 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommunity Moderation and the New Epistemology of Fact Checking on Social Media
May 26, 2025Social media platforms have traditionally relied on internal moderation teams and partnerships with independent fact-checking organizations to identify and flag misleading content. Recently, however, platforms including X (formerly Twitter) and Meta have shifted towards community-driven content moderation by launching their own versions of crowd-sourced fact-checking -- Community Notes. If effectively scaled and governed, such crowd-checking initiatives have the potential to combat misinformation with increased scale and speed as successfully as community-driven efforts once did with spam. Nevertheless, general content moderation, especially for misinformation, is inherently more complex. Public perceptions of truth are often shaped by personal biases, political leanings, and cultural contexts, complicating consensus on what constitutes misleading content. This suggests that community efforts, while valuable, cannot replace the indispensable role of professional fact-checkers. Here we systemically examine the current approaches to misinformation detection across major platforms, explore the emerging role of community-driven moderation, and critically evaluate both the promises and challenges of crowd-checking at scale.
ModelingAgent: Bridging LLMs and Mathematical Modeling for Real-World Challenges
May 21, 2025



Recent progress in large language models (LLMs) has enabled substantial advances in solving mathematical problems. However, existing benchmarks often fail to reflect the complexity of real-world problems, which demand open-ended, interdisciplinary reasoning and integration of computational tools. To address this gap, we introduce ModelingBench, a novel benchmark featuring real-world-inspired, open-ended problems from math modeling competitions across diverse domains, ranging from urban traffic optimization to ecosystem resource planning. These tasks require translating natural language into formal mathematical formulations, applying appropriate tools, and producing structured, defensible reports. ModelingBench also supports multiple valid solutions, capturing the ambiguity and creativity of practical modeling. We also present ModelingAgent, a multi-agent framework that coordinates tool use, supports structured workflows, and enables iterative self-refinement to generate well-grounded, creative solutions. To evaluate outputs, we further propose ModelingJudge, an expert-in-the-loop system leveraging LLMs as domain-specialized judges assessing solutions from multiple expert perspectives. Empirical results show that ModelingAgent substantially outperforms strong baselines and often produces solutions indistinguishable from those of human experts. Together, our work provides a comprehensive framework for evaluating and advancing real-world problem-solving in open-ended, interdisciplinary modeling challenges.
mCLM: A Function-Infused and Synthesis-Friendly Modular Chemical Language Model
May 18, 2025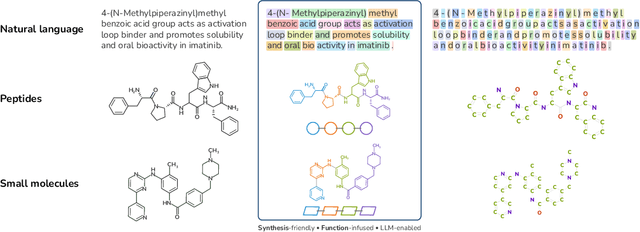
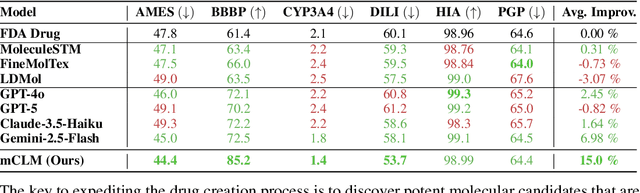
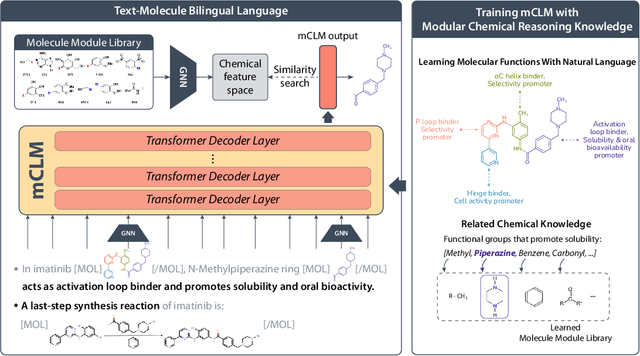
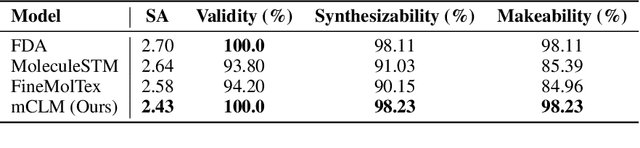
Despite their ability to understand chemical knowledge and accurately generate sequential representations, large language models (LLMs) remain limited in their capacity to propose novel molecules with drug-like properties. In addition, the molecules that LLMs propose can often be challenging to make in the lab. To more effectively enable the discovery of functional small molecules, LLMs need to learn a molecular language. However, LLMs are currently limited by encoding molecules from atoms. In this paper, we argue that just like tokenizing texts into (sub-)word tokens instead of characters, molecules should be decomposed and reassembled at the level of functional building blocks, i.e., parts of molecules that bring unique functions and serve as effective building blocks for real-world automated laboratory synthesis. This motivates us to propose mCLM, a modular Chemical-Language Model tokenizing molecules into building blocks and learning a bilingual language model of both natural language descriptions of functions and molecule building blocks. By reasoning on such functional building blocks, mCLM guarantees to generate efficiently synthesizable molecules thanks to recent progress in block-based chemistry, while also improving the functions of molecules in a principled manner. In experiments on 430 FDA-approved drugs, we find mCLM capable of significantly improving 5 out of 6 chemical functions critical to determining drug potentials. More importantly, mCLM can reason on multiple functions and improve the FDA-rejected drugs (``fallen angels'') over multiple iterations to greatly improve their shortcomings.
Prioritizing Image-Related Tokens Enhances Vision-Language Pre-Training
May 13, 2025In standard large vision-language models (LVLMs) pre-training, the model typically maximizes the joint probability of the caption conditioned on the image via next-token prediction (NTP); however, since only a small subset of caption tokens directly relates to the visual content, this naive NTP unintentionally fits the model to noise and increases the risk of hallucination. We present PRIOR, a simple vision-language pre-training approach that addresses this issue by prioritizing image-related tokens through differential weighting in the NTP loss, drawing from the importance sampling framework. PRIOR introduces a reference model-a text-only large language model (LLM) trained on the captions without image inputs, to weight each token based on its probability for LVLMs training. Intuitively, tokens that are directly related to the visual inputs are harder to predict without the image and thus receive lower probabilities from the text-only reference LLM. During training, we implement a token-specific re-weighting term based on the importance scores to adjust each token's loss. We implement PRIOR in two distinct settings: LVLMs with visual encoders and LVLMs without visual encoders. We observe 19% and 8% average relative improvement, respectively, on several vision-language benchmarks compared to NTP. In addition, PRIOR exhibits superior scaling properties, as demonstrated by significantly higher scaling coefficients, indicating greater potential for performance gains compared to NTP given increasing compute and data.
Must Read: A Systematic Survey of Computational Persuasion
May 12, 2025Persuasion is a fundamental aspect of communication, influencing decision-making across diverse contexts, from everyday conversations to high-stakes scenarios such as politics, marketing, and law. The rise of conversational AI systems has significantly expanded the scope of persuasion, introducing both opportunities and risks. AI-driven persuasion can be leveraged for beneficial applications, but also poses threats through manipulation and unethical influence. Moreover, AI systems are not only persuaders, but also susceptible to persuasion, making them vulnerable to adversarial attacks and bias reinforcement. Despite rapid advancements in AI-generated persuasive content, our understanding of what makes persuasion effective remains limited due to its inherently subjective and context-dependent nature. In this survey, we provide a comprehensive overview of computational persuasion, structured around three key perspectives: (1) AI as a Persuader, which explores AI-generated persuasive content and its applications; (2) AI as a Persuadee, which examines AI's susceptibility to influence and manipulation; and (3) AI as a Persuasion Judge, which analyzes AI's role in evaluating persuasive strategies, detecting manipulation, and ensuring ethical persuasion. We introduce a taxonomy for computational persuasion research and discuss key challenges, including evaluating persuasiveness, mitigating manipulative persuasion, and developing responsible AI-driven persuasive systems. Our survey outlines future research directions to enhance the safety, fairness, and effectiveness of AI-powered persuasion while addressing the risks posed by increasingly capable language models.
Seed1.5-VL Technical Report
May 11, 2025



We present Seed1.5-VL, a vision-language foundation model designed to advance general-purpose multimodal understanding and reasoning. Seed1.5-VL is composed with a 532M-parameter vision encoder and a Mixture-of-Experts (MoE) LLM of 20B active parameters. Despite its relatively compact architecture, it delivers strong performance across a wide spectrum of public VLM benchmarks and internal evaluation suites, achieving the state-of-the-art performance on 38 out of 60 public benchmarks. Moreover, in agent-centric tasks such as GUI control and gameplay, Seed1.5-VL outperforms leading multimodal systems, including OpenAI CUA and Claude 3.7. Beyond visual and video understanding, it also demonstrates strong reasoning abilities, making it particularly effective for multimodal reasoning challenges such as visual puzzles. We believe these capabilities will empower broader applications across diverse tasks. In this report, we mainly provide a comprehensive review of our experiences in building Seed1.5-VL across model design, data construction, and training at various stages, hoping that this report can inspire further research. Seed1.5-VL is now accessible at https://www.volcengine.com/ (Volcano Engine Model ID: doubao-1-5-thinking-vision-pro-250428)
SweRank: Software Issue Localization with Code Ranking
May 07, 2025Software issue localization, the task of identifying the precise code locations (files, classes, or functions) relevant to a natural language issue description (e.g., bug report, feature request), is a critical yet time-consuming aspect of software development. While recent LLM-based agentic approaches demonstrate promise, they often incur significant latency and cost due to complex multi-step reasoning and relying on closed-source LLMs. Alternatively, traditional code ranking models, typically optimized for query-to-code or code-to-code retrieval, struggle with the verbose and failure-descriptive nature of issue localization queries. To bridge this gap, we introduce SweRank, an efficient and effective retrieve-and-rerank framework for software issue localization. To facilitate training, we construct SweLoc, a large-scale dataset curated from public GitHub repositories, featuring real-world issue descriptions paired with corresponding code modifications. Empirical results on SWE-Bench-Lite and LocBench show that SweRank achieves state-of-the-art performance, outperforming both prior ranking models and costly agent-based systems using closed-source LLMs like Claude-3.5. Further, we demonstrate SweLoc's utility in enhancing various existing retriever and reranker models for issue localization, establishing the dataset as a valuable resource for the community.
RM-R1: Reward Modeling as Reasoning
May 05, 2025Reward modeling is essential for aligning large language models (LLMs) with human preferences, especially through reinforcement learning from human feedback (RLHF). To provide accurate reward signals, a reward model (RM) should stimulate deep thinking and conduct interpretable reasoning before assigning a score or a judgment. However, existing RMs either produce opaque scalar scores or directly generate the prediction of a preferred answer, making them struggle to integrate natural language critiques, thus lacking interpretability. Inspired by recent advances of long chain-of-thought (CoT) on reasoning-intensive tasks, we hypothesize and validate that integrating reasoning capabilities into reward modeling significantly enhances RM's interpretability and performance. In this work, we introduce a new class of generative reward models -- Reasoning Reward Models (ReasRMs) -- which formulate reward modeling as a reasoning task. We propose a reasoning-oriented training pipeline and train a family of ReasRMs, RM-R1. The training consists of two key stages: (1) distillation of high-quality reasoning chains and (2) reinforcement learning with verifiable rewards. RM-R1 improves LLM rollouts by self-generating reasoning traces or chat-specific rubrics and evaluating candidate responses against them. Empirically, our models achieve state-of-the-art or near state-of-the-art performance of generative RMs across multiple comprehensive reward model benchmarks, outperforming much larger open-weight models (e.g., Llama3.1-405B) and proprietary ones (e.g., GPT-4o) by up to 13.8%. Beyond final performance, we perform thorough empirical analysis to understand the key ingredients of successful ReasRM training. To facilitate future research, we release six ReasRM models along with code and data at https://github.com/RM-R1-UIUC/RM-R1.
Toward Generalizable Evaluation in the LLM Era: A Survey Beyond Benchmarks
Apr 26, 2025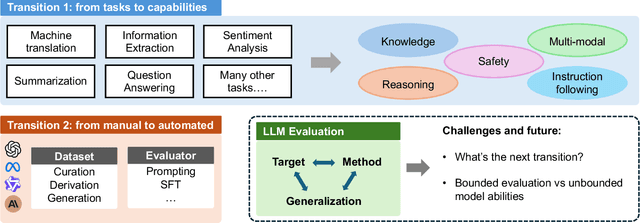
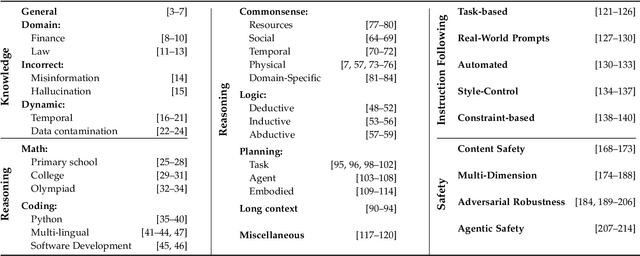
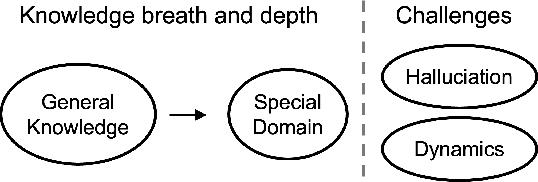
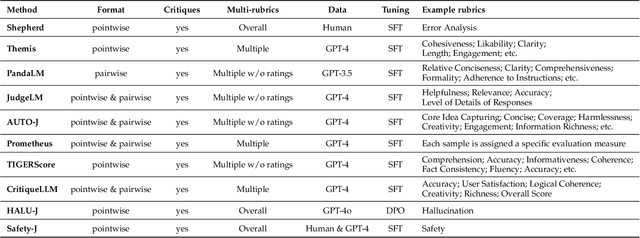
Large Language Models (LLMs) are advancing at an amazing speed and have become indispensable across academia, industry, and daily applications. To keep pace with the status quo, this survey probes the core challenges that the rise of LLMs poses for evaluation. We identify and analyze two pivotal transitions: (i) from task-specific to capability-based evaluation, which reorganizes benchmarks around core competencies such as knowledge, reasoning, instruction following, multi-modal understanding, and safety; and (ii) from manual to automated evaluation, encompassing dynamic dataset curation and "LLM-as-a-judge" scoring. Yet, even with these transitions, a crucial obstacle persists: the evaluation generalization issue. Bounded test sets cannot scale alongside models whose abilities grow seemingly without limit. We will dissect this issue, along with the core challenges of the above two transitions, from the perspectives of methods, datasets, evaluators, and metrics. Due to the fast evolving of this field, we will maintain a living GitHub repository (links are in each section) to crowd-source updates and corrections, and warmly invite contributors and collaborators.
DyMU: Dynamic Merging and Virtual Unmerging for Efficient VLMs
Apr 23, 2025



We present DyMU, an efficient, training-free framework that dynamically reduces the computational burden of vision-language models (VLMs) while maintaining high task performance. Our approach comprises two key components. First, Dynamic Token Merging (DToMe) reduces the number of visual token embeddings by merging similar tokens based on image complexity, addressing the inherent inefficiency of fixed-length outputs in vision transformers. Second, Virtual Token Unmerging (VTU) simulates the expected token sequence for large language models (LLMs) by efficiently reconstructing the attention dynamics of a full sequence, thus preserving the downstream performance without additional fine-tuning. Unlike previous approaches, our method dynamically adapts token compression to the content of the image and operates completely training-free, making it readily applicable to most state-of-the-art VLM architectures. Extensive experiments on image and video understanding tasks demonstrate that DyMU can reduce the average visual token count by 32%-85% while achieving comparable performance to full-length models across diverse VLM architectures, including the recently popularized AnyRes-based visual encoders. Furthermore, through qualitative analyses, we demonstrate that DToMe effectively adapts token reduction based on image complexity and, unlike existing systems, provides users more control over computational costs. Project page: https://mikewangwzhl.github.io/dymu/.