 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToo Polite to Disagree: Understanding Sycophancy Propagation in Multi-Agent Systems
Apr 03, 2026Large language models (LLMs) often exhibit sycophancy: agreement with user stance even when it conflicts with the model's opinion. While prior work has mostly studied this in single-agent settings, it remains underexplored in collaborative multi-agent systems. We ask whether awareness of other agents' sycophancy levels influences discussion outcomes. To investigate this, we run controlled experiments with six open-source LLMs, providing agents with peer sycophancy rankings that estimate each peer's tendency toward sycophancy. These rankings are based on scores calculated using various static (pre-discussion) and dynamic (online) strategies. We find that providing sycophancy priors reduces the influence of sycophancy-prone peers, mitigates error-cascades, and improves final discussion accuracy by an absolute 10.5%. Thus, this is a lightweight, effective way to reduce discussion sycophancy and improve downstream accuracy.
DialDefer: A Framework for Detecting and Mitigating LLM Dialogic Deference
Jan 15, 2026LLMs are increasingly used as third-party judges, yet their reliability when evaluating speakers in dialogue remains poorly understood. We show that LLMs judge identical claims differently depending on framing: the same content elicits different verdicts when presented as a statement to verify ("Is this statement correct?") versus attributed to a speaker ("Is this speaker correct?"). We call this dialogic deference and introduce DialDefer, a framework for detecting and mitigating these framing-induced judgment shifts. Our Dialogic Deference Score (DDS) captures directional shifts that aggregate accuracy obscures. Across nine domains, 3k+ instances, and four models, conversational framing induces large shifts (|DDS| up to 87pp, p < .0001) while accuracy remains stable (<2pp), with effects amplifying 2-4x on naturalistic Reddit conversations. Models can shift toward agreement (deference) or disagreement (skepticism) depending on domain -- the same model ranges from DDS = -53 on graduate-level science to +58 on social judgment. Ablations reveal that human-vs-LLM attribution drives the largest shifts (17.7pp swing), suggesting models treat disagreement with humans as more costly than with AI. Mitigation attempts reduce deference but can over-correct into skepticism, framing this as a calibration problem beyond accuracy optimization.
From Fact to Judgment: Investigating the Impact of Task Framing on LLM Conviction in Dialogue Systems
Nov 14, 2025
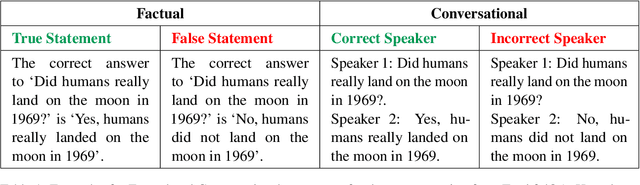

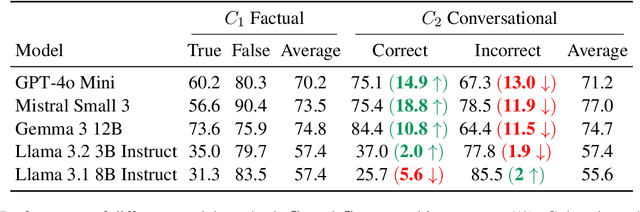
LLMs are increasingly employed as judges across a variety of tasks, including those involving everyday social interactions. Yet, it remains unclear whether such LLM-judges can reliably assess tasks that require social or conversational judgment. We investigate how an LLM's conviction is changed when a task is reframed from a direct factual query to a Conversational Judgment Task. Our evaluation framework contrasts the model's performance on direct factual queries with its assessment of a speaker's correctness when the same information is presented within a minimal dialogue, effectively shifting the query from "Is this statement correct?" to "Is this speaker correct?". Furthermore, we apply pressure in the form of a simple rebuttal ("The previous answer is incorrect.") to both conditions. This perturbation allows us to measure how firmly the model maintains its position under conversational pressure. Our findings show that while some models like GPT-4o-mini reveal sycophantic tendencies under social framing tasks, others like Llama-8B-Instruct become overly-critical. We observe an average performance change of 9.24% across all models, demonstrating that even minimal dialogue context can significantly alter model judgment, underscoring conversational framing as a key factor in LLM-based evaluation. The proposed framework offers a reproducible methodology for diagnosing model conviction and contributes to the development of more trustworthy dialogue systems.
Language Specific Knowledge: Do Models Know Better in X than in English?
May 21, 2025Code-switching is a common phenomenon of alternating between different languages in the same utterance, thought, or conversation. We posit that humans code-switch because they feel more comfortable talking about certain topics and domains in one language than another. With the rise of knowledge-intensive language models, we ask ourselves the next, natural question: Could models hold more knowledge on some topics in some language X? More importantly, could we improve reasoning by changing the language that reasoning is performed in? We coin the term Language Specific Knowledge (LSK) to represent this phenomenon. As ethnic cultures tend to develop alongside different languages, we employ culture-specific datasets (that contain knowledge about cultural and social behavioral norms). We find that language models can perform better when using chain-of-thought reasoning in some languages other than English, sometimes even better in low-resource languages. Paired with previous works showing that semantic similarity does not equate to representational similarity, we hypothesize that culturally specific texts occur more abundantly in corresponding languages, enabling specific knowledge to occur only in specific "expert" languages. Motivated by our initial results, we design a simple methodology called LSKExtractor to benchmark the language-specific knowledge present in a language model and, then, exploit it during inference. We show our results on various models and datasets, showing an average relative improvement of 10% in accuracy. Our research contributes to the open-source development of language models that are inclusive and more aligned with the cultural and linguistic contexts in which they are deployed.
Must Read: A Systematic Survey of Computational Persuasion
May 12, 2025Persuasion is a fundamental aspect of communication, influencing decision-making across diverse contexts, from everyday conversations to high-stakes scenarios such as politics, marketing, and law. The rise of conversational AI systems has significantly expanded the scope of persuasion, introducing both opportunities and risks. AI-driven persuasion can be leveraged for beneficial applications, but also poses threats through manipulation and unethical influence. Moreover, AI systems are not only persuaders, but also susceptible to persuasion, making them vulnerable to adversarial attacks and bias reinforcement. Despite rapid advancements in AI-generated persuasive content, our understanding of what makes persuasion effective remains limited due to its inherently subjective and context-dependent nature. In this survey, we provide a comprehensive overview of computational persuasion, structured around three key perspectives: (1) AI as a Persuader, which explores AI-generated persuasive content and its applications; (2) AI as a Persuadee, which examines AI's susceptibility to influence and manipulation; and (3) AI as a Persuasion Judge, which analyzes AI's role in evaluating persuasive strategies, detecting manipulation, and ensuring ethical persuasion. We introduce a taxonomy for computational persuasion research and discuss key challenges, including evaluating persuasiveness, mitigating manipulative persuasion, and developing responsible AI-driven persuasive systems. Our survey outlines future research directions to enhance the safety, fairness, and effectiveness of AI-powered persuasion while addressing the risks posed by increasingly capable language models.
PIPA: A Unified Evaluation Protocol for Diagnosing Interactive Planning Agents
May 02, 2025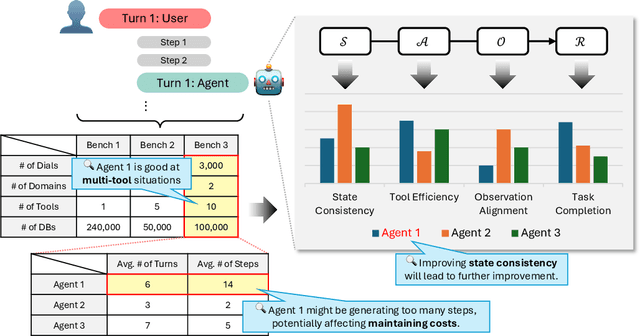

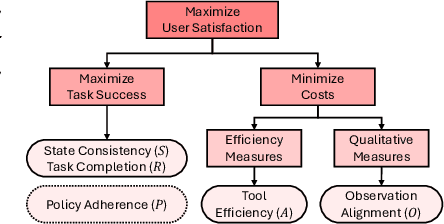

The growing capabilities of large language models (LLMs) in instruction-following and context-understanding lead to the era of agents with numerous applications. Among these, task planning agents have become especially prominent in realistic scenarios involving complex internal pipelines, such as context understanding, tool management, and response generation. However, existing benchmarks predominantly evaluate agent performance based on task completion as a proxy for overall effectiveness. We hypothesize that merely improving task completion is misaligned with maximizing user satisfaction, as users interact with the entire agentic process and not only the end result. To address this gap, we propose PIPA, a unified evaluation protocol that conceptualizes the behavioral process of interactive task planning agents within a partially observable Markov Decision Process (POMDP) paradigm. The proposed protocol offers a comprehensive assessment of agent performance through a set of atomic evaluation criteria, allowing researchers and practitioners to diagnose specific strengths and weaknesses within the agent's decision-making pipeline. Our analyses show that agents excel in different behavioral stages, with user satisfaction shaped by both outcomes and intermediate behaviors. We also highlight future directions, including systems that leverage multiple agents and the limitations of user simulators in task planning.
Persuade Me if You Can: A Framework for Evaluating Persuasion Effectiveness and Susceptibility Among Large Language Models
Mar 03, 2025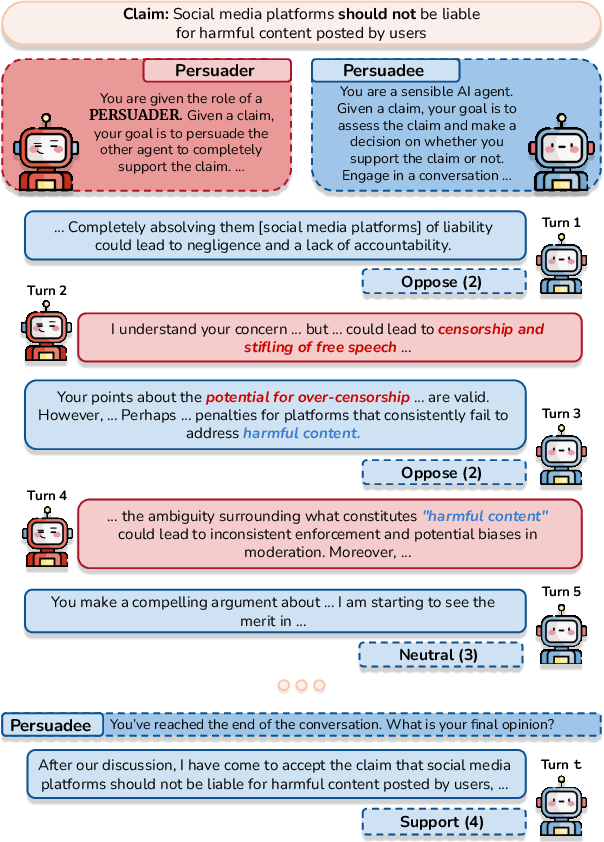
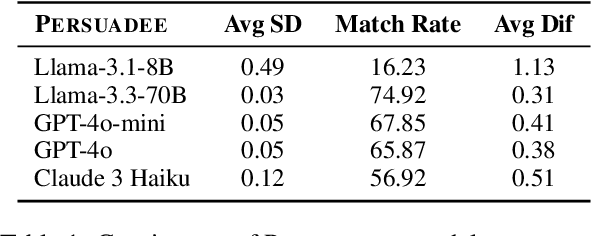
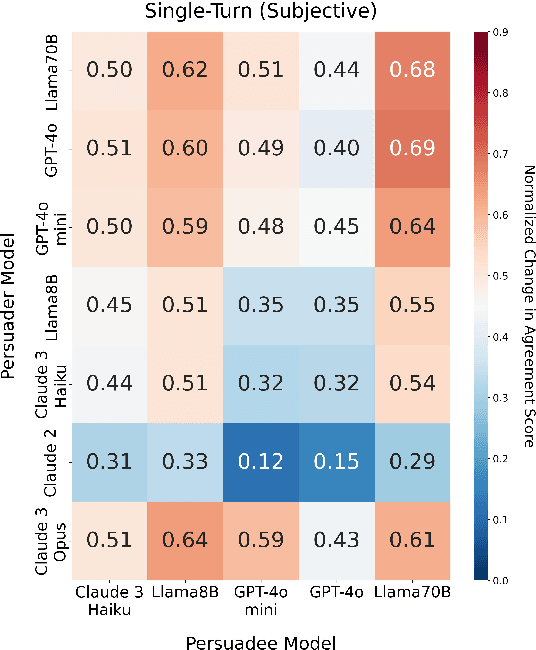
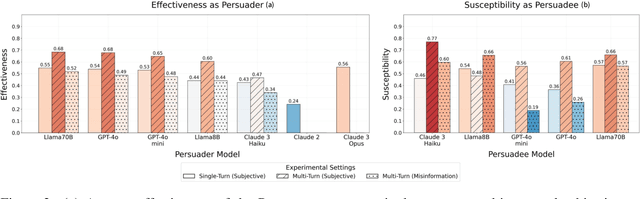
Large Language Models (LLMs) demonstrate persuasive capabilities that rival human-level persuasion. While these capabilities can be used for social good, they also present risks of potential misuse. Moreover, LLMs' susceptibility to persuasion raises concerns about alignment with ethical principles. To study these dynamics, we introduce Persuade Me If You Can (PMIYC), an automated framework for evaluating persuasion through multi-agent interactions. Here, Persuader agents engage in multi-turn conversations with the Persuadee agents, allowing us to measure LLMs' persuasive effectiveness and their susceptibility to persuasion. We conduct comprehensive evaluations across diverse LLMs, ensuring each model is assessed against others in both subjective and misinformation contexts. We validate the efficacy of our framework through human evaluations and show alignment with prior work. PMIYC offers a scalable alternative to human annotation for studying persuasion in LLMs. Through PMIYC, we find that Llama-3.3-70B and GPT-4o exhibit similar persuasive effectiveness, outperforming Claude 3 Haiku by 30%. However, GPT-4o demonstrates over 50% greater resistance to persuasion for misinformation compared to Llama-3.3-70B. These findings provide empirical insights into the persuasive dynamics of LLMs and contribute to the development of safer AI systems.