 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgemCLM: A Function-Infused and Synthesis-Friendly Modular Chemical Language Model
May 18, 2025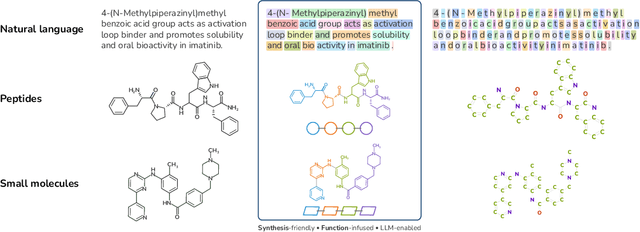
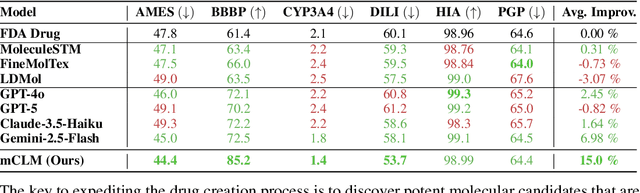
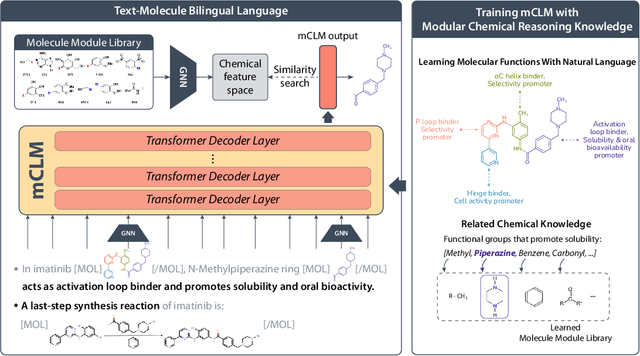
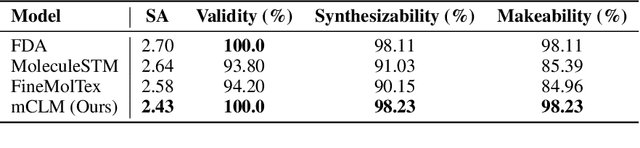
Despite their ability to understand chemical knowledge and accurately generate sequential representations, large language models (LLMs) remain limited in their capacity to propose novel molecules with drug-like properties. In addition, the molecules that LLMs propose can often be challenging to make in the lab. To more effectively enable the discovery of functional small molecules, LLMs need to learn a molecular language. However, LLMs are currently limited by encoding molecules from atoms. In this paper, we argue that just like tokenizing texts into (sub-)word tokens instead of characters, molecules should be decomposed and reassembled at the level of functional building blocks, i.e., parts of molecules that bring unique functions and serve as effective building blocks for real-world automated laboratory synthesis. This motivates us to propose mCLM, a modular Chemical-Language Model tokenizing molecules into building blocks and learning a bilingual language model of both natural language descriptions of functions and molecule building blocks. By reasoning on such functional building blocks, mCLM guarantees to generate efficiently synthesizable molecules thanks to recent progress in block-based chemistry, while also improving the functions of molecules in a principled manner. In experiments on 430 FDA-approved drugs, we find mCLM capable of significantly improving 5 out of 6 chemical functions critical to determining drug potentials. More importantly, mCLM can reason on multiple functions and improve the FDA-rejected drugs (``fallen angels'') over multiple iterations to greatly improve their shortcomings.