 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Autonomous Agentic Data Engineering for Model Specialization
May 28, 2026Large Language Models (LLMs) have demonstrated strong performance on general tasks, while often struggling to adapt to specialized domains without high-quality domain-specific data. Existing LLM-based data curation methods primarily rely on human-designed workflows, leaving it unexamined whether LLMs can autonomously execute an end-to-end data engineering pipeline for model specialization. We formalize \textbf{Autonomous Agentic Data Engineering}, a novel task designed to evaluate LLMs as autonomous data engineers that drive model specialization through end-to-end data curation. We frame data as an optimizable component and study agents that plan, generate, and iteratively optimize training data across multiple domains, guided by post-training performance improvement. Experiments show that autonomous LLM data engineers yield substantial gains, as GPT-5.2 constructs a training curriculum that improves a student model by \textbf{57.29\%}, entirely through iterative, agent-driven data adaptation. By illuminating both potential and bottlenecks, our study establishes autonomous data engineering as a measurable capability and charts a path toward agent-driven model specialization\footnote{Code will be released at https://github.com/zjunlp/DataAgent.}.
Universally Empowering Zeroth-Order Optimization via Adaptive Layer-wise Sampling
Apr 20, 2026Zeroth-Order optimization presents a promising memory-efficient paradigm for fine-tuning Large Language Models by relying solely on forward passes. However, its practical adoption is severely constrained by slow wall-clock convergence and high estimation variance. In this work, we dissect the runtime characteristics of ZO algorithms and identify a critical system bottleneck where the generation of perturbations and parameter updates accounts for over 40% of the training latency. We argue that the standard uniform exploration strategy is fundamentally flawed as it fails to account for the heterogeneous sensitivity of layers in deep networks, resulting in computationally wasteful blind searches. To address this structural mismatch, we propose AdaLeZO, an Adaptive Layer-wise ZO optimization framework. By formulating the layer selection process as a non-stationary Multi-Armed Bandit problem, AdaLeZO dynamically allocates the limited perturbation budget to the most sensitive parameters. We further introduce an Inverse Probability Weighting mechanism based on sampling with replacement, which guarantees unbiased gradient estimation while effectively acting as a temporal denoiser to reduce variance. Extensive experiments on LLaMA and OPT models ranging from 6.7B to 30B parameters demonstrate that AdaLeZO achieves 1.7x to 3.0x wall-clock acceleration compared to state-of-the-art methods. Crucially, AdaLeZO functions as a universal plug-and-play module that seamlessly enhances the efficiency of existing ZO optimizers without incurring additional memory overhead.
Uncertainty as a Planning Signal: Multi-Turn Decision Making for Goal-Oriented Conversation
Apr 05, 2026Goal-oriented conversational systems require making sequential decisions under uncertainty about the user's intent, where the algorithm must balance information acquisition and target commitment over multiple turns. Existing approaches address this challenge from different perspectives: structured methods enable multi-step planning but rely on predefined schemas, while LLM-based approaches support flexible interactions but lack long-horizon decision making, resulting in poor coordination between information acquisition and target commitment. To address this limitation, we formulate goal-oriented conversation as an uncertainty-aware sequential decision problem, where uncertainty serves as a guiding signal for multi-turn decision making. We propose a Conversation Uncertainty-aware Planning framework (CUP) that integrates language models with structured planning: a language model proposes feasible actions, and a planner evaluates their long-term impact on uncertainty reduction. Experiments on multiple conversational benchmarks show that CUP consistently improves success rates while requiring fewer interaction turns. Further analysis demonstrates that uncertainty-aware planning contributes to more efficient information acquisition and earlier confident commitment.
Hierarchical Testing of a Hybrid Machine Learning-Physics Global Atmosphere Model
Feb 11, 2026Machine learning (ML)-based models have demonstrated high skill and computational efficiency, often outperforming conventional physics-based models in weather and subseasonal predictions. While prior studies have assessed their fidelity in capturing synoptic-scale atmospheric dynamics, their performance across timescales and under out-of-distribution forcing, such as +3K or +4K uniform-warming forcings, and the sources of biases remain elusive, to establish the model reliability for Earth science. Here, we design three sets of experiments targeting synoptic-scale phenomena, interannual variability, and out-of-distribution uniform-warming forcings. We evaluate the Neural General Circulation Model (NeuralGCM), a hybrid model integrating a dynamical core with ML-based component, against observations and physics-based Earth system models (ESMs). At the synoptic scale, NeuralGCM captures the evolution and propagation of extratropical cyclones with performance comparable to ESMs. At the interannual scale, when forced by El Niño-Southern Oscillation sea surface temperature (SST) anomalies, NeuralGCM successfully reproduces associated teleconnection patterns but exhibits deficiencies in capturing nonlinear response. Under out-of-distribution uniform-warming forcings, NeuralGCM simulates similar responses in global-average temperature and precipitation and reproduces large-scale tropospheric circulation features similar to those in ESMs. Notable weaknesses include overestimating the tracks and spatial extent of extratropical cyclones, biases in the teleconnected wave train triggered by tropical SST anomalies, and differences in upper-level warming and stratospheric circulation responses to SST warming compared to physics-based ESMs. The causes of these weaknesses were explored.
Layer-Order Inversion: Rethinking Latent Multi-Hop Reasoning in Large Language Models
Jan 07, 2026Large language models (LLMs) perform well on multi-hop reasoning, yet how they internally compose multiple facts remains unclear. Recent work proposes \emph{hop-aligned circuit hypothesis}, suggesting that bridge entities are computed sequentially across layers before later-hop answers. Through systematic analyses on real-world multi-hop queries, we show that this hop-aligned assumption does not generalize: later-hop answer entities can become decodable earlier than bridge entities, a phenomenon we call \emph{layer-order inversion}, which strengthens with total hops. To explain this behavior, we propose a \emph{probabilistic recall-and-extract} framework that models multi-hop reasoning as broad probabilistic recall in shallow MLP layers followed by selective extraction in deeper attention layers. This framework is empirically validated through systematic probing analyses, reinterpreting prior layer-wise decoding evidence, explaining chain-of-thought gains, and providing a mechanistic diagnosis of multi-hop failures despite correct single-hop knowledge. Code is available at https://github.com/laquabe/Layer-Order-Inversion.
SweRank+: Multilingual, Multi-Turn Code Ranking for Software Issue Localization
Dec 23, 2025Maintaining large-scale, multilingual codebases hinges on accurately localizing issues, which requires mapping natural-language error descriptions to the relevant functions that need to be modified. However, existing ranking approaches are often Python-centric and perform a single-pass search over the codebase. This work introduces SweRank+, a framework that couples SweRankMulti, a cross-lingual code ranking tool, with SweRankAgent, an agentic search setup, for iterative, multi-turn reasoning over the code repository. SweRankMulti comprises a code embedding retriever and a listwise LLM reranker, and is trained using a carefully curated large-scale issue localization dataset spanning multiple popular programming languages. SweRankAgent adopts an agentic search loop that moves beyond single-shot localization with a memory buffer to reason and accumulate relevant localization candidates over multiple turns. Our experiments on issue localization benchmarks spanning various languages demonstrate new state-of-the-art performance with SweRankMulti, while SweRankAgent further improves localization over single-pass ranking.
SSR: Socratic Self-Refine for Large Language Model Reasoning
Nov 13, 2025



Large Language Models (LLMs) have demonstrated remarkable reasoning abilities, yet existing test-time frameworks often rely on coarse self-verification and self-correction, limiting their effectiveness on complex tasks. In this paper, we propose Socratic Self-Refine (SSR), a novel framework for fine-grained evaluation and precise refinement of LLM reasoning. Our proposed SSR decomposes model responses into verifiable (sub-question, sub-answer) pairs, enabling step-level confidence estimation through controlled re-solving and self-consistency checks. By pinpointing unreliable steps and iteratively refining them, SSR produces more accurate and interpretable reasoning chains. Empirical results across five reasoning benchmarks and three LLMs show that SSR consistently outperforms state-of-the-art iterative self-refinement baselines. Beyond performance gains, SSR provides a principled black-box approach for evaluating and understanding the internal reasoning processes of LLMs. Code is available at https://github.com/SalesforceAIResearch/socratic-self-refine-reasoning.
Self-Abstraction from Grounded Experience for Plan-Guided Policy Refinement
Nov 08, 2025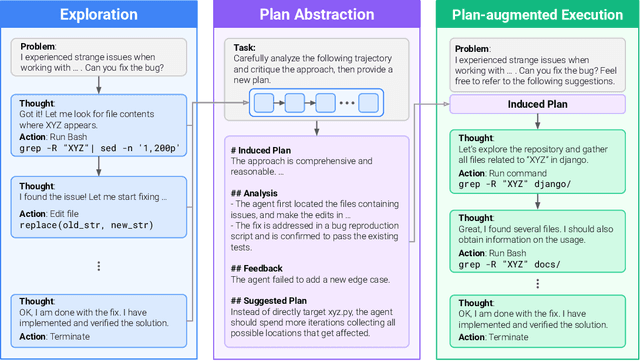

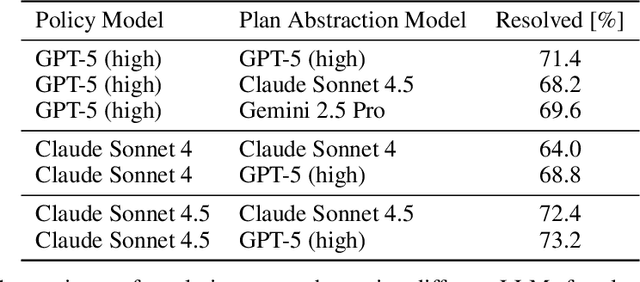
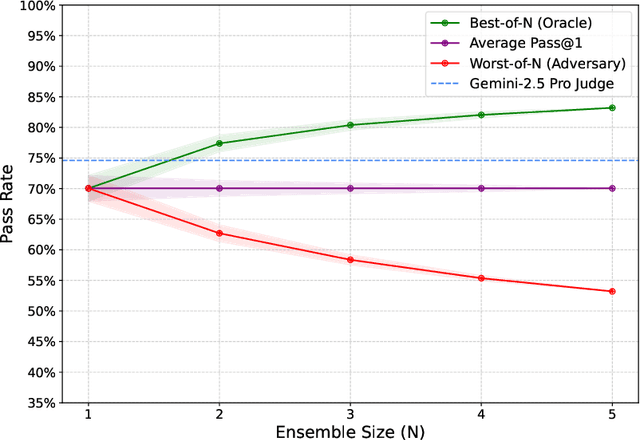
Large language model (LLM) based agents are increasingly used to tackle software engineering tasks that require multi-step reasoning and code modification, demonstrating promising yet limited performance. However, most existing LLM agents typically operate within static execution frameworks, lacking a principled mechanism to learn and self-improve from their own experience and past rollouts. As a result, their performance remains bounded by the initial framework design and the underlying LLM's capabilities. We propose Self-Abstraction from Grounded Experience (SAGE), a framework that enables agents to learn from their own task executions and refine their behavior through self-abstraction. After an initial rollout, the agent induces a concise plan abstraction from its grounded experience, distilling key steps, dependencies, and constraints. This learned abstraction is then fed back as contextual guidance, refining the agent's policy and supporting more structured, informed subsequent executions. Empirically, SAGE delivers consistent performance gains across diverse LLM backbones and agent architectures. Notably, it yields a 7.2% relative performance improvement over the strong Mini-SWE-Agent baseline when paired with the GPT-5 (high) backbone. SAGE further achieves strong overall performance on SWE-Bench Verified benchmark, reaching 73.2% and 74% Pass@1 resolve rates with the Mini-SWE-Agent and OpenHands CodeAct agent framework, respectively.
Self-Reflective Planning with Knowledge Graphs: Enhancing LLM Reasoning Reliability for Question Answering
May 26, 2025Recently, large language models (LLMs) have demonstrated remarkable capabilities in natural language processing tasks, yet they remain prone to hallucinations when reasoning with insufficient internal knowledge. While integrating LLMs with knowledge graphs (KGs) provides access to structured, verifiable information, existing approaches often generate incomplete or factually inconsistent reasoning paths. To this end, we propose Self-Reflective Planning (SRP), a framework that synergizes LLMs with KGs through iterative, reference-guided reasoning. Specifically, given a question and topic entities, SRP first searches for references to guide planning and reflection. In the planning process, it checks initial relations and generates a reasoning path. After retrieving knowledge from KGs through a reasoning path, it implements iterative reflection by judging the retrieval result and editing the reasoning path until the answer is correctly retrieved. Extensive experiments on three public datasets demonstrate that SRP surpasses various strong baselines and further underscore its reliable reasoning ability.
Know3-RAG: A Knowledge-aware RAG Framework with Adaptive Retrieval, Generation, and Filtering
May 19, 2025Recent advances in large language models (LLMs) have led to impressive progress in natural language generation, yet their tendency to produce hallucinated or unsubstantiated content remains a critical concern. To improve factual reliability, Retrieval-Augmented Generation (RAG) integrates external knowledge during inference. However, existing RAG systems face two major limitations: (1) unreliable adaptive control due to limited external knowledge supervision, and (2) hallucinations caused by inaccurate or irrelevant references. To address these issues, we propose Know3-RAG, a knowledge-aware RAG framework that leverages structured knowledge from knowledge graphs (KGs) to guide three core stages of the RAG process, including retrieval, generation, and filtering. Specifically, we introduce a knowledge-aware adaptive retrieval module that employs KG embedding to assess the confidence of the generated answer and determine retrieval necessity, a knowledge-enhanced reference generation strategy that enriches queries with KG-derived entities to improve generated reference relevance, and a knowledge-driven reference filtering mechanism that ensures semantic alignment and factual accuracy of references. Experiments on multiple open-domain QA benchmarks demonstrate that Know3-RAG consistently outperforms strong baselines, significantly reducing hallucinations and enhancing answer reliability.