 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFairness-Aware Structured Pruning in Transformers
Dec 24, 2023The increasing size of large language models (LLMs) has introduced challenges in their training and inference. Removing model components is perceived as a solution to tackle the large model sizes, however, existing pruning methods solely focus on performance, without considering an essential aspect for the responsible use of LLMs: model fairness. It is crucial to address the fairness of LLMs towards diverse groups, such as women, Black people, LGBTQ+, Jewish communities, among others, as they are being deployed and available to a wide audience. In this work, first, we investigate how attention heads impact fairness and performance in pre-trained transformer-based language models. We then propose a novel method to prune the attention heads that negatively impact fairness while retaining the heads critical for performance, i.e. language modeling capabilities. Our approach is practical in terms of time and resources, as it does not require fine-tuning the final pruned, and fairer, model. Our findings demonstrate a reduction in gender bias by 19%, 19.5%, 39.5%, 34.7%, 23%, and 8% for DistilGPT-2, GPT-2, GPT-Neo of two different sizes, GPT-J, and Llama 2 models, respectively, in comparison to the biased model, with only a slight decrease in performance.
Successor Features for Efficient Multisubject Controlled Text Generation
Nov 03, 2023



While large language models (LLMs) have achieved impressive performance in generating fluent and realistic text, controlling the generated text so that it exhibits properties such as safety, factuality, and non-toxicity remains challenging. % such as DExperts, GeDi, and rectification Existing decoding-based methods are static in terms of the dimension of control; if the target subject is changed, they require new training. Moreover, it can quickly become prohibitive to concurrently control multiple subjects. In this work, we introduce SF-GEN, which is grounded in two primary concepts: successor features (SFs) to decouple the LLM's dynamics from task-specific rewards, and language model rectification to proportionally adjust the probability of selecting a token based on the likelihood that the finished text becomes undesired. SF-GEN seamlessly integrates the two to enable dynamic steering of text generation with no need to alter the LLM's parameters. Thanks to the decoupling effect induced by successor features, our method proves to be memory-wise and computationally efficient for training as well as decoding, especially when dealing with multiple target subjects. To the best of our knowledge, our research represents the first application of successor features in text generation. In addition to its computational efficiency, the resultant language produced by our method is comparable to the SOTA (and outperforms baselines) in both control measures as well as language quality, which we demonstrate through a series of experiments in various controllable text generation tasks.
Should We Attend More or Less? Modulating Attention for Fairness
May 22, 2023



The abundance of annotated data in natural language processing (NLP) poses both opportunities and challenges. While it enables the development of high-performing models for a variety of tasks, it also poses the risk of models learning harmful biases from the data, such as gender stereotypes. In this work, we investigate the role of attention, a widely-used technique in current state-of-the-art NLP models, in the propagation of social biases. Specifically, we study the relationship between the entropy of the attention distribution and the model's performance and fairness. We then propose a novel method for modulating attention weights to improve model fairness after training. Since our method is only applied post-training and pre-inference, it is an intra-processing method and is, therefore, less computationally expensive than existing in-processing and pre-processing approaches. Our results show an increase in fairness and minimal performance loss on different text classification and generation tasks using language models of varying sizes. WARNING: This work uses language that is offensive.
Systematic Rectification of Language Models via Dead-end Analysis
Feb 27, 2023



With adversarial or otherwise normal prompts, existing large language models (LLM) can be pushed to generate toxic discourses. One way to reduce the risk of LLMs generating undesired discourses is to alter the training of the LLM. This can be very restrictive due to demanding computation requirements. Other methods rely on rule-based or prompt-based token elimination, which are limited as they dismiss future tokens and the overall meaning of the complete discourse. Here, we center detoxification on the probability that the finished discourse is ultimately considered toxic. That is, at each point, we advise against token selections proportional to how likely a finished text from this point will be toxic. To this end, we formally extend the dead-end theory from the recent reinforcement learning (RL) literature to also cover uncertain outcomes. Our approach, called rectification, utilizes a separate but significantly smaller model for detoxification, which can be applied to diverse LLMs as long as they share the same vocabulary. Importantly, our method does not require access to the internal representations of the LLM, but only the token probability distribution at each decoding step. This is crucial as many LLMs today are hosted in servers and only accessible through APIs. When applied to various LLMs, including GPT-3, our approach significantly improves the generated discourse compared to the base LLMs and other techniques in terms of both the overall language and detoxification performance.
* The Eleventh International Conference on Learning Representations, ICLR'23
Deep Learning on a Healthy Data Diet: Finding Important Examples for Fairness
Nov 25, 2022



Data-driven predictive solutions predominant in commercial applications tend to suffer from biases and stereotypes, which raises equity concerns. Prediction models may discover, use, or amplify spurious correlations based on gender or other protected personal characteristics, thus discriminating against marginalized groups. Mitigating gender bias has become an important research focus in natural language processing (NLP) and is an area where annotated corpora are available. Data augmentation reduces gender bias by adding counterfactual examples to the training dataset. In this work, we show that some of the examples in the augmented dataset can be not important or even harmful for fairness. We hence propose a general method for pruning both the factual and counterfactual examples to maximize the model's fairness as measured by the demographic parity, equality of opportunity, and equality of odds. The fairness achieved by our method surpasses that of data augmentation on three text classification datasets, using no more than half of the examples in the augmented dataset. Our experiments are conducted using models of varying sizes and pre-training settings.
Learning to Limit Data Collection via Scaling Laws: Data Minimization Compliance in Practice
Jul 16, 2021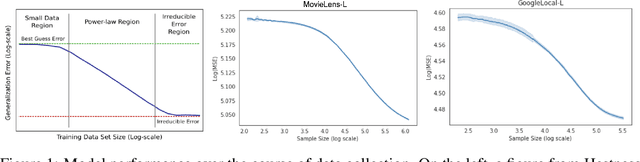
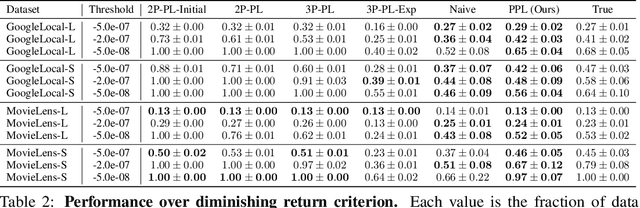
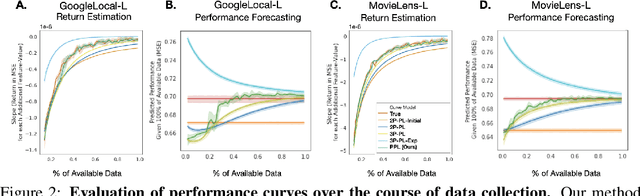
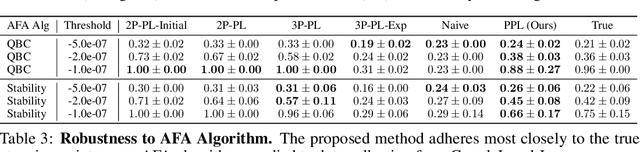
Data minimization is a legal obligation defined in the European Union's General Data Protection Regulation (GDPR) as the responsibility to process an adequate, relevant, and limited amount of personal data in relation to a processing purpose. However, unlike fairness or transparency, the principle has not seen wide adoption for machine learning systems due to a lack of computational interpretation. In this paper, we build on literature in machine learning and law to propose the first learning framework for limiting data collection based on an interpretation that ties the data collection purpose to system performance. We formalize a data minimization criterion based on performance curve derivatives and provide an effective and interpretable piecewise power law technique that models distinct stages of an algorithm's performance throughout data collection. Results from our empirical investigation offer deeper insights into the relevant considerations when designing a data minimization framework, including the choice of feature acquisition algorithm, initialization conditions, as well as impacts on individuals that hint at tensions between data minimization and fairness.
On the Learning Dynamics of Deep Neural Networks
Sep 18, 2018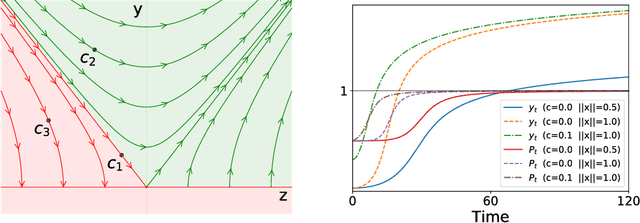
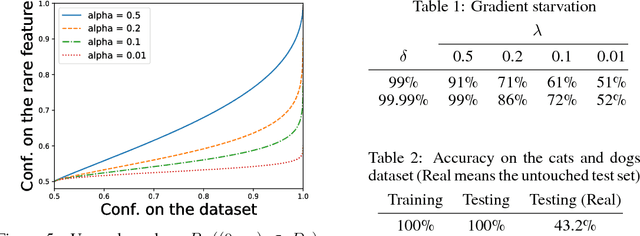
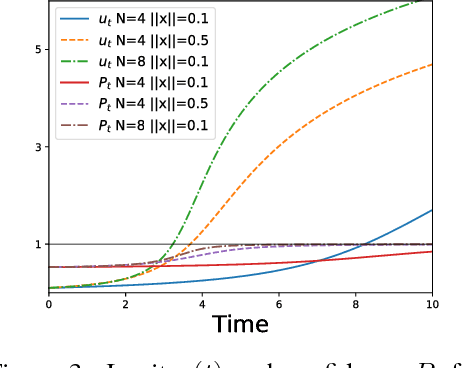
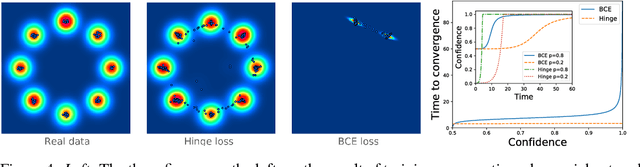
While a lot of progress has been made in recent years, the dynamics of learning in deep nonlinear neural networks remain to this day largely misunderstood. In this work, we study the case of binary classification and prove various properties of learning in such networks under strong assumptions such as linear separability of the data. Extending existing results from the linear case, we confirm empirical observations by proving that the classification error also follows a sigmoidal shape in nonlinear architectures. We show that given proper initialization, learning expounds parallel independent modes and that certain regions of parameter space might lead to failed training. We also demonstrate that input norm and features' frequency in the dataset lead to distinct convergence speeds which might shed some light on the generalization capabilities of deep neural networks. We provide a comparison between the dynamics of learning with cross-entropy and hinge losses, which could prove useful to understand recent progress in the training of generative adversarial networks. Finally, we identify a phenomenon that we baptize gradient starvation where the most frequent features in a dataset prevent the learning of other less frequent but equally informative features.
Variational Bi-LSTMs
Nov 15, 2017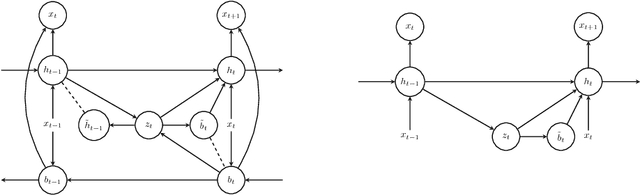
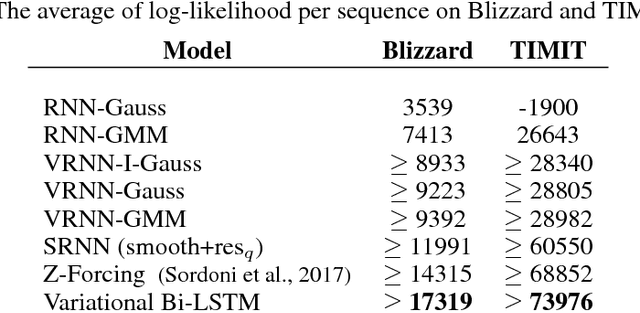
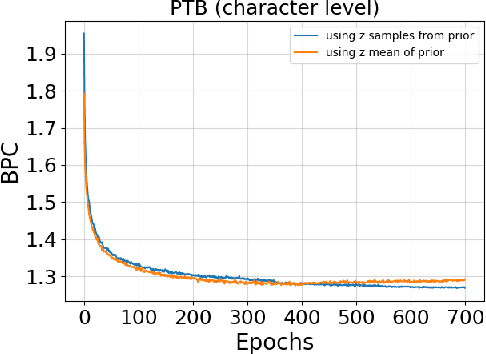
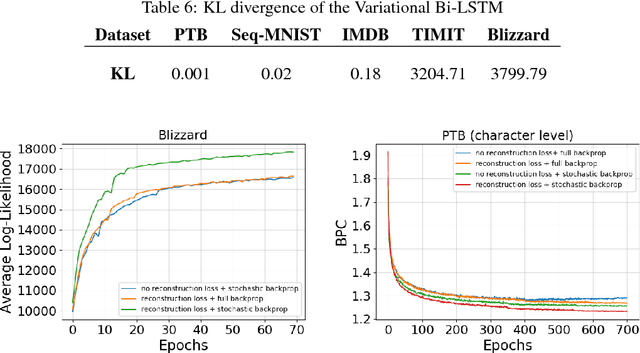
Recurrent neural networks like long short-term memory (LSTM) are important architectures for sequential prediction tasks. LSTMs (and RNNs in general) model sequences along the forward time direction. Bidirectional LSTMs (Bi-LSTMs) on the other hand model sequences along both forward and backward directions and are generally known to perform better at such tasks because they capture a richer representation of the data. In the training of Bi-LSTMs, the forward and backward paths are learned independently. We propose a variant of the Bi-LSTM architecture, which we call Variational Bi-LSTM, that creates a channel between the two paths (during training, but which may be omitted during inference); thus optimizing the two paths jointly. We arrive at this joint objective for our model by minimizing a variational lower bound of the joint likelihood of the data sequence. Our model acts as a regularizer and encourages the two networks to inform each other in making their respective predictions using distinct information. We perform ablation studies to better understand the different components of our model and evaluate the method on various benchmarks, showing state-of-the-art performance.
Bidirectional Helmholtz Machines
May 25, 2016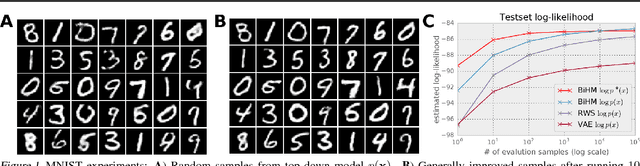
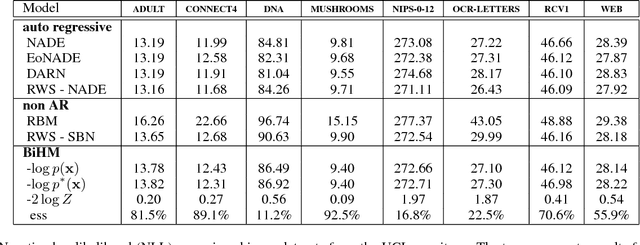
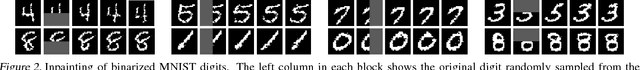

Efficient unsupervised training and inference in deep generative models remains a challenging problem. One basic approach, called Helmholtz machine, involves training a top-down directed generative model together with a bottom-up auxiliary model used for approximate inference. Recent results indicate that better generative models can be obtained with better approximate inference procedures. Instead of improving the inference procedure, we here propose a new model which guarantees that the top-down and bottom-up distributions can efficiently invert each other. We achieve this by interpreting both the top-down and the bottom-up directed models as approximate inference distributions and by defining the model distribution to be the geometric mean of these two. We present a lower-bound for the likelihood of this model and we show that optimizing this bound regularizes the model so that the Bhattacharyya distance between the bottom-up and top-down approximate distributions is minimized. This approach results in state of the art generative models which prefer significantly deeper architectures while it allows for orders of magnitude more efficient approximate inference.
Theano: A Python framework for fast computation of mathematical expressions
May 09, 2016



Theano is a Python library that allows to define, optimize, and evaluate mathematical expressions involving multi-dimensional arrays efficiently. Since its introduction, it has been one of the most used CPU and GPU mathematical compilers - especially in the machine learning community - and has shown steady performance improvements. Theano is being actively and continuously developed since 2008, multiple frameworks have been built on top of it and it has been used to produce many state-of-the-art machine learning models. The present article is structured as follows. Section I provides an overview of the Theano software and its community. Section II presents the principal features of Theano and how to use them, and compares them with other similar projects. Section III focuses on recently-introduced functionalities and improvements. Section IV compares the performance of Theano against Torch7 and TensorFlow on several machine learning models. Section V discusses current limitations of Theano and potential ways of improving it.