicit feedback datasets -- that proper preference modelling significantly increases recommendation accuracy, and previously unused models outperform the traditional ones. Novel models in GFF also outperform state-of-the-art factorization algorithms. We also extend the method to be fully compliant to the Multidimensional Dataspace Model, one of the most extensive data models of context-enriched data. Extended GFF allows the seamless incorporation of information into the fac[truncated]
Context-aware recommendations from implicit data via scalable tensor factorization
Sep 29, 2013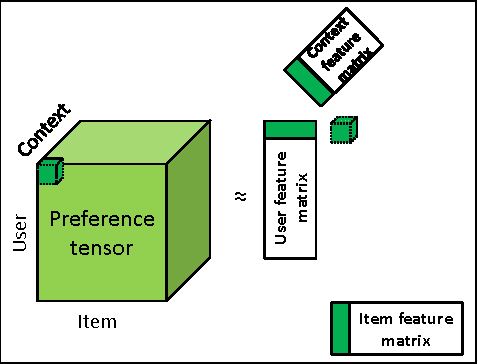
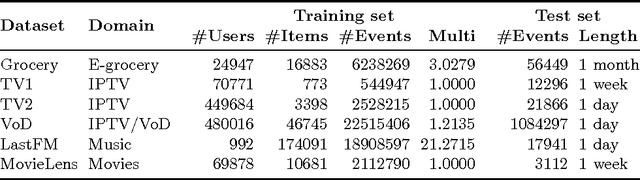
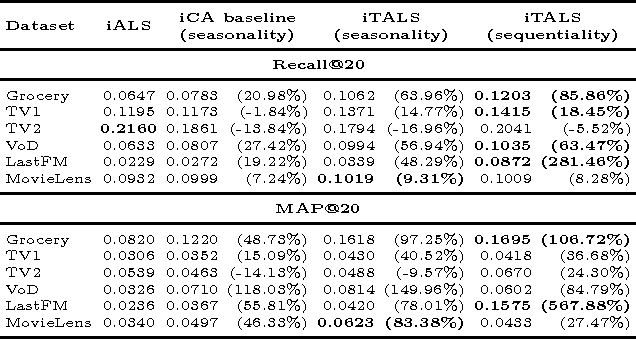
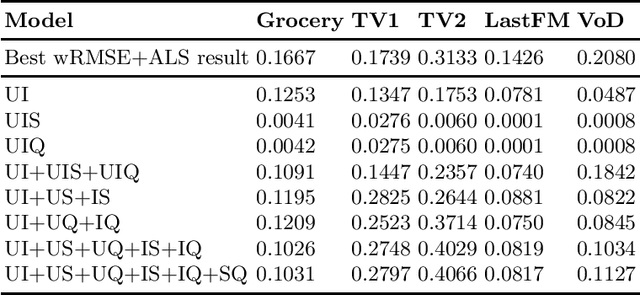
Albeit the implicit feedback based recommendation problem - when only the user history is available but there are no ratings - is the most typical setting in real-world applications, it is much less researched than the explicit feedback case. State-of-the-art algorithms that are efficient on the explicit case cannot be automatically transformed to the implicit case if scalability should be maintained. There are few implicit feedback benchmark data sets, therefore new ideas are usually experimented on explicit benchmarks. In this paper, we propose a generic context-aware implicit feedback recommender algorithm, coined iTALS. iTALS applies a fast, ALS-based tensor factorization learning method that scales linearly with the number of non-zero elements in the tensor. We also present two approximate and faster variants of iTALS using coordinate descent and conjugate gradient methods at learning. The method also allows us to incorporate various contextual information into the model while maintaining its computational efficiency. We present two context-aware variants of iTALS incorporating seasonality and item purchase sequentiality into the model to distinguish user behavior at different time intervals, and product types with different repetitiveness. Experiments run on six data sets shows that iTALS clearly outperforms context-unaware models and context aware baselines, while it is on par with factorization machines (beats 7 times out of 12 cases) both in terms of recall and MAP.
Fast ALS-based tensor factorization for context-aware recommendation from implicit feedback
Apr 04, 2013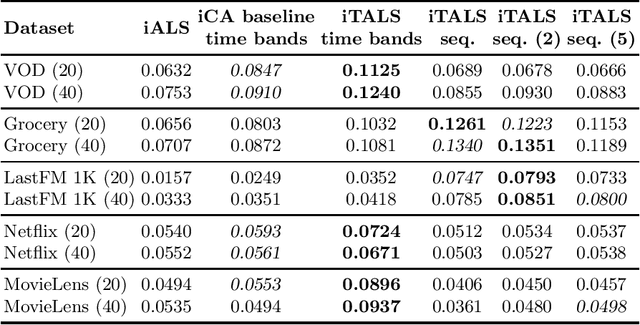
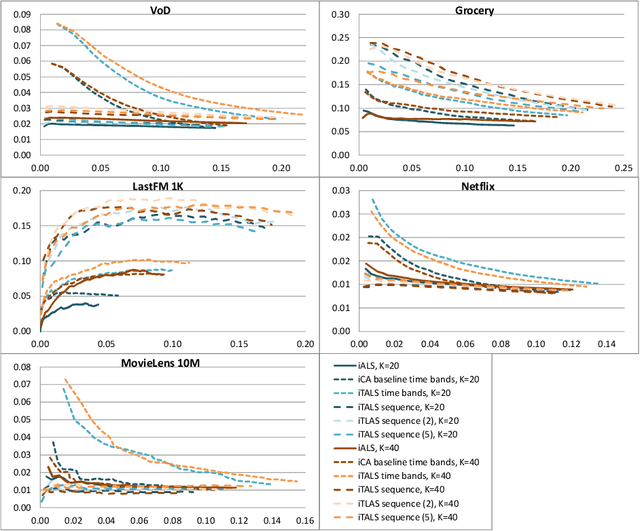
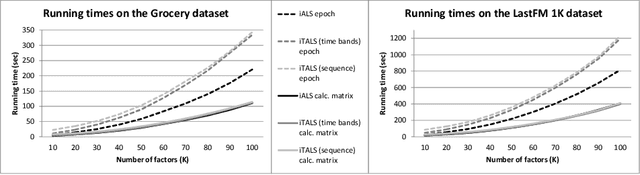
Albeit, the implicit feedback based recommendation problem - when only the user history is available but there are no ratings - is the most typical setting in real-world applications, it is much less researched than the explicit feedback case. State-of-the-art algorithms that are efficient on the explicit case cannot be straightforwardly transformed to the implicit case if scalability should be maintained. There are few if any implicit feedback benchmark datasets, therefore new ideas are usually experimented on explicit benchmarks. In this paper, we propose a generic context-aware implicit feedback recommender algorithm, coined iTALS. iTALS apply a fast, ALS-based tensor factorization learning method that scales linearly with the number of non-zero elements in the tensor. The method also allows us to incorporate diverse context information into the model while maintaining its computational efficiency. In particular, we present two such context-aware implementation variants of iTALS. The first incorporates seasonality and enables to distinguish user behavior in different time intervals. The other views the user history as sequential information and has the ability to recognize usage pattern typical to certain group of items, e.g. to automatically tell apart product types or categories that are typically purchased repetitively (collectibles, grocery goods) or once (household appliances). Experiments performed on three implicit datasets (two proprietary ones and an implicit variant of the Netflix dataset) show that by integrating context-aware information with our factorization framework into the state-of-the-art implicit recommender algorithm the recommendation quality improves significantly.
* Accepted for ECML/PKDD 2012, presented on 25th September 2012, Bristol, UK