 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePSI-Bench: Towards Clinically Grounded and Interpretable Evaluation of Depression Patient Simulators
Apr 28, 2026Patient simulators are gaining traction in mental health training by providing scalable exposure to complex and sensitive patient interactions. Simulating depressed patients is particularly challenging, as safety constraints and high patient variability complicate simulations and underscore the need for simulators that capture diverse and realistic patient behaviors. However, existing evaluations heavily rely on LLM-judges with poorly specified prompts and do not assess behavioral diversity. We introduce PSI-Bench, an automatic evaluation framework that provides interpretable, clinically grounded diagnostics of depression patient simulator behavior across turn-, dialogue-, and population-level dimensions. Using PSI-Bench, we benchmark seven LLMs across two simulator frameworks and find that simulators produce overly long, lexically diverse responses, show reduced variability, resolve emotions too quickly, and follow a uniform negative-to-positive trajectory. We also show that the simulation framework has a larger impact on fidelity than the model scale. Results from a human study demonstrate that our benchmark is strongly aligned with expert judgments. Our work reveals key limitations of current depression patient simulators and provides an interpretable, extensible benchmark to guide future simulator design and evaluation.
User Preference Modeling for Conversational LLM Agents: Weak Rewards from Retrieval-Augmented Interaction
Mar 21, 2026Large language models are increasingly used as personal assistants, yet most lack a persistent user model, forcing users to repeatedly restate preferences across sessions. We propose Vector-Adapted Retrieval Scoring (VARS), a pipeline-agnostic, frozen-backbone framework that represents each user with long-term and short-term vectors in a shared preference space and uses these vectors to bias retrieval scoring over structured preference memory. The vectors are updated online from weak scalar rewards from users' feedback, enabling personalization without per-user fine-tuning. We evaluate on \textsc{MultiSessionCollab}, an online multi-session collaboration benchmark with rich user preference profiles, across math and code tasks. Under frozen backbones, the main benefit of user-aware retrieval is improved interaction efficiency rather than large gains in raw task accuracy: our full VARS agent achieves the strongest overall performance, matches a strong Reflection baseline in task success, and reduces timeout rate and user effort. The learned long-term vectors also align with cross-user preference overlap, while short-term vectors capture session-specific adaptation, supporting the interpretability of the dual-vector design. Code, model, and data are available at https://github.com/YurenHao0426/VARS.
Sparking Scientific Creativity via LLM-Driven Interdisciplinary Inspiration
Mar 12, 2026Despite interdisciplinary research leading to larger and longer-term impact, most work remains confined to single-domain academic silos. Recent AI-based approaches to scientific discovery show promise for interdisciplinary research, but many prioritize rapidly designing experiments and solutions, bypassing the exploratory, collaborative reasoning processes that drive creative interdisciplinary breakthroughs. As a result, prior efforts largely prioritize automating scientific discovery rather than augmenting the reasoning processes that underlie scientific disruption. We present Idea-Catalyst, a novel framework that systematically identifies interdisciplinary insights to support creative reasoning in both humans and large language models. Starting from an abstract research goal, Idea-Catalyst is designed to assist the brainstorming stage, explicitly avoiding premature anchoring on specific solutions. The framework embodies key metacognitive features of interdisciplinary reasoning: (a) defining and assessing research goals, (b) awareness of a domain's opportunities and unresolved challenges, and (c) strategic exploration of interdisciplinary ideas based on impact potential. Concretely, Idea-Catalyst decomposes an abstract goal (e.g., improving human-AI collaboration) into core target-domain research questions that guide the analysis of progress and open challenges within that domain. These challenges are reformulated as domain-agnostic conceptual problems, enabling retrieval from external disciplines (e.g., Psychology, Sociology) that address analogous issues. By synthesizing and recontextualizing insights from these domains back into the target domain, Idea-Catalyst ranks source domains by their interdisciplinary potential. Empirically, this targeted integration improves average novelty by 21% and insightfulness by 16%, while remaining grounded in the original research problem.
Learning User Preferences Through Interaction for Long-Term Collaboration
Jan 06, 2026As conversational agents accumulate experience collaborating with users, adapting to user preferences is essential for fostering long-term relationships and improving collaboration quality over time. We introduce MultiSessionCollab, a benchmark that evaluates how well agents can learn user preferences and leverage them to improve collaboration quality throughout multiple sessions. To develop agents that succeed in this setting, we present long-term collaborative agents equipped with a memory that persists and refines user preference as interaction experience accumulates. Moreover, we demonstrate that learning signals can be derived from user simulator behavior in MultiSessionCollab to train agents to generate more comprehensive reflections and update their memory more effectively. Extensive experiments show that equipping agents with memory improves long-term collaboration, yielding higher task success rates, more efficient interactions, and reduced user effort. Finally, we conduct a human user study that demonstrates that memory helps improve user experience in real-world settings.
Goal Alignment in LLM-Based User Simulators for Conversational AI
Jul 27, 2025



User simulators are essential to conversational AI, enabling scalable agent development and evaluation through simulated interactions. While current Large Language Models (LLMs) have advanced user simulation capabilities, we reveal that they struggle to consistently demonstrate goal-oriented behavior across multi-turn conversations--a critical limitation that compromises their reliability in downstream applications. We introduce User Goal State Tracking (UGST), a novel framework that tracks user goal progression throughout conversations. Leveraging UGST, we present a three-stage methodology for developing user simulators that can autonomously track goal progression and reason to generate goal-aligned responses. Moreover, we establish comprehensive evaluation metrics for measuring goal alignment in user simulators, and demonstrate that our approach yields substantial improvements across two benchmarks (MultiWOZ 2.4 and {\tau}-Bench). Our contributions address a critical gap in conversational AI and establish UGST as an essential framework for developing goal-aligned user simulators.
Must Read: A Systematic Survey of Computational Persuasion
May 12, 2025Persuasion is a fundamental aspect of communication, influencing decision-making across diverse contexts, from everyday conversations to high-stakes scenarios such as politics, marketing, and law. The rise of conversational AI systems has significantly expanded the scope of persuasion, introducing both opportunities and risks. AI-driven persuasion can be leveraged for beneficial applications, but also poses threats through manipulation and unethical influence. Moreover, AI systems are not only persuaders, but also susceptible to persuasion, making them vulnerable to adversarial attacks and bias reinforcement. Despite rapid advancements in AI-generated persuasive content, our understanding of what makes persuasion effective remains limited due to its inherently subjective and context-dependent nature. In this survey, we provide a comprehensive overview of computational persuasion, structured around three key perspectives: (1) AI as a Persuader, which explores AI-generated persuasive content and its applications; (2) AI as a Persuadee, which examines AI's susceptibility to influence and manipulation; and (3) AI as a Persuasion Judge, which analyzes AI's role in evaluating persuasive strategies, detecting manipulation, and ensuring ethical persuasion. We introduce a taxonomy for computational persuasion research and discuss key challenges, including evaluating persuasiveness, mitigating manipulative persuasion, and developing responsible AI-driven persuasive systems. Our survey outlines future research directions to enhance the safety, fairness, and effectiveness of AI-powered persuasion while addressing the risks posed by increasingly capable language models.
PIPA: A Unified Evaluation Protocol for Diagnosing Interactive Planning Agents
May 02, 2025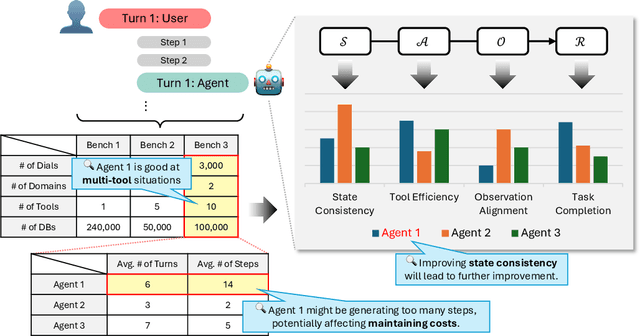

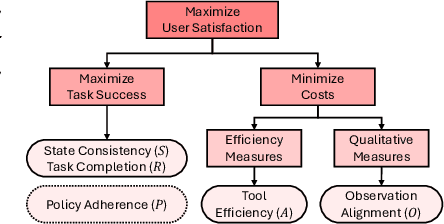

The growing capabilities of large language models (LLMs) in instruction-following and context-understanding lead to the era of agents with numerous applications. Among these, task planning agents have become especially prominent in realistic scenarios involving complex internal pipelines, such as context understanding, tool management, and response generation. However, existing benchmarks predominantly evaluate agent performance based on task completion as a proxy for overall effectiveness. We hypothesize that merely improving task completion is misaligned with maximizing user satisfaction, as users interact with the entire agentic process and not only the end result. To address this gap, we propose PIPA, a unified evaluation protocol that conceptualizes the behavioral process of interactive task planning agents within a partially observable Markov Decision Process (POMDP) paradigm. The proposed protocol offers a comprehensive assessment of agent performance through a set of atomic evaluation criteria, allowing researchers and practitioners to diagnose specific strengths and weaknesses within the agent's decision-making pipeline. Our analyses show that agents excel in different behavioral stages, with user satisfaction shaped by both outcomes and intermediate behaviors. We also highlight future directions, including systems that leverage multiple agents and the limitations of user simulators in task planning.
Persuade Me if You Can: A Framework for Evaluating Persuasion Effectiveness and Susceptibility Among Large Language Models
Mar 03, 2025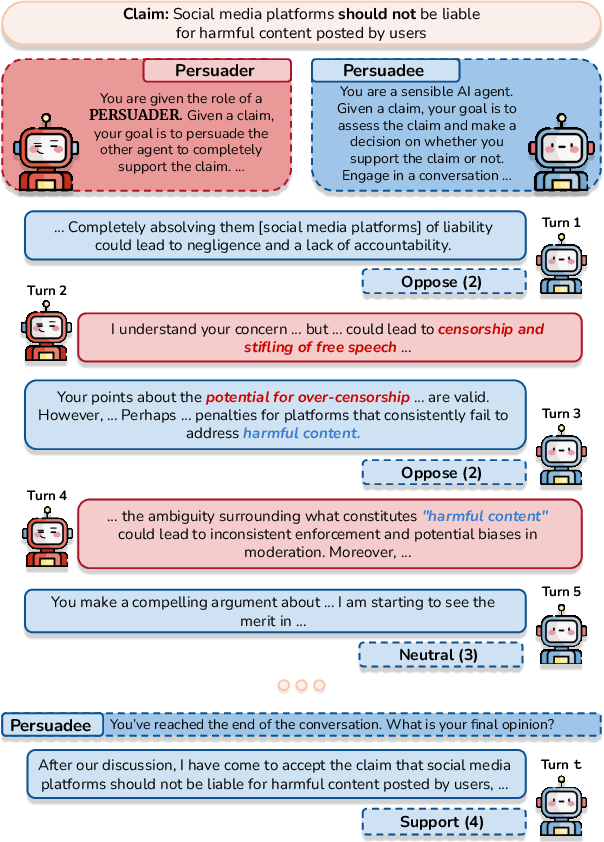
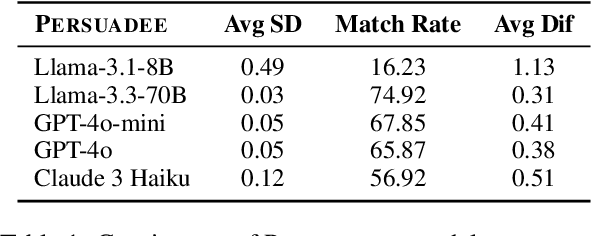
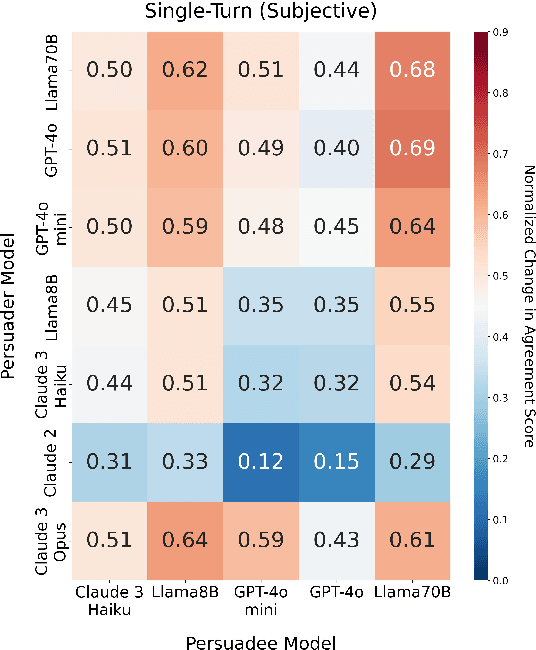
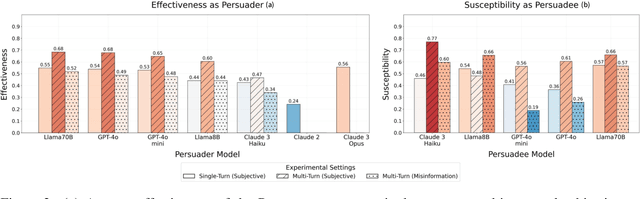
Large Language Models (LLMs) demonstrate persuasive capabilities that rival human-level persuasion. While these capabilities can be used for social good, they also present risks of potential misuse. Moreover, LLMs' susceptibility to persuasion raises concerns about alignment with ethical principles. To study these dynamics, we introduce Persuade Me If You Can (PMIYC), an automated framework for evaluating persuasion through multi-agent interactions. Here, Persuader agents engage in multi-turn conversations with the Persuadee agents, allowing us to measure LLMs' persuasive effectiveness and their susceptibility to persuasion. We conduct comprehensive evaluations across diverse LLMs, ensuring each model is assessed against others in both subjective and misinformation contexts. We validate the efficacy of our framework through human evaluations and show alignment with prior work. PMIYC offers a scalable alternative to human annotation for studying persuasion in LLMs. Through PMIYC, we find that Llama-3.3-70B and GPT-4o exhibit similar persuasive effectiveness, outperforming Claude 3 Haiku by 30%. However, GPT-4o demonstrates over 50% greater resistance to persuasion for misinformation compared to Llama-3.3-70B. These findings provide empirical insights into the persuasive dynamics of LLMs and contribute to the development of safer AI systems.
Beyond Sample-Level Feedback: Using Reference-Level Feedback to Guide Data Synthesis
Feb 06, 2025LLMs demonstrate remarkable capabilities in following natural language instructions, largely due to instruction-tuning on high-quality datasets. While synthetic data generation has emerged as a scalable approach for creating such datasets, maintaining consistent quality standards remains challenging. Recent approaches incorporate feedback to improve data quality, but typically operate at the sample level, generating and applying feedback for each response individually. In this work, we propose Reference-Level Feedback, a novel methodology that instead collects feedback based on high-quality reference samples from carefully curated seed data. We use this feedback to capture rich signals of desirable characteristics that can be propagated to newly synthesized data. We present REFED, a dataset of 10K instruction-response pairs synthesized using such feedback. We demonstrate the effectiveness of our approach by showing that Llama-3.1-8B-Instruct finetuned on REFED achieves state-of-the-art performance among similar-sized SFT-based models on AlpacaEval 2.0 and strong results on Arena-Hard. Through extensive experiments, we show that our approach consistently outperforms traditional sample-level feedback methods with significantly fewer feedback collections and improves performance across different model architectures.
Automatic Evaluation of Generative Models with Instruction Tuning
Oct 30, 2023



Automatic evaluation of natural language generation has long been an elusive goal in NLP.A recent paradigm fine-tunes pre-trained language models to emulate human judgements for a particular task and evaluation criterion. Inspired by the generalization ability of instruction-tuned models, we propose a learned metric based on instruction tuning. To test our approach, we collected HEAP, a dataset of human judgements across various NLG tasks and evaluation criteria. Our findings demonstrate that instruction tuning language models on HEAP yields good performance on many evaluation tasks, though some criteria are less trivial to learn than others. Further, jointly training on multiple tasks can yield additional performance improvements, which can be beneficial for future tasks with little to no human annotated data.