 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLARITY: A Framework and Benchmark for Conversational Language Ambiguity and Unanswerability in Interactive NL2SQL Systems
Apr 24, 2026NL2SQL systems deployed in industry settings often encounter ambiguous or unanswerable queries, particularly in interactive scenarios with incomplete user clarification. Existing benchmarks typically assume a single source of ambiguity and rely on user interaction for resolution, overlooking realistic failure modes. We introduce Clarity, a framework for automatically generating an NL2SQL benchmark with multi-faceted ambiguities and diverse user behaviors across both single- and multi-turn settings. Using a constraint-driven pipeline, Clarity transforms executable SQL into ambiguous queries, augmented with grounded conversational continuations and schema-level metadata. Empirical evaluation on Spider and BIRD shows that leading NL2SQL systems, including those based on strong LLMs, suffer significant performance degradation under multi-faceted ambiguity. While these systems often detect ambiguity, they struggle to accurately localize and resolve the underlying schema-level sources. Our results highlight the need for more robust ambiguity detection and resolution in industry-grade NL2SQL systems.
ModelingAgent: Bridging LLMs and Mathematical Modeling for Real-World Challenges
May 21, 2025



Recent progress in large language models (LLMs) has enabled substantial advances in solving mathematical problems. However, existing benchmarks often fail to reflect the complexity of real-world problems, which demand open-ended, interdisciplinary reasoning and integration of computational tools. To address this gap, we introduce ModelingBench, a novel benchmark featuring real-world-inspired, open-ended problems from math modeling competitions across diverse domains, ranging from urban traffic optimization to ecosystem resource planning. These tasks require translating natural language into formal mathematical formulations, applying appropriate tools, and producing structured, defensible reports. ModelingBench also supports multiple valid solutions, capturing the ambiguity and creativity of practical modeling. We also present ModelingAgent, a multi-agent framework that coordinates tool use, supports structured workflows, and enables iterative self-refinement to generate well-grounded, creative solutions. To evaluate outputs, we further propose ModelingJudge, an expert-in-the-loop system leveraging LLMs as domain-specialized judges assessing solutions from multiple expert perspectives. Empirical results show that ModelingAgent substantially outperforms strong baselines and often produces solutions indistinguishable from those of human experts. Together, our work provides a comprehensive framework for evaluating and advancing real-world problem-solving in open-ended, interdisciplinary modeling challenges.
SeaView: Software Engineering Agent Visual Interface for Enhanced Workflow
Apr 14, 2025



Auto-regressive LLM-based software engineering (SWE) agents, henceforth SWE agents, have made tremendous progress (>60% on SWE-Bench Verified) on real-world coding challenges including GitHub issue resolution. SWE agents use a combination of reasoning, environment interaction and self-reflection to resolve issues thereby generating "trajectories". Analysis of SWE agent trajectories is difficult, not only as they exceed LLM sequence length (sometimes, greater than 128k) but also because it involves a relatively prolonged interaction between an LLM and the environment managed by the agent. In case of an agent error, it can be hard to decipher, locate and understand its scope. Similarly, it can be hard to track improvements or regression over multiple runs or experiments. While a lot of research has gone into making these SWE agents reach state-of-the-art, much less focus has been put into creating tools to help analyze and visualize agent output. We propose a novel tool called SeaView: Software Engineering Agent Visual Interface for Enhanced Workflow, with a vision to assist SWE-agent researchers to visualize and inspect their experiments. SeaView's novel mechanisms help compare experimental runs with varying hyper-parameters or LLMs, and quickly get an understanding of LLM or environment related problems. Based on our user study, experienced researchers spend between 10 and 30 minutes to gather the information provided by SeaView, while researchers with little experience can spend between 30 minutes to 1 hour to diagnose their experiment.
Granite Embedding Models
Feb 27, 2025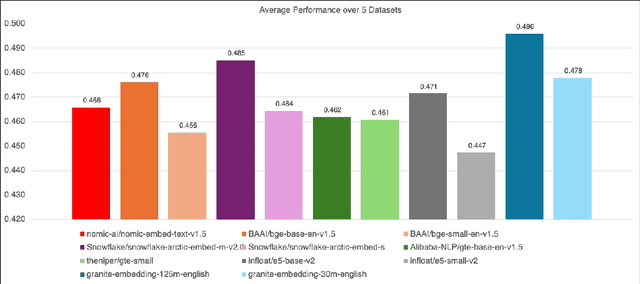
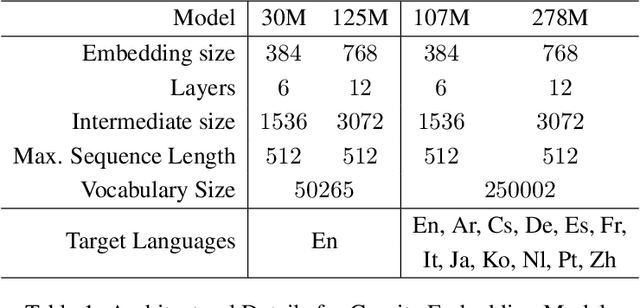
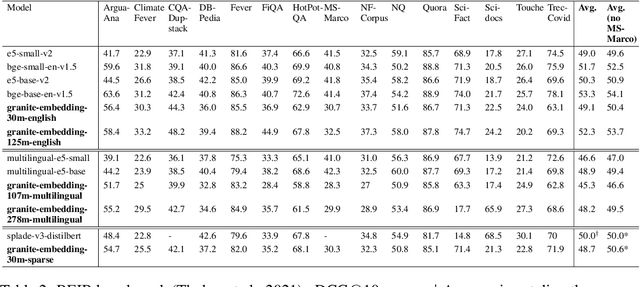

We introduce the Granite Embedding models, a family of encoder-based embedding models designed for retrieval tasks, spanning dense-retrieval and sparse retrieval architectures, with both English and Multilingual capabilities. This report provides the technical details of training these highly effective 12 layer embedding models, along with their efficient 6 layer distilled counterparts. Extensive evaluations show that the models, developed with techniques like retrieval oriented pretraining, contrastive finetuning, knowledge distillation, and model merging significantly outperform publicly available models of similar sizes on both internal IBM retrieval and search tasks, and have equivalent performance on widely used information retrieval benchmarks, while being trained on high-quality data suitable for enterprise use. We publicly release all our Granite Embedding models under the Apache 2.0 license, allowing both research and commercial use at https://huggingface.co/collections/ibm-granite.
SMART: Self-Aware Agent for Tool Overuse Mitigation
Feb 17, 2025



Current Large Language Model (LLM) agents demonstrate strong reasoning and tool use capabilities, but often lack self-awareness, failing to balance these approaches effectively. This imbalance leads to Tool Overuse, where models unnecessarily rely on external tools for tasks solvable with parametric knowledge, increasing computational overhead. Inspired by human metacognition, we introduce SMART (Strategic Model-Aware Reasoning with Tools), a paradigm that enhances an agent's self-awareness to optimize task handling and reduce tool overuse. To support this paradigm, we introduce SMART-ER, a dataset spanning three domains, where reasoning alternates between parametric knowledge and tool-dependent steps, with each step enriched by rationales explaining when tools are necessary. Through supervised training, we develop SMARTAgent, a family of models that dynamically balance parametric knowledge and tool use. Evaluations show that SMARTAgent reduces tool use by 24% while improving performance by over 37%, enabling 7B-scale models to match its 70B counterpart and GPT-4o. Additionally, SMARTAgent generalizes to out-of-distribution test data like GSM8K and MINTQA, maintaining accuracy with just one-fifth the tool calls. These highlight the potential of strategic tool use to enhance reasoning, mitigate overuse, and bridge the gap between model size and performance, advancing intelligent and resource-efficient agent designs.
Transforming the Hybrid Cloud for Emerging AI Workloads
Nov 20, 2024
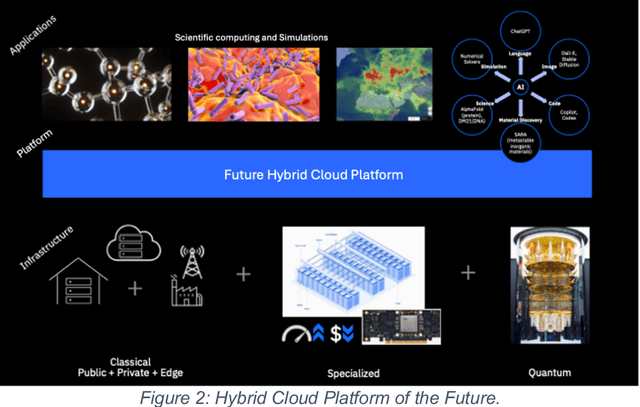
This white paper, developed through close collaboration between IBM Research and UIUC researchers within the IIDAI Institute, envisions transforming hybrid cloud systems to meet the growing complexity of AI workloads through innovative, full-stack co-design approaches, emphasizing usability, manageability, affordability, adaptability, efficiency, and scalability. By integrating cutting-edge technologies such as generative and agentic AI, cross-layer automation and optimization, unified control plane, and composable and adaptive system architecture, the proposed framework addresses critical challenges in energy efficiency, performance, and cost-effectiveness. Incorporating quantum computing as it matures will enable quantum-accelerated simulations for materials science, climate modeling, and other high-impact domains. Collaborative efforts between academia and industry are central to this vision, driving advancements in foundation models for material design and climate solutions, scalable multimodal data processing, and enhanced physics-based AI emulators for applications like weather forecasting and carbon sequestration. Research priorities include advancing AI agentic systems, LLM as an Abstraction (LLMaaA), AI model optimization and unified abstractions across heterogeneous infrastructure, end-to-end edge-cloud transformation, efficient programming model, middleware and platform, secure infrastructure, application-adaptive cloud systems, and new quantum-classical collaborative workflows. These ideas and solutions encompass both theoretical and practical research questions, requiring coordinated input and support from the research community. This joint initiative aims to establish hybrid clouds as secure, efficient, and sustainable platforms, fostering breakthroughs in AI-driven applications and scientific discovery across academia, industry, and society.
FIRST: Faster Improved Listwise Reranking with Single Token Decoding
Jun 21, 2024



Large Language Models (LLMs) have significantly advanced the field of information retrieval, particularly for reranking. Listwise LLM rerankers have showcased superior performance and generalizability compared to existing supervised approaches. However, conventional listwise LLM reranking methods lack efficiency as they provide ranking output in the form of a generated ordered sequence of candidate passage identifiers. Further, they are trained with the typical language modeling objective, which treats all ranking errors uniformly--potentially at the cost of misranking highly relevant passages. Addressing these limitations, we introduce FIRST, a novel listwise LLM reranking approach leveraging the output logits of the first generated identifier to directly obtain a ranked ordering of the candidates. Further, we incorporate a learning-to-rank loss during training, prioritizing ranking accuracy for the more relevant passages. Empirical results demonstrate that FIRST accelerates inference by 50% while maintaining a robust ranking performance with gains across the BEIR benchmark. Finally, to illustrate the practical effectiveness of listwise LLM rerankers, we investigate their application in providing relevance feedback for retrievers during inference. Our results show that LLM rerankers can provide a stronger distillation signal compared to cross-encoders, yielding substantial improvements in retriever recall after relevance feedback.
Prompts as Auto-Optimized Training Hyperparameters: Training Best-in-Class IR Models from Scratch with 10 Gold Labels
Jun 17, 2024



We develop a method for training small-scale (under 100M parameter) neural information retrieval models with as few as 10 gold relevance labels. The method depends on generating synthetic queries for documents using a language model (LM), and the key step is that we automatically optimize the LM prompt that is used to generate these queries based on training quality. In experiments with the BIRCO benchmark, we find that models trained with our method outperform RankZephyr and are competitive with RankLLama, both of which are 7B parameter models trained on over 100K labels. These findings point to the power of automatic prompt optimization for synthetic dataset generation.
CLAPNQ: Cohesive Long-form Answers from Passages in Natural Questions for RAG systems
Apr 02, 2024Retrieval Augmented Generation (RAG) has become a popular application for large language models. It is preferable that successful RAG systems provide accurate answers that are supported by being grounded in a passage without any hallucinations. While considerable work is required for building a full RAG pipeline, being able to benchmark performance is also necessary. We present ClapNQ, a benchmark Long-form Question Answering dataset for the full RAG pipeline. ClapNQ includes long answers with grounded gold passages from Natural Questions (NQ) and a corpus to perform either retrieval, generation, or the full RAG pipeline. The ClapNQ answers are concise, 3x smaller than the full passage, and cohesive, with multiple pieces of the passage that are not contiguous. RAG models must adapt to these properties to be successful at ClapNQ. We present baseline experiments and analysis for ClapNQ that highlight areas where there is still significant room for improvement in grounded RAG. CLAPNQ is publicly available at https://github.com/primeqa/clapnq
An Empirical Investigation into the Effect of Parameter Choices in Knowledge Distillation
Jan 12, 2024



We present a large-scale empirical study of how choices of configuration parameters affect performance in knowledge distillation (KD). An example of such a KD parameter is the measure of distance between the predictions of the teacher and the student, common choices for which include the mean squared error (MSE) and the KL-divergence. Although scattered efforts have been made to understand the differences between such options, the KD literature still lacks a systematic study on their general effect on student performance. We take an empirical approach to this question in this paper, seeking to find out the extent to which such choices influence student performance across 13 datasets from 4 NLP tasks and 3 student sizes. We quantify the cost of making sub-optimal choices and identify a single configuration that performs well across the board.