 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaPlanBench: Evaluating Adaptive Planning in Large Language Model Agents under World and User Constraints
Jun 04, 2026Planning for real-world problems by language models often involves both world and user constraints, which may not be fully specified upfront and are progressively disclosed through interaction. However, existing benchmarks still underexplore adaptive planning under such progressively revealed dual constraints. To address this gap, we introduce AdaPlanBench, a dynamic interactive benchmark for evaluating whether Large Language Model (LLM) agents can adaptively plan and re-plan under progressively revealed world and user constraints. AdaPlanBench is built on 307 household tasks, with a scalable constraint construction pipeline that augments each task with dual constraints. At runtime, agents interact with the environment in a multi-turn protocol where hidden constraints are revealed only when the agent proposes a plan that violates them, requiring iterative plan revision under accumulating feedback. This makes planning challenging, as agents must infer and track constraints from feedback while re-planning effectively. Experiments on ten leading LLMs show that adaptive planning under dual constraints remains challenging, with the best model reaching only 67.75% accuracy. We further observe that performance degrades as more constraints accumulate, with user constraints posing a particularly large challenge and failures often stemming from weaker physical grounding and reduced effectiveness. These results establish AdaPlanBench as a testbed for dual-constrained interactive planning and highlight the challenge of reliable adaptation to dynamically revealed constraints in LLM agents.
Advancing Creative Physical Intelligence in Large Multimodal Models
May 25, 2026Large multimodal models (LMMs) have rapidly advanced in perception and reasoning; however, it remains unclear whether these capabilities generalize to discovering visually grounded solutions in open-ended environments, beyond pattern recognition. In such settings, intelligence requires more than answering well-posed questions: it involves identifying how elements in a scene can be repurposed in non-obvious yet physically feasible ways. This form of creative problem-solving is central to human intelligence, but remains largely untested in current benchmarks. To evaluate this ability, we introduce MM-CreativityBench, a benchmark for affordance-grounded creative tool use in visually rich, physically constrained environments. Each instance presents a scenario image with structured views of candidate entities and their parts, enabling fine-grained, interactive evaluation of how models iteratively inspect the scene, identify relevant affordances, and compose visually and physically grounded solutions. Our experiments show that current LMMs often fall short, not due to lack of generative capability, but because they do not sustain grounded exploration. Models often overlook relevant entities, under-examine critical parts, or hallucinate attributes not grounded in the image. Motivated by this failure mode, we propose affordance-grounded alignment, which casts creative tool use as a preference learning problem. Using Direct Preference Optimization, we encourage models to prefer attribute-affordance reasoning grounded in visual evidence over hallucinated alternatives. In addition, we incorporate supervision derived from an affordance knowledge base to guide broader entity exploration and multi-turn planning. Our results show consistent gains in selecting the correct entities and parts, while substantially reducing hallucination and grounding-related errors.
Decoding the Critique Mechanism in Large Reasoning Models
Mar 17, 2026Large Reasoning Models (LRMs) exhibit backtracking and self-verification mechanisms that enable them to revise intermediate steps and reach correct solutions, yielding strong performance on complex logical benchmarks. We hypothesize that such behaviors are beneficial only when the model has sufficiently strong "critique" ability to detect its own mistakes. This work systematically investigates how current LRMs recover from errors by inserting arithmetic mistakes in their intermediate reasoning steps. Notably, we discover a peculiar yet important phenomenon: despite the error propagating through the chain-of-thought (CoT), resulting in an incorrect intermediate conclusion, the model still reaches the correct final answer. This recovery implies that the model must possess an internal mechanism to detect errors and trigger self-correction, which we refer to as the hidden critique ability. Building on feature space analysis, we identify a highly interpretable critique vector representing this behavior. Extensive experiments across multiple model scales and families demonstrate that steering latent representations with this vector improves the model's error detection capability and enhances the performance of test-time scaling at no extra training cost. Our findings provide a valuable understanding of LRMs' critique behavior, suggesting a promising direction to control and improve their self-verification mechanism. Our code is available at https://github.com/mail-research/lrm-critique-vectors.
How Far Can Unsupervised RLVR Scale LLM Training?
Mar 09, 2026Unsupervised reinforcement learning with verifiable rewards (URLVR) offers a pathway to scale LLM training beyond the supervision bottleneck by deriving rewards without ground truth labels. Recent works leverage model intrinsic signals, showing promising early gains, yet their potential and limitations remain unclear. In this work, we revisit URLVR and provide a comprehensive analysis spanning taxonomy, theory and extensive experiments. We first classify URLVR methods into intrinsic versus external based on reward sources, then establish a unified theoretical framework revealing that all intrinsic methods converge toward sharpening the model's initial distribution This sharpening mechanism succeeds when initial confidence aligns with correctness but fails catastrophically when misaligned. Through systematic experiments, we show intrinsic rewards consistently follow a rise-then-fall pattern across methods, with collapse timing determined by model prior rather than engineering choices. Despite these scaling limits, we find intrinsic rewards remain valuable in test-time training on small datasets, and propose Model Collapse Step to measure model prior, serving as a practical indicator for RL trainability. Finally, we explore external reward methods that ground verification in computational asymmetries, showing preliminary evidence they may escape the confidence-correctness ceiling. Our findings chart boundaries for intrinsic URLVR while motivating paths toward scalable alternatives.
Why Reasoning Fails to Plan: A Planning-Centric Analysis of Long-Horizon Decision Making in LLM Agents
Jan 29, 2026Large language model (LLM)-based agents exhibit strong step-by-step reasoning capabilities over short horizons, yet often fail to sustain coherent behavior over long planning horizons. We argue that this failure reflects a fundamental mismatch: step-wise reasoning induces a form of step-wise greedy policy that is adequate for short horizons but fails in long-horizon planning, where early actions must account for delayed consequences. From this planning-centric perspective, we study LLM-based agents in deterministic, fully structured environments with explicit state transitions and evaluation signals. Our analysis reveals a core failure mode of reasoning-based policies: locally optimal choices induced by step-wise scoring lead to early myopic commitments that are systematically amplified over time and difficult to recover from. We introduce FLARE (Future-aware Lookahead with Reward Estimation) as a minimal instantiation of future-aware planning to enforce explicit lookahead, value propagation, and limited commitment in a single model, allowing downstream outcomes to influence early decisions. Across multiple benchmarks, agent frameworks, and LLM backbones, FLARE consistently improves task performance and planning-level behavior, frequently allowing LLaMA-8B with FLARE to outperform GPT-4o with standard step-by-step reasoning. These results establish a clear distinction between reasoning and planning.
PEARL: Self-Evolving Assistant for Time Management with Reinforcement Learning
Jan 17, 2026Overlapping calendar invitations force busy professionals to repeatedly decide which meetings to attend, reschedule, or decline. We refer to this preference-driven decision process as calendar conflict resolution. Automating such process is crucial yet challenging. Scheduling logistics drain hours, and human delegation often fails at scale, which motivate we to ask: Can we trust large language model (LLM) or language agent to manager time? To enable systematic study of this question, we introduce CalConflictBench, a benchmark for long-horizon calendar conflict resolution. Conflicts are presented sequentially and agents receive feedback after each round, requiring them to infer and adapt to user preferences progressively. Our experiments show that current LLM agents perform poorly with high error rates, e.g., Qwen-3-30B-Think has 35% average error rate. To address this gap, we propose PEARL, a reinforcement-learning framework that augments language agent with an external memory module and optimized round-wise reward design, enabling agent to progressively infer and adapt to user preferences on-the-fly. Experiments on CalConflictBench shows that PEARL achieves 0.76 error reduction rate, and 55% improvement in average error rate compared to the strongest baseline.
Current Agents Fail to Leverage World Model as Tool for Foresight
Jan 08, 2026Agents built on vision-language models increasingly face tasks that demand anticipating future states rather than relying on short-horizon reasoning. Generative world models offer a promising remedy: agents could use them as external simulators to foresee outcomes before acting. This paper empirically examines whether current agents can leverage such world models as tools to enhance their cognition. Across diverse agentic and visual question answering tasks, we observe that some agents rarely invoke simulation (fewer than 1%), frequently misuse predicted rollouts (approximately 15%), and often exhibit inconsistent or even degraded performance (up to 5%) when simulation is available or enforced. Attribution analysis further indicates that the primary bottleneck lies in the agents' capacity to decide when to simulate, how to interpret predicted outcomes, and how to integrate foresight into downstream reasoning. These findings underscore the need for mechanisms that foster calibrated, strategic interaction with world models, paving the way toward more reliable anticipatory cognition in future agent systems.
Veri-R1: Toward Precise and Faithful Claim Verification via Online Reinforcement Learning
Oct 02, 2025



Claim verification with large language models (LLMs) has recently attracted considerable attention, owing to their superior reasoning capabilities and transparent verification pathways compared to traditional answer-only judgments. Online claim verification requires iterative evidence retrieval and reasoning, yet existing approaches mainly rely on prompt engineering or predesigned reasoning workflows without offering a unified training paradigm to improve necessary skills. Therefore, we introduce Veri-R1, an online reinforcement learning (RL) framework that enables an LLM to interact with a search engine and to receive reward signals that explicitly shape its planning, retrieval, and reasoning behaviors. The dynamic interaction between models and retrieval systems more accurately reflects real-world verification scenarios and fosters comprehensive verification skills. Empirical results show that Veri-R1 improves joint accuracy by up to 30% and doubles evidence score, often surpassing larger-scale counterparts. Ablation studies further reveal the impact of reward components and the link between output logits and label accuracy. Our results highlight the effectiveness of online RL for precise and faithful claim verification and provide a foundation for future research. We release our code to support community progress in LLM empowered claim verification.
Beyond Log Likelihood: Probability-Based Objectives for Supervised Fine-Tuning across the Model Capability Continuum
Oct 01, 2025Supervised fine-tuning (SFT) is the standard approach for post-training large language models (LLMs), yet it often shows limited generalization. We trace this limitation to its default training objective: negative log likelihood (NLL). While NLL is classically optimal when training from scratch, post-training operates in a different paradigm and could violate its optimality assumptions, where models already encode task-relevant priors and supervision can be long and noisy. To this end, we study a general family of probability-based objectives and characterize their effectiveness under different conditions. Through comprehensive experiments and extensive ablation studies across 7 model backbones, 14 benchmarks, and 3 domains, we uncover a critical dimension that governs objective behavior: the model-capability continuum. Near the model-strong end, prior-leaning objectives that downweight low-probability tokens (e.g., $-p$, $-p^{10}$, thresholded variants) consistently outperform NLL; toward the model-weak end, NLL dominates; in between, no single objective prevails. Our theoretical analysis further elucidates how objectives trade places across the continuum, providing a principled foundation for adapting objectives to model capability. Our code is available at https://github.com/GaotangLi/Beyond-Log-Likelihood.
Perception-Aware Policy Optimization for Multimodal Reasoning
Jul 08, 2025
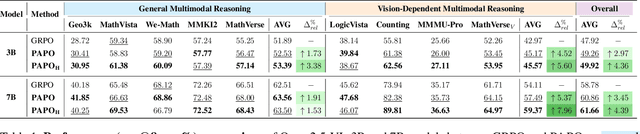
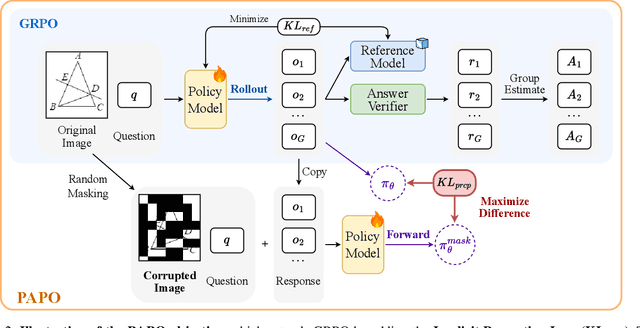
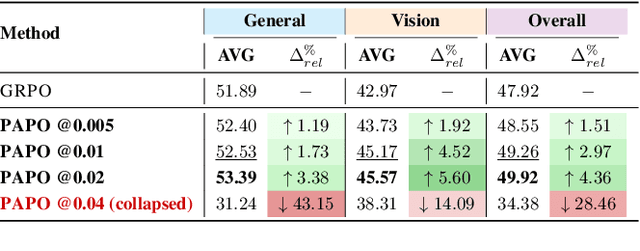
Reinforcement Learning with Verifiable Rewards (RLVR) has proven to be a highly effective strategy for endowing Large Language Models (LLMs) with robust multi-step reasoning abilities. However, its design and optimizations remain tailored to purely textual domains, resulting in suboptimal performance when applied to multimodal reasoning tasks. In particular, we observe that a major source of error in current multimodal reasoning lies in the perception of visual inputs. To address this bottleneck, we propose Perception-Aware Policy Optimization (PAPO), a simple yet effective extension of GRPO that encourages the model to learn to perceive while learning to reason, entirely from internal supervision signals. Notably, PAPO does not rely on additional data curation, external reward models, or proprietary models. Specifically, we introduce the Implicit Perception Loss in the form of a KL divergence term to the GRPO objective, which, despite its simplicity, yields significant overall improvements (4.4%) on diverse multimodal benchmarks. The improvements are more pronounced, approaching 8.0%, on tasks with high vision dependency. We also observe a substantial reduction (30.5%) in perception errors, indicating improved perceptual capabilities with PAPO. We conduct comprehensive analysis of PAPO and identify a unique loss hacking issue, which we rigorously analyze and mitigate through a Double Entropy Loss. Overall, our work introduces a deeper integration of perception-aware supervision into RLVR learning objectives and lays the groundwork for a new RL framework that encourages visually grounded reasoning. Project page: https://mikewangwzhl.github.io/PAPO.