 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFRAbench and GenEval: Scaling Fine-Grained Aspect Evaluation across Tasks, Modalities
May 19, 2025Evaluating the open-ended outputs of large language models (LLMs) has become a bottleneck as model capabilities, task diversity, and modality coverage rapidly expand. Existing "LLM-as-a-Judge" evaluators are typically narrow in a few tasks, aspects, or modalities, and easily suffer from low consistency. In this paper, we argue that explicit, fine-grained aspect specification is the key to both generalizability and objectivity in automated evaluation. To do so, we introduce a hierarchical aspect taxonomy spanning 112 aspects that unifies evaluation across four representative settings - Natural Language Generation, Image Understanding, Image Generation, and Interleaved Text-and-Image Generation. Building on this taxonomy, we create FRAbench, a benchmark comprising 60.4k pairwise samples with 325k aspect-level labels obtained from a combination of human and LLM annotations. FRAbench provides the first large-scale, multi-modal resource for training and meta-evaluating fine-grained LMM judges. Leveraging FRAbench, we develop GenEval, a fine-grained evaluator generalizable across tasks and modalities. Experiments show that GenEval (i) attains high agreement with GPT-4o and expert annotators, (ii) transfers robustly to unseen tasks and modalities, and (iii) reveals systematic weaknesses of current LMMs on evaluation.
Toward Generalizable Evaluation in the LLM Era: A Survey Beyond Benchmarks
Apr 26, 2025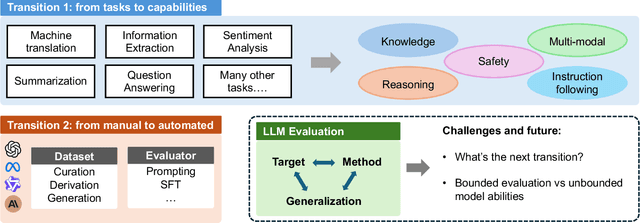
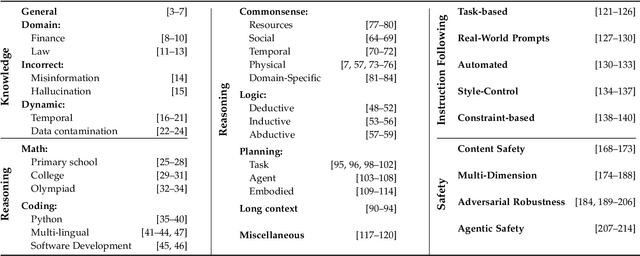
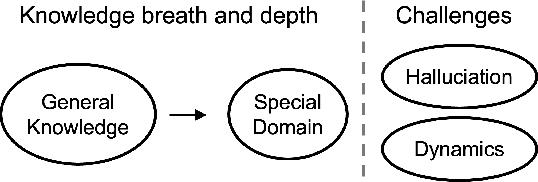
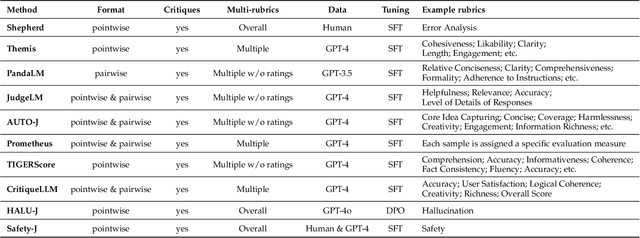
Large Language Models (LLMs) are advancing at an amazing speed and have become indispensable across academia, industry, and daily applications. To keep pace with the status quo, this survey probes the core challenges that the rise of LLMs poses for evaluation. We identify and analyze two pivotal transitions: (i) from task-specific to capability-based evaluation, which reorganizes benchmarks around core competencies such as knowledge, reasoning, instruction following, multi-modal understanding, and safety; and (ii) from manual to automated evaluation, encompassing dynamic dataset curation and "LLM-as-a-judge" scoring. Yet, even with these transitions, a crucial obstacle persists: the evaluation generalization issue. Bounded test sets cannot scale alongside models whose abilities grow seemingly without limit. We will dissect this issue, along with the core challenges of the above two transitions, from the perspectives of methods, datasets, evaluators, and metrics. Due to the fast evolving of this field, we will maintain a living GitHub repository (links are in each section) to crowd-source updates and corrections, and warmly invite contributors and collaborators.