 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLabel Refinement Network from Synthetic Error Augmentation for Medical Image Segmentation
Sep 14, 2022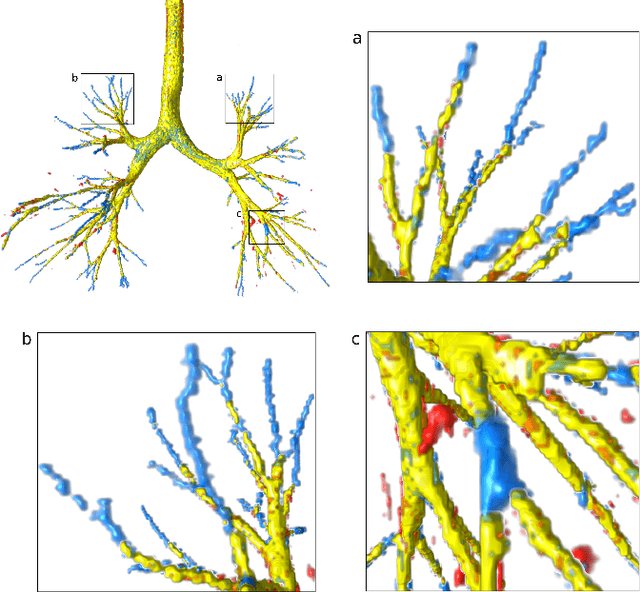
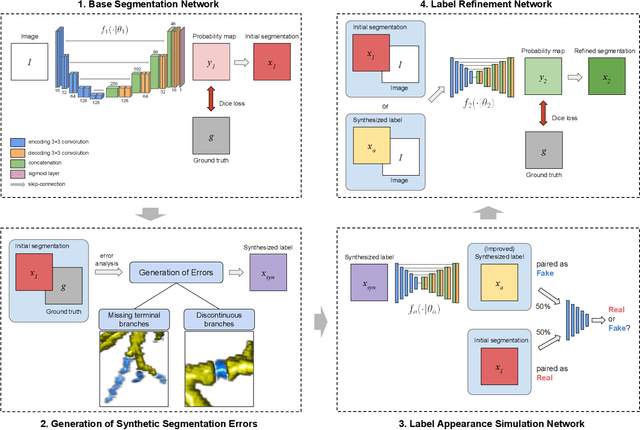
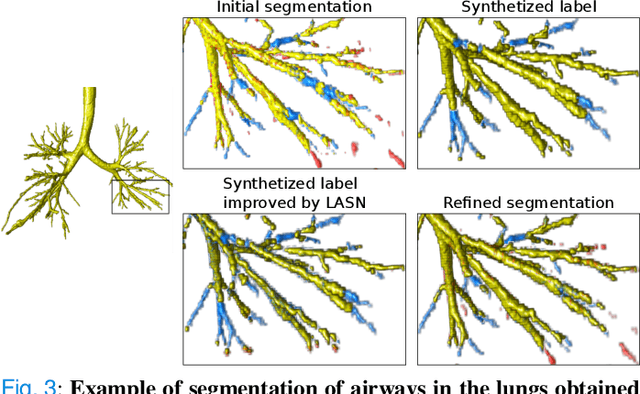
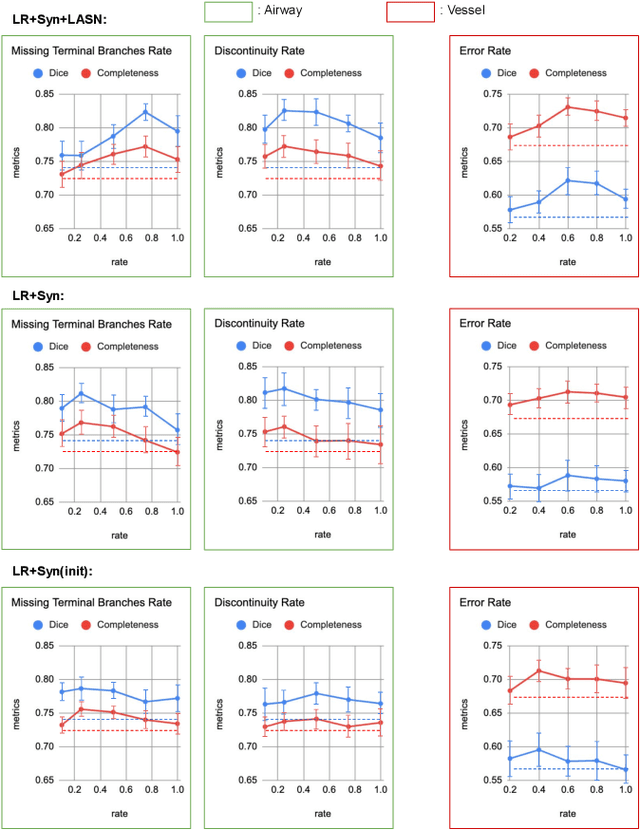
Deep convolutional neural networks for image segmentation do not learn the label structure explicitly and may produce segmentations with an incorrect structure, e.g., with disconnected cylindrical structures in the segmentation of tree-like structures such as airways or blood vessels. In this paper, we propose a novel label refinement method to correct such errors from an initial segmentation, implicitly incorporating information about label structure. This method features two novel parts: 1) a model that generates synthetic structural errors, and 2) a label appearance simulation network that produces synthetic segmentations (with errors) that are similar in appearance to the real initial segmentations. Using these synthetic segmentations and the original images, the label refinement network is trained to correct errors and improve the initial segmentations. The proposed method is validated on two segmentation tasks: airway segmentation from chest computed tomography (CT) scans and brain vessel segmentation from 3D CT angiography (CTA) images of the brain. In both applications, our method significantly outperformed a standard 3D U-Net and other previous refinement approaches. Improvements are even larger when additional unlabeled data is used for model training. In an ablation study, we demonstrate the value of the different components of the proposed method.
On the reusability of samples in active learning
Jun 13, 2022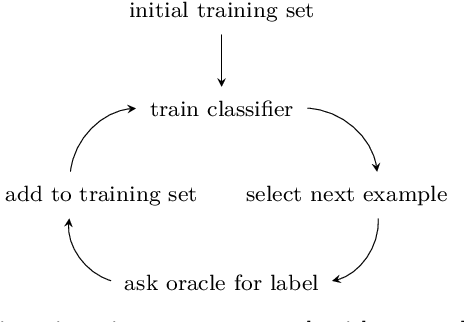
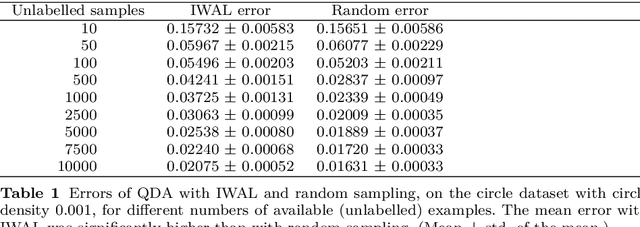
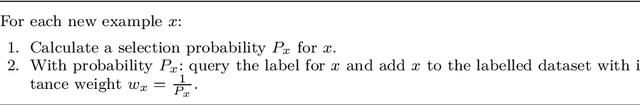
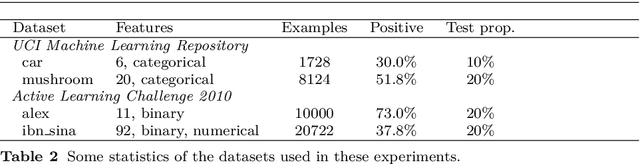
An interesting but not extensively studied question in active learning is that of sample reusability: to what extent can samples selected for one learner be reused by another? This paper explains why sample reusability is of practical interest, why reusability can be a problem, how reusability could be improved by importance-weighted active learning, and which obstacles to universal reusability remain. With theoretical arguments and practical demonstrations, this paper argues that universal reusability is impossible. Because every active learning strategy must undersample some areas of the sample space, learners that depend on the samples in those areas will learn more from a random sample selection. This paper describes several experiments with importance-weighted active learning that show the impact of the reusability problem in practice. The experiments confirmed that universal reusability does not exist, although in some cases -- on some datasets and with some pairs of classifiers -- there is sample reusability. Finally, this paper explores the conditions that could guarantee the reusability between two classifiers.
Automated Segmentation and Volume Measurement of Intracranial Carotid Artery Calcification on Non-Contrast CT
Jul 20, 2021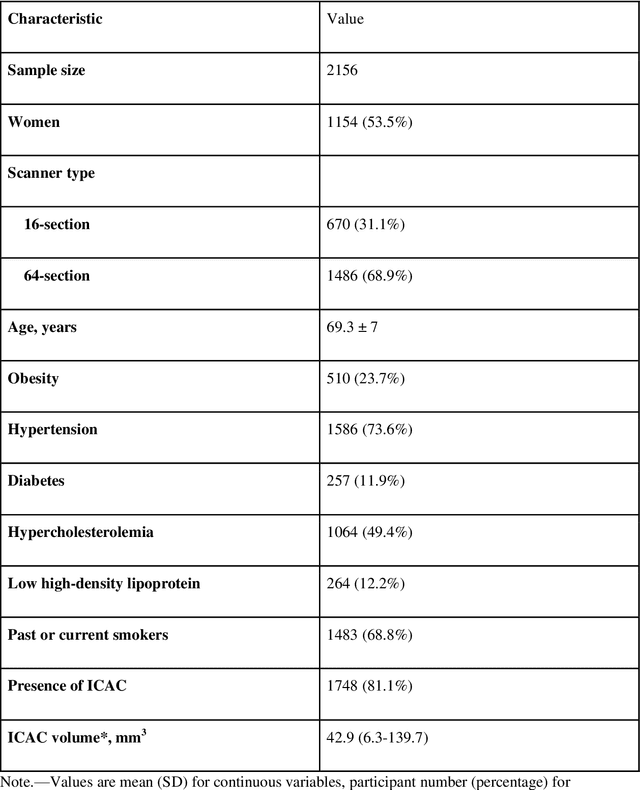
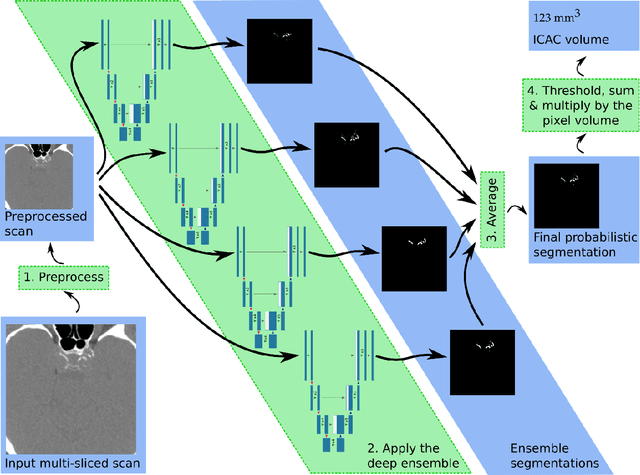
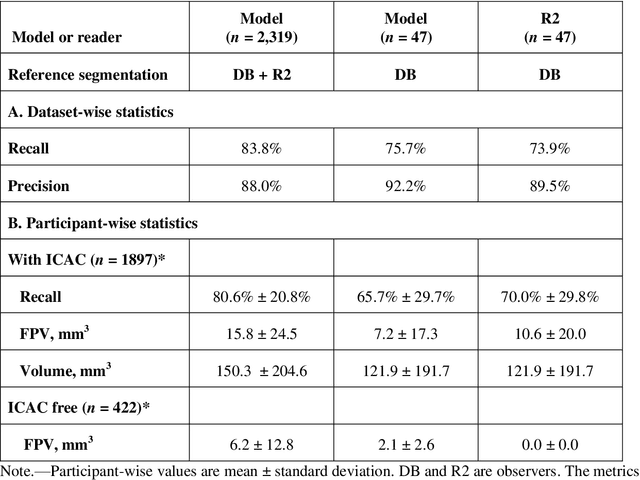
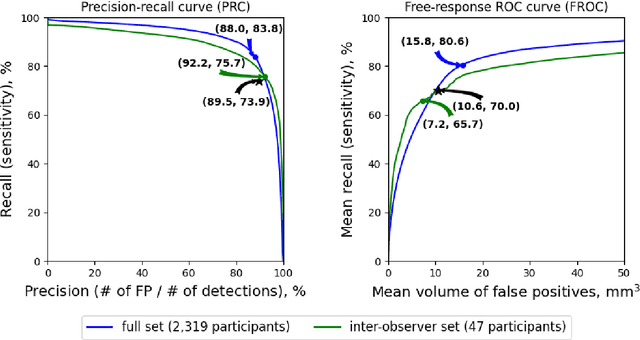
Purpose: To evaluate a fully-automated deep-learning-based method for assessment of intracranial carotid artery calcification (ICAC). Methods: Two observers manually delineated ICAC in non-contrast CT scans of 2,319 participants (mean age 69 (SD 7) years; 1154 women) of the Rotterdam Study, prospectively collected between 2003 and 2006. These data were used to retrospectively develop and validate a deep-learning-based method for automated ICAC delineation and volume measurement. To evaluate the method, we compared manual and automatic assessment (computed using ten-fold cross-validation) with respect to 1) the agreement with an independent observer's assessment (available in a random subset of 47 scans); 2) the accuracy in delineating ICAC as judged via blinded visual comparison by an expert; 3) the association with first stroke incidence from the scan date until 2012. All method performance metrics were computed using 10-fold cross-validation. Results: The automated delineation of ICAC reached sensitivity of 83.8% and positive predictive value (PPV) of 88%. The intraclass correlation between automatic and manual ICAC volume measures was 0.98 (95% CI: 0.97, 0.98; computed in the entire dataset). Measured between the assessments of independent observers, sensitivity was 73.9%, PPV was 89.5%, and intraclass correlation was 0.91 (95% CI: 0.84, 0.95; computed in the 47-scan subset). In the blinded visual comparisons, automatic delineations were more accurate than manual ones (p-value = 0.01). The association of ICAC volume with incident stroke was similarly strong for both automated (hazard ratio, 1.38 (95% CI: 1.12, 1.75) and manually measured volumes (hazard ratio, 1.48 (95% CI: 1.20, 1.87)). Conclusions: The developed model was capable of automated segmentation and volume quantification of ICAC with accuracy comparable to human experts.
Multi-view analysis of unregistered medical images using cross-view transformers
Mar 21, 2021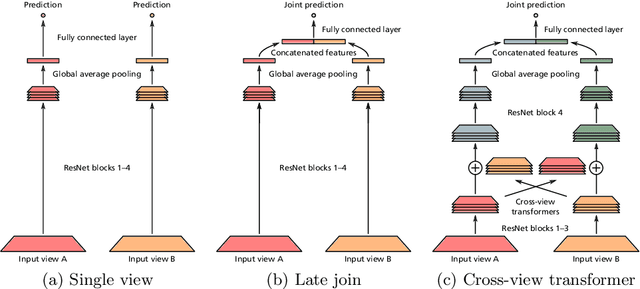

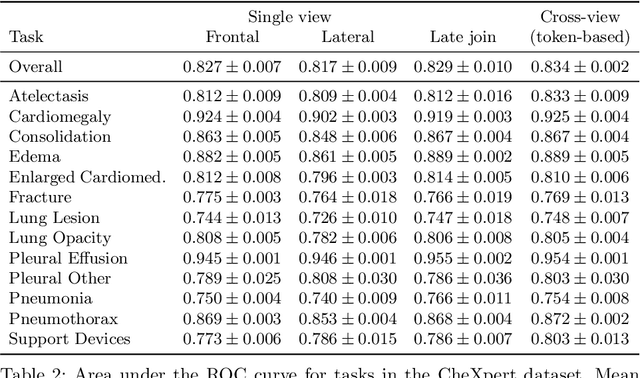
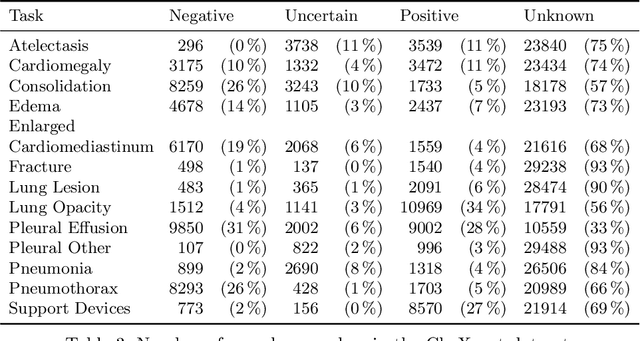
Multi-view medical image analysis often depends on the combination of information from multiple views. However, differences in perspective or other forms of misalignment can make it difficult to combine views effectively, as registration is not always possible. Without registration, views can only be combined at a global feature level, by joining feature vectors after global pooling. We present a novel cross-view transformer method to transfer information between unregistered views at the level of spatial feature maps. We demonstrate this method on multi-view mammography and chest X-ray datasets. On both datasets, we find that a cross-view transformer that links spatial feature maps can outperform a baseline model that joins feature vectors after global pooling.
Multi-Task Attention-Based Semi-Supervised Learning for Medical Image Segmentation
Jul 29, 2019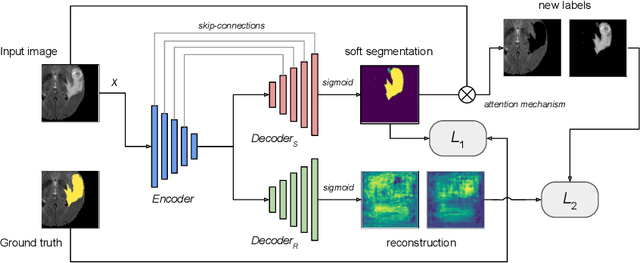
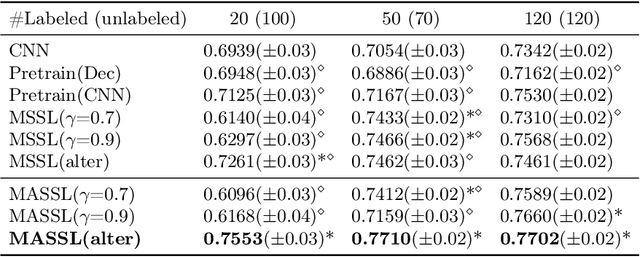
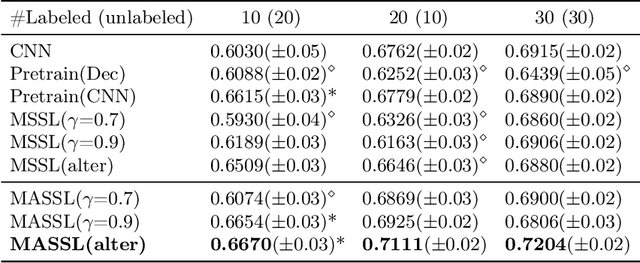
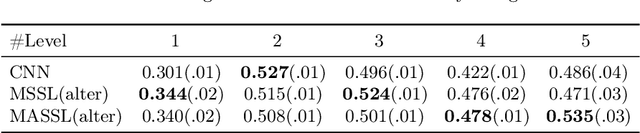
We propose a novel semi-supervised image segmentation method that simultaneously optimizes a supervised segmentation and an unsupervised reconstruction objectives. The reconstruction objective uses an attention mechanism that separates the reconstruction of image areas corresponding to different classes. The proposed approach was evaluated on two applications: brain tumor and white matter hyperintensities segmentation. Our method, trained on unlabeled and a small number of labeled images, outperformed supervised CNNs trained with the same number of images and CNNs pre-trained on unlabeled data. In ablation experiments, we observed that the proposed attention mechanism substantially improves segmentation performance. We explore two multi-task training strategies: joint training and alternating training. Alternating training requires fewer hyperparameters and achieves a better, more stable performance than joint training. Finally, we analyze the features learned by different methods and find that the attention mechanism helps to learn more discriminative features in the deeper layers of encoders.
Weakly Supervised Object Detection with 2D and 3D Regression Neural Networks
Jun 14, 2019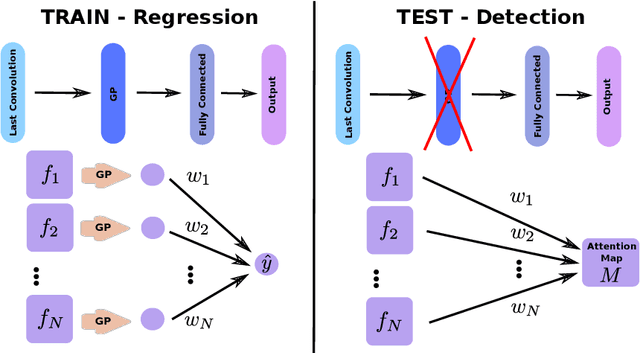

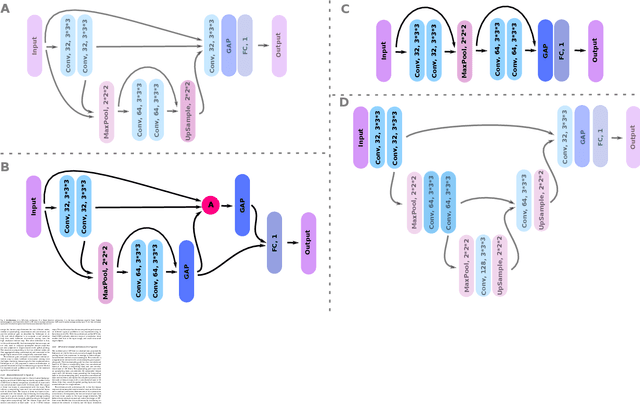

Weakly supervised detection methods can infer the location of target objects in an image without requiring location or appearance information during training. We propose a weakly supervised deep learning method for the detection of objects that appear at multiple locations in an image. The method computes attention maps using the last feature maps of an encoder-decoder network optimized only with global labels: the number of occurrences of the target object in an image. In contrast with previous approaches, attention maps are generated at full input resolution thanks to the decoder part. The proposed approach is compared to multiple state-of-the-art methods in two tasks: the detection of digits in MNIST-based datasets, and the real life application of detection of enlarged perivascular spaces -- a type of brain lesion -- in four brain regions in a dataset of 2202 3D brain MRI scans. In MNIST-based datasets, the proposed method outperforms the other methods. In the brain dataset, several weakly supervised detection methods come close to the human intrarater agreement in each region. The proposed method reaches the lowest number of false positive detections in all brain regions at the operating point, while its average sensitivity is similar to that of the other best methods.
Segmentation of Intracranial Arterial Calcification with Deeply Supervised Residual Dropout Networks
Jun 04, 2017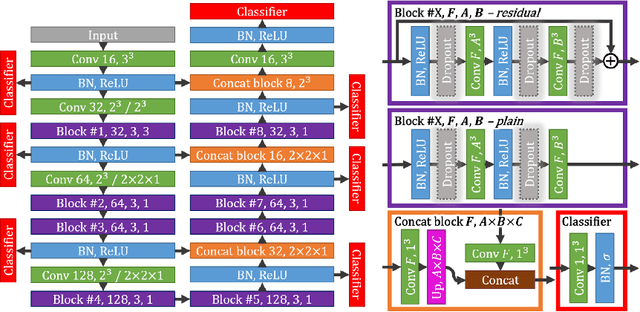
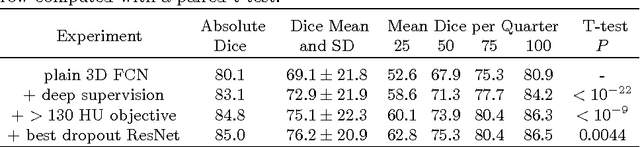
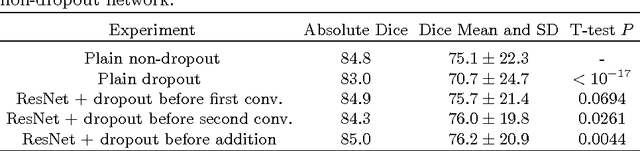
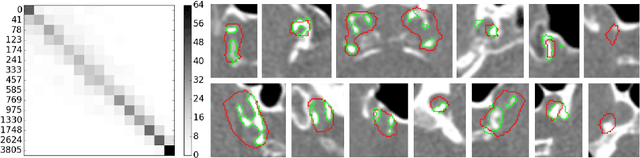
Intracranial carotid artery calcification (ICAC) is a major risk factor for stroke, and might contribute to dementia and cognitive decline. Reliance on time-consuming manual annotation of ICAC hampers much demanded further research into the relationship between ICAC and neurological diseases. Automation of ICAC segmentation is therefore highly desirable, but difficult due to the proximity of the lesions to bony structures with a similar attenuation coefficient. In this paper, we propose a method for automatic segmentation of ICAC; the first to our knowledge. Our method is based on a 3D fully convolutional neural network that we extend with two regularization techniques. Firstly, we use deep supervision (hidden layers supervision) to encourage discriminative features in the hidden layers. Secondly, we augment the network with skip connections, as in the recently developed ResNet, and dropout layers, inserted in a way that skip connections circumvent them. We investigate the effect of skip connections and dropout. In addition, we propose a simple problem-specific modification of the network objective function that restricts the focus to the most important image regions and simplifies the optimization. We train and validate our model using 882 CT scans and test on 1,000. Our regularization techniques and objective improve the average Dice score by 7.1%, yielding an average Dice of 76.2% and 97.7% correlation between predicted ICAC volumes and manual annotations.
Theano: A Python framework for fast computation of mathematical expressions
May 09, 2016



Theano is a Python library that allows to define, optimize, and evaluate mathematical expressions involving multi-dimensional arrays efficiently. Since its introduction, it has been one of the most used CPU and GPU mathematical compilers - especially in the machine learning community - and has shown steady performance improvements. Theano is being actively and continuously developed since 2008, multiple frameworks have been built on top of it and it has been used to produce many state-of-the-art machine learning models. The present article is structured as follows. Section I provides an overview of the Theano software and its community. Section II presents the principal features of Theano and how to use them, and compares them with other similar projects. Section III focuses on recently-introduced functionalities and improvements. Section IV compares the performance of Theano against Torch7 and TensorFlow on several machine learning models. Section V discusses current limitations of Theano and potential ways of improving it.