 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOccuBench: Evaluating AI Agents on Real-World Professional Tasks via Language World Models
Apr 13, 2026AI agents are expected to perform professional work across hundreds of occupational domains (from emergency department triage to nuclear reactor safety monitoring to customs import processing), yet existing benchmarks can only evaluate agents in the few domains where public environments exist. We introduce OccuBench, a benchmark covering 100 real-world professional task scenarios across 10 industry categories and 65 specialized domains, enabled by Language World Models (LWMs) that simulate domain-specific environments through LLM-driven tool response generation. Our multi-agent synthesis pipeline automatically produces evaluation instances with guaranteed solvability, calibrated difficulty, and document-grounded diversity. OccuBench evaluates agents along two complementary dimensions: task completion across professional domains and environmental robustness under controlled fault injection (explicit errors, implicit data degradation, and mixed faults). We evaluate 15 frontier models across 8 model families and find that: (1) no single model dominates all industries, as each has a distinct occupational capability profile; (2) implicit faults (truncated data, missing fields) are harder than both explicit errors (timeouts, 500s) and mixed faults, because they lack overt error signals and require the agent to independently detect data degradation; (3) larger models, newer generations, and higher reasoning effort consistently improve performance. GPT-5.2 improves by 27.5 points from minimal to maximum reasoning effort; and (4) strong agents are not necessarily strong environment simulators. Simulator quality is critical for LWM-based evaluation reliability. OccuBench provides the first systematic cross-industry evaluation of AI agents on professional occupational tasks.
Outcome Accuracy is Not Enough: Aligning the Reasoning Process of Reward Models
Feb 04, 2026Generative Reward Models (GenRMs) and LLM-as-a-Judge exhibit deceptive alignment by producing correct judgments for incorrect reasons, as they are trained and evaluated to prioritize Outcome Accuracy, which undermines their ability to generalize during RLHF. We introduce Rationale Consistency, a fine-grained metric that quantifies the alignment between the model's reasoning process and human judgment. Our evaluation of frontier models reveals that rationale consistency effectively discriminates among state-of-the-art models and detects deceptive alignment, while outcome accuracy falls short in both respects. To mitigate this gap, we introduce a hybrid signal that combines rationale consistency with outcome accuracy for GenRM training. Our training method achieves state-of-the-art performance on RM-Bench (87.1%) and JudgeBench (82%), surpassing outcome-only baselines by an average of 5%. Using RM during RLHF, our method effectively improves performance as demonstrated on Arena Hard v2, notably yielding a 7% improvement in creative writing tasks. Further analysis confirms that our method escapes the deceptive alignment trap, effectively reversing the decline in rationale consistency observed in outcome-only training.
StockBench: Can LLM Agents Trade Stocks Profitably In Real-world Markets?
Oct 02, 2025Large language models (LLMs) have recently demonstrated strong capabilities as autonomous agents, showing promise in reasoning, tool use, and sequential decision-making. While prior benchmarks have evaluated LLM agents in domains such as software engineering and scientific discovery, the finance domain remains underexplored, despite its direct relevance to economic value and high-stakes decision-making. Existing financial benchmarks primarily test static knowledge through question answering, but they fall short of capturing the dynamic and iterative nature of trading. To address this gap, we introduce StockBench, a contamination-free benchmark designed to evaluate LLM agents in realistic, multi-month stock trading environments. Agents receive daily market signals -- including prices, fundamentals, and news -- and must make sequential buy, sell, or hold decisions. Performance is assessed using financial metrics such as cumulative return, maximum drawdown, and the Sortino ratio. Our evaluation of state-of-the-art proprietary (e.g., GPT-5, Claude-4) and open-weight (e.g., Qwen3, Kimi-K2, GLM-4.5) models shows that while most LLM agents struggle to outperform the simple buy-and-hold baseline, several models demonstrate the potential to deliver higher returns and manage risk more effectively. These findings highlight both the challenges and opportunities in developing LLM-powered financial agents, showing that excelling at static financial knowledge tasks does not necessarily translate into successful trading strategies. We release StockBench as an open-source resource to support reproducibility and advance future research in this domain.
Are Reasoning Models More Prone to Hallucination?
May 29, 2025Recently evolved large reasoning models (LRMs) show powerful performance in solving complex tasks with long chain-of-thought (CoT) reasoning capability. As these LRMs are mostly developed by post-training on formal reasoning tasks, whether they generalize the reasoning capability to help reduce hallucination in fact-seeking tasks remains unclear and debated. For instance, DeepSeek-R1 reports increased performance on SimpleQA, a fact-seeking benchmark, while OpenAI-o3 observes even severer hallucination. This discrepancy naturally raises the following research question: Are reasoning models more prone to hallucination? This paper addresses the question from three perspectives. (1) We first conduct a holistic evaluation for the hallucination in LRMs. Our analysis reveals that LRMs undergo a full post-training pipeline with cold start supervised fine-tuning (SFT) and verifiable reward RL generally alleviate their hallucination. In contrast, both distillation alone and RL training without cold start fine-tuning introduce more nuanced hallucinations. (2) To explore why different post-training pipelines alters the impact on hallucination in LRMs, we conduct behavior analysis. We characterize two critical cognitive behaviors that directly affect the factuality of a LRM: Flaw Repetition, where the surface-level reasoning attempts repeatedly follow the same underlying flawed logic, and Think-Answer Mismatch, where the final answer fails to faithfully match the previous CoT process. (3) Further, we investigate the mechanism behind the hallucination of LRMs from the perspective of model uncertainty. We find that increased hallucination of LRMs is usually associated with the misalignment between model uncertainty and factual accuracy. Our work provides an initial understanding of the hallucination in LRMs.
Toward Generalizable Evaluation in the LLM Era: A Survey Beyond Benchmarks
Apr 26, 2025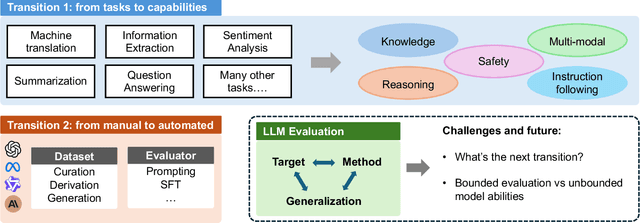
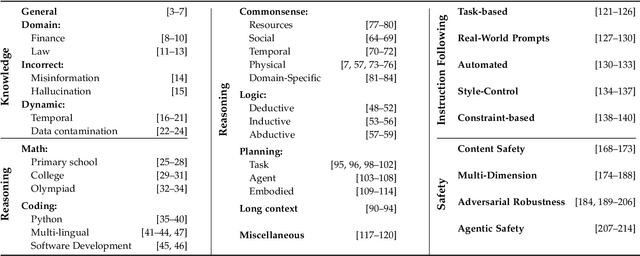
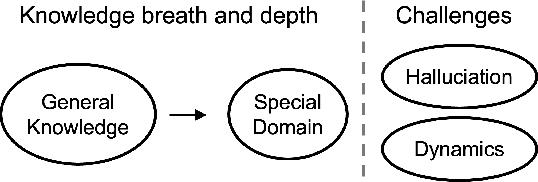
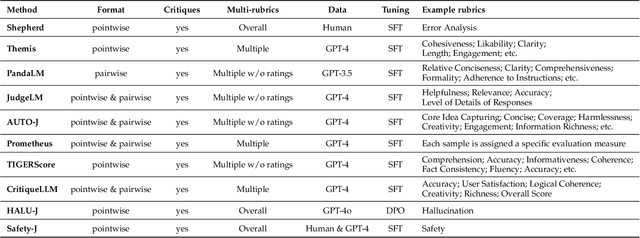
Large Language Models (LLMs) are advancing at an amazing speed and have become indispensable across academia, industry, and daily applications. To keep pace with the status quo, this survey probes the core challenges that the rise of LLMs poses for evaluation. We identify and analyze two pivotal transitions: (i) from task-specific to capability-based evaluation, which reorganizes benchmarks around core competencies such as knowledge, reasoning, instruction following, multi-modal understanding, and safety; and (ii) from manual to automated evaluation, encompassing dynamic dataset curation and "LLM-as-a-judge" scoring. Yet, even with these transitions, a crucial obstacle persists: the evaluation generalization issue. Bounded test sets cannot scale alongside models whose abilities grow seemingly without limit. We will dissect this issue, along with the core challenges of the above two transitions, from the perspectives of methods, datasets, evaluators, and metrics. Due to the fast evolving of this field, we will maintain a living GitHub repository (links are in each section) to crowd-source updates and corrections, and warmly invite contributors and collaborators.
RM-Bench: Benchmarking Reward Models of Language Models with Subtlety and Style
Oct 21, 2024



Reward models are critical in techniques like Reinforcement Learning from Human Feedback (RLHF) and Inference Scaling Laws, where they guide language model alignment and select optimal responses. Despite their importance, existing reward model benchmarks often evaluate models by asking them to distinguish between responses generated by models of varying power. However, this approach fails to assess reward models on subtle but critical content changes and variations in style, resulting in a low correlation with policy model performance. To this end, we introduce RM-Bench, a novel benchmark designed to evaluate reward models based on their sensitivity to subtle content differences and resistance to style biases. Extensive experiments demonstrate that RM-Bench strongly correlates with policy model performance, making it a reliable reference for selecting reward models to align language models effectively. We evaluate nearly 40 reward models on RM-Bench. Our results reveal that even state-of-the-art models achieve an average performance of only 46.6%, which falls short of random-level accuracy (50%) when faced with style bias interference. These findings highlight the significant room for improvement in current reward models. Related code and data are available at https://github.com/THU-KEG/RM-Bench.
Aligning Teacher with Student Preferences for Tailored Training Data Generation
Jun 27, 2024



Large Language Models (LLMs) have shown significant promise as copilots in various tasks. Local deployment of LLMs on edge devices is necessary when handling privacy-sensitive data or latency-sensitive tasks. The computational constraints of such devices make direct deployment of powerful large-scale LLMs impractical, necessitating the Knowledge Distillation from large-scale models to lightweight models. Lots of work has been done to elicit diversity and quality training examples from LLMs, but little attention has been paid to aligning teacher instructional content based on student preferences, akin to "responsive teaching" in pedagogy. Thus, we propose ARTE, dubbed Aligning TeacheR with StudenT PreferencEs, a framework that aligns the teacher model with student preferences to generate tailored training examples for Knowledge Distillation. Specifically, we elicit draft questions and rationales from the teacher model, then collect student preferences on these questions and rationales using students' performance with in-context learning as a proxy, and finally align the teacher model with student preferences. In the end, we repeat the first step with the aligned teacher model to elicit tailored training examples for the student model on the target task. Extensive experiments on academic benchmarks demonstrate the superiority of ARTE over existing instruction-tuning datasets distilled from powerful LLMs. Moreover, we thoroughly investigate the generalization of ARTE, including the generalization of fine-tuned student models in reasoning ability and the generalization of aligned teacher models to generate tailored training data across tasks and students. In summary, our contributions lie in proposing a novel framework for tailored training example generation, demonstrating its efficacy in experiments, and investigating the generalization of both student & aligned teacher models in ARTE.
Evaluating Generative Language Models in Information Extraction as Subjective Question Correction
Apr 04, 2024Modern Large Language Models (LLMs) have showcased remarkable prowess in various tasks necessitating sophisticated cognitive behaviors. Nevertheless, a paradoxical performance discrepancy is observed, where these models underperform in seemingly elementary tasks like relation extraction and event extraction due to two issues in conventional evaluation. (1) The imprecision of existing evaluation metrics that struggle to effectively gauge semantic consistency between model outputs and ground truth, and (2) The inherent incompleteness of evaluation benchmarks, primarily due to restrictive human annotation schemas, resulting in underestimated LLM performances. Inspired by the principles in subjective question correction, we propose a new evaluation method, SQC-Score. This method innovatively utilizes LLMs, fine-tuned through subjective question correction data, to refine matching between model outputs and golden labels. Additionally, by incorporating a Natural Language Inference (NLI) model, SQC-Score enriches golden labels, addressing benchmark incompleteness by acknowledging correct yet previously omitted answers. Results on three information extraction tasks show that SQC-Score is more preferred by human annotators than the baseline metrics. Utilizing SQC-Score, we conduct a comprehensive evaluation of the state-of-the-art LLMs and provide insights for future research for information extraction. Dataset and associated codes can be accessed at https://github.com/THU-KEG/SQC-Score.
Untangle the KNOT: Interweaving Conflicting Knowledge and Reasoning Skills in Large Language Models
Apr 04, 2024Providing knowledge documents for large language models (LLMs) has emerged as a promising solution to update the static knowledge inherent in their parameters. However, knowledge in the document may conflict with the memory of LLMs due to outdated or incorrect knowledge in the LLMs' parameters. This leads to the necessity of examining the capability of LLMs to assimilate supplemental external knowledge that conflicts with their memory. While previous studies have explained to what extent LLMs extract conflicting knowledge from the provided text, they neglect the necessity to reason with conflicting knowledge. Furthermore, there lack a detailed analysis on strategies to enable LLMs to resolve conflicting knowledge via prompting, decoding strategy, and supervised fine-tuning. To address these limitations, we construct a new dataset, dubbed KNOT, for knowledge conflict resolution examination in the form of question answering. KNOT facilitates in-depth analysis by dividing reasoning with conflicting knowledge into three levels: (1) Direct Extraction, which directly extracts conflicting knowledge to answer questions. (2) Explicit Reasoning, which reasons with conflicting knowledge when the reasoning path is explicitly provided in the question. (3) Implicit Reasoning, where reasoning with conflicting knowledge requires LLMs to infer the reasoning path independently to answer questions. We also conduct extensive experiments on KNOT to establish empirical guidelines for LLMs to utilize conflicting knowledge in complex circumstances. Dataset and associated codes can be accessed at https://github.com/THU-KEG/KNOT .
KnowCoder: Coding Structured Knowledge into LLMs for Universal Information Extraction
Mar 14, 2024



In this paper, we propose KnowCoder, a Large Language Model (LLM) to conduct Universal Information Extraction (UIE) via code generation. KnowCoder aims to develop a kind of unified schema representation that LLMs can easily understand and an effective learning framework that encourages LLMs to follow schemas and extract structured knowledge accurately. To achieve these, KnowCoder introduces a code-style schema representation method to uniformly transform different schemas into Python classes, with which complex schema information, such as constraints among tasks in UIE, can be captured in an LLM-friendly manner. We further construct a code-style schema library covering over $\textbf{30,000}$ types of knowledge, which is the largest one for UIE, to the best of our knowledge. To ease the learning process of LLMs, KnowCoder contains a two-phase learning framework that enhances its schema understanding ability via code pretraining and its schema following ability via instruction tuning. After code pretraining on around $1.5$B automatically constructed data, KnowCoder already attains remarkable generalization ability and achieves relative improvements by $\textbf{49.8%}$ F1, compared to LLaMA2, under the few-shot setting. After instruction tuning, KnowCoder further exhibits strong generalization ability on unseen schemas and achieves up to $\textbf{12.5%}$ and $\textbf{21.9%}$, compared to sota baselines, under the zero-shot setting and the low resource setting, respectively. Additionally, based on our unified schema representations, various human-annotated datasets can simultaneously be utilized to refine KnowCoder, which achieves significant improvements up to $\textbf{7.5%}$ under the supervised setting.