 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDLEBench: Evaluating Small-scale Object Editing Ability for Instruction-based Image Editing Model
Feb 27, 2026Significant progress has been made in the field of Instruction-based Image Editing Models (IIEMs). However, while these models demonstrate plausible adherence to instructions and strong reasoning ability on current benchmarks, their ability to edit small objects remains underexplored, despite its importance for precise local editing and refining details in both real and generated images. In this paper, we introduce DeepLookEditBench (DLEBench), the first benchmark dedicated to assessing the abilities of IIEMs in editing small-scale objects. Specifically, we construct a challenging testbed comprising 1889 samples across seven instruction types. In these samples, target objects occupy only 1%-10% of the image area, covering complex scenarios such as partial occlusion and multi-object editing. To ensure robust evaluation on this benchmark, we propose an evaluation protocol with refined score rubrics to minimize subjectivity and ambiguity in two criteria: Instruction Following and Visual Consistency. This protocol also introduces a dual-mode evaluation framework (Tool-driven and Oracle-guided Modes) addressing the misalignment between LMM-as-a-Judge and human judgements on DLEBench. Empirical results on 10 IIEMs reveal significant performance gaps in small-scale object editing, highlighting the need for specialized benchmarks to advance this ability.
CoDiQ: Test-Time Scaling for Controllable Difficult Question Generation
Feb 02, 2026Large Reasoning Models (LRMs) benefit substantially from training on challenging competition-level questions. However, existing automated question synthesis methods lack precise difficulty control, incur high computational costs, and struggle to generate competition-level questions at scale. In this paper, we propose CoDiQ (Controllable Difficult Question Generation), a novel framework enabling fine-grained difficulty control via test-time scaling while ensuring question solvability. Specifically, first, we identify a test-time scaling tendency (extended reasoning token budget boosts difficulty but reduces solvability) and the intrinsic properties defining the upper bound of a model's ability to generate valid, high-difficulty questions. Then, we develop CoDiQ-Generator from Qwen3-8B, which improves the upper bound of difficult question generation, making it particularly well-suited for challenging question construction. Building on the CoDiQ framework, we build CoDiQ-Corpus (44K competition-grade question sequences). Human evaluations show these questions are significantly more challenging than LiveCodeBench/AIME with over 82% solvability. Training LRMs on CoDiQ-Corpus substantially improves reasoning performance, verifying that scaling controlled-difficulty training questions enhances reasoning capabilities. We open-source CoDiQ-Corpus, CoDiQ-Generator, and implementations to support related research.
Two Minds Better Than One: Collaborative Reward Modeling for LLM Alignment
May 19, 2025Reward models (RMs) play a pivotal role in aligning large language models (LLMs) with human values. However, noisy preferences in human feedback can lead to reward misgeneralization - a phenomenon where reward models learn spurious correlations or overfit to noisy preferences, which poses important challenges to the generalization of RMs. This paper systematically analyzes the characteristics of preference pairs and aims to identify how noisy preferences differ from human-aligned preferences in reward modeling. Our analysis reveals that noisy preferences are difficult for RMs to fit, as they cause sharp training fluctuations and irregular gradient updates. These distinctive dynamics suggest the feasibility of identifying and excluding such noisy preferences. Empirical studies demonstrate that policy LLM optimized with a reward model trained on the full preference dataset, which includes substantial noise, performs worse than the one trained on a subset of exclusively high quality preferences. To address this challenge, we propose an online Collaborative Reward Modeling (CRM) framework to achieve robust preference learning through peer review and curriculum learning. In particular, CRM maintains two RMs that collaboratively filter potential noisy preferences by peer-reviewing each other's data selections. Curriculum learning synchronizes the capabilities of two models, mitigating excessive disparities to promote the utility of peer review. Extensive experiments demonstrate that CRM significantly enhances RM generalization, with up to 9.94 points improvement on RewardBench under an extreme 40\% noise. Moreover, CRM can seamlessly extend to implicit-reward alignment methods, offering a robust and versatile alignment strategy.
FRAbench and GenEval: Scaling Fine-Grained Aspect Evaluation across Tasks, Modalities
May 19, 2025Evaluating the open-ended outputs of large language models (LLMs) has become a bottleneck as model capabilities, task diversity, and modality coverage rapidly expand. Existing "LLM-as-a-Judge" evaluators are typically narrow in a few tasks, aspects, or modalities, and easily suffer from low consistency. In this paper, we argue that explicit, fine-grained aspect specification is the key to both generalizability and objectivity in automated evaluation. To do so, we introduce a hierarchical aspect taxonomy spanning 112 aspects that unifies evaluation across four representative settings - Natural Language Generation, Image Understanding, Image Generation, and Interleaved Text-and-Image Generation. Building on this taxonomy, we create FRAbench, a benchmark comprising 60.4k pairwise samples with 325k aspect-level labels obtained from a combination of human and LLM annotations. FRAbench provides the first large-scale, multi-modal resource for training and meta-evaluating fine-grained LMM judges. Leveraging FRAbench, we develop GenEval, a fine-grained evaluator generalizable across tasks and modalities. Experiments show that GenEval (i) attains high agreement with GPT-4o and expert annotators, (ii) transfers robustly to unseen tasks and modalities, and (iii) reveals systematic weaknesses of current LMMs on evaluation.
Toward Generalizable Evaluation in the LLM Era: A Survey Beyond Benchmarks
Apr 26, 2025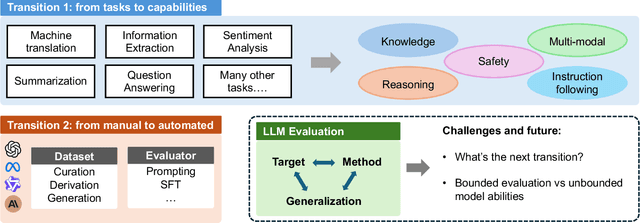
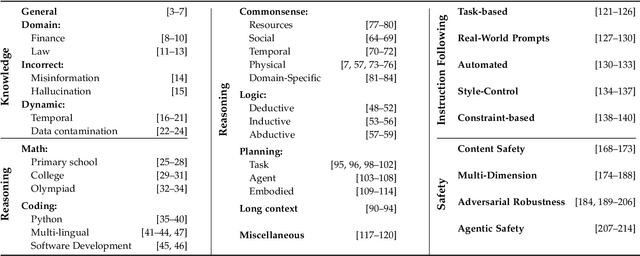
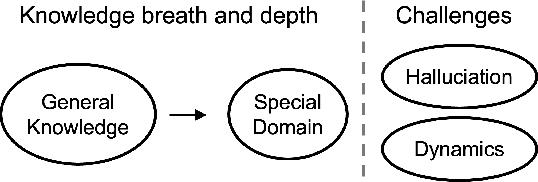
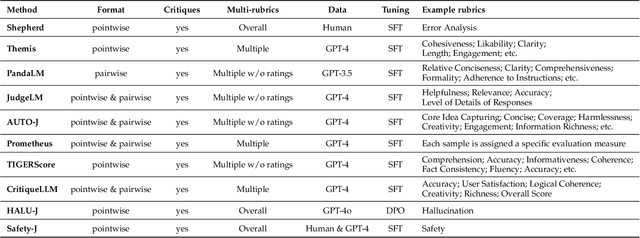
Large Language Models (LLMs) are advancing at an amazing speed and have become indispensable across academia, industry, and daily applications. To keep pace with the status quo, this survey probes the core challenges that the rise of LLMs poses for evaluation. We identify and analyze two pivotal transitions: (i) from task-specific to capability-based evaluation, which reorganizes benchmarks around core competencies such as knowledge, reasoning, instruction following, multi-modal understanding, and safety; and (ii) from manual to automated evaluation, encompassing dynamic dataset curation and "LLM-as-a-judge" scoring. Yet, even with these transitions, a crucial obstacle persists: the evaluation generalization issue. Bounded test sets cannot scale alongside models whose abilities grow seemingly without limit. We will dissect this issue, along with the core challenges of the above two transitions, from the perspectives of methods, datasets, evaluators, and metrics. Due to the fast evolving of this field, we will maintain a living GitHub repository (links are in each section) to crowd-source updates and corrections, and warmly invite contributors and collaborators.