 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrimming the Long-Tail of Visual World Modeling Evaluation
Jun 23, 2026Physical interactions follow a long-tailed distribution: a set of common and regular interactions dominates human experience and visual data, while a broad spectrum of rare and irregular interactions remains underrepresented. Although recent visual world models, including image and video generation models, achieve impressive realism on existing benchmarks, they primarily focus on simulating common physical interactions. This raises a central question: Do current visual world models internalize and generalize physical principles? In this work, we introduce Tailor-Bench, a benchmark that challenges world models to simulate irregular physical interactions. To enable systematic evaluation, we design three scenario modes that progressively challenge model reasoning: Regular scenarios reflect common tool-task pairs, Unconventional scenarios replace conventional tools with attribute-compatible substitutes to test affordance generalization, and Impossible scenarios introduce attribute-violating tools to probe constraint awareness. Additionally, we design two complementary settings under a unified evaluation protocol: predictive generation requires inferring outcomes without guidance, while descriptive generation specifies the target outcome for faithful realization. Our experimental results reveal a clear long-tail gap in physical world modeling: performance degrades from Regular to Unconventional and Impossible scenarios, indicating limited generalization beyond common interactions. Failure analysis further shows that models rely on superficial visual patterns: image models fail to realize correct state changes, while video models further suffer from temporal inconsistencies.
MemGuard: Preventing Memory Contamination in Long-Term Memory-Augmented Large Language Models
May 27, 2026Memory-augmented large language models extend reasoning beyond a fixed context window by maintaining long-term memory across interactions. However, existing memory systems often collapse stable user facts, episodic events, and behavioral rules into a shared space, allowing functionally distinct memories to be retrieved and used as interchangeable evidence. We identify this failure mode as heterogeneous memory contamination, where context-specific events become overgeneralized claims, or semantically relevant but functionally incompatible memories mislead generation. To this end, we introduce MemGuard, a type-aware memory framework that preserves functional memory boundaries during memory construction and retrieval. It assigns each memory an explicit functional role at write time, maintains relations across type-isolated memories, and selectively composes evidence only from necessary memory types, reducing contamination from irrelevant or functionally incompatible evidence. Across hallucination and long-horizon conversation benchmarks, MemGuard improves memory reliability by up to 28.27% while retrieving up to 5.8x fewer memory tokens than prior methods. These results suggest that reliable long-term reasoning depends on principled organization and selective use of heterogeneous memory.
Advancing Creative Physical Intelligence in Large Multimodal Models
May 25, 2026Large multimodal models (LMMs) have rapidly advanced in perception and reasoning; however, it remains unclear whether these capabilities generalize to discovering visually grounded solutions in open-ended environments, beyond pattern recognition. In such settings, intelligence requires more than answering well-posed questions: it involves identifying how elements in a scene can be repurposed in non-obvious yet physically feasible ways. This form of creative problem-solving is central to human intelligence, but remains largely untested in current benchmarks. To evaluate this ability, we introduce MM-CreativityBench, a benchmark for affordance-grounded creative tool use in visually rich, physically constrained environments. Each instance presents a scenario image with structured views of candidate entities and their parts, enabling fine-grained, interactive evaluation of how models iteratively inspect the scene, identify relevant affordances, and compose visually and physically grounded solutions. Our experiments show that current LMMs often fall short, not due to lack of generative capability, but because they do not sustain grounded exploration. Models often overlook relevant entities, under-examine critical parts, or hallucinate attributes not grounded in the image. Motivated by this failure mode, we propose affordance-grounded alignment, which casts creative tool use as a preference learning problem. Using Direct Preference Optimization, we encourage models to prefer attribute-affordance reasoning grounded in visual evidence over hallucinated alternatives. In addition, we incorporate supervision derived from an affordance knowledge base to guide broader entity exploration and multi-turn planning. Our results show consistent gains in selecting the correct entities and parts, while substantially reducing hallucination and grounding-related errors.
NarrativeTrack: Evaluating Video Language Models Beyond the Frame
Jan 03, 2026Multimodal large language models (MLLMs) have achieved impressive progress in vision-language reasoning, yet their ability to understand temporally unfolding narratives in videos remains underexplored. True narrative understanding requires grounding who is doing what, when, and where, maintaining coherent entity representations across dynamic visual and temporal contexts. We introduce NarrativeTrack, the first benchmark to evaluate narrative understanding in MLLMs through fine-grained entity-centric reasoning. Unlike existing benchmarks limited to short clips or coarse scene-level semantics, we decompose videos into constituent entities and examine their continuity via a Compositional Reasoning Progression (CRP), a structured evaluation framework that progressively increases narrative complexity across three dimensions: entity existence, entity changes, and entity ambiguity. CRP challenges models to advance from temporal persistence to contextual evolution and fine-grained perceptual reasoning. A fully automated entity-centric pipeline enables scalable extraction of temporally grounded entity representations, providing the foundation for CRP. Evaluations of state-of-the-art MLLMs reveal that models fail to robustly track entities across visual transitions and temporal dynamics, often hallucinating identity under context shifts. Open-source general-purpose MLLMs exhibit strong perceptual grounding but weak temporal coherence, while video-specific MLLMs capture temporal context yet hallucinate entity's contexts. These findings uncover a fundamental trade-off between perceptual grounding and temporal reasoning, indicating that narrative understanding emerges only from their integration. NarrativeTrack provides the first systematic framework to diagnose and advance temporally grounded narrative comprehension in MLLMs.
Visual Backdoor Attacks on MLLM Embodied Decision Making via Contrastive Trigger Learning
Oct 31, 2025Multimodal large language models (MLLMs) have advanced embodied agents by enabling direct perception, reasoning, and planning task-oriented actions from visual inputs. However, such vision driven embodied agents open a new attack surface: visual backdoor attacks, where the agent behaves normally until a visual trigger appears in the scene, then persistently executes an attacker-specified multi-step policy. We introduce BEAT, the first framework to inject such visual backdoors into MLLM-based embodied agents using objects in the environments as triggers. Unlike textual triggers, object triggers exhibit wide variation across viewpoints and lighting, making them difficult to implant reliably. BEAT addresses this challenge by (1) constructing a training set that spans diverse scenes, tasks, and trigger placements to expose agents to trigger variability, and (2) introducing a two-stage training scheme that first applies supervised fine-tuning (SFT) and then our novel Contrastive Trigger Learning (CTL). CTL formulates trigger discrimination as preference learning between trigger-present and trigger-free inputs, explicitly sharpening the decision boundaries to ensure precise backdoor activation. Across various embodied agent benchmarks and MLLMs, BEAT achieves attack success rates up to 80%, while maintaining strong benign task performance, and generalizes reliably to out-of-distribution trigger placements. Notably, compared to naive SFT, CTL boosts backdoor activation accuracy up to 39% under limited backdoor data. These findings expose a critical yet unexplored security risk in MLLM-based embodied agents, underscoring the need for robust defenses before real-world deployment.
Perception-Aware Policy Optimization for Multimodal Reasoning
Jul 08, 2025
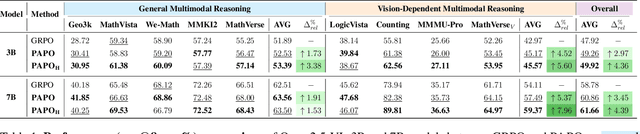
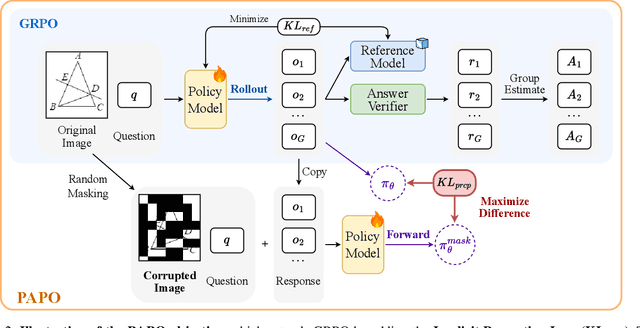
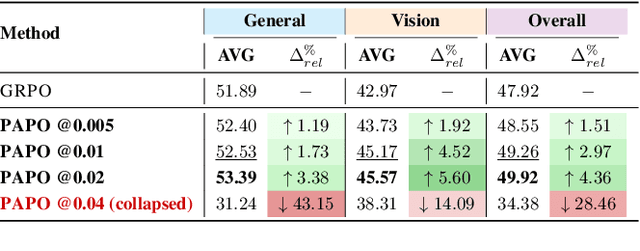
Reinforcement Learning with Verifiable Rewards (RLVR) has proven to be a highly effective strategy for endowing Large Language Models (LLMs) with robust multi-step reasoning abilities. However, its design and optimizations remain tailored to purely textual domains, resulting in suboptimal performance when applied to multimodal reasoning tasks. In particular, we observe that a major source of error in current multimodal reasoning lies in the perception of visual inputs. To address this bottleneck, we propose Perception-Aware Policy Optimization (PAPO), a simple yet effective extension of GRPO that encourages the model to learn to perceive while learning to reason, entirely from internal supervision signals. Notably, PAPO does not rely on additional data curation, external reward models, or proprietary models. Specifically, we introduce the Implicit Perception Loss in the form of a KL divergence term to the GRPO objective, which, despite its simplicity, yields significant overall improvements (4.4%) on diverse multimodal benchmarks. The improvements are more pronounced, approaching 8.0%, on tasks with high vision dependency. We also observe a substantial reduction (30.5%) in perception errors, indicating improved perceptual capabilities with PAPO. We conduct comprehensive analysis of PAPO and identify a unique loss hacking issue, which we rigorously analyze and mitigate through a Double Entropy Loss. Overall, our work introduces a deeper integration of perception-aware supervision into RLVR learning objectives and lays the groundwork for a new RL framework that encourages visually grounded reasoning. Project page: https://mikewangwzhl.github.io/PAPO.
Energy-Based Transformers are Scalable Learners and Thinkers
Jul 02, 2025



Inference-time computation techniques, analogous to human System 2 Thinking, have recently become popular for improving model performances. However, most existing approaches suffer from several limitations: they are modality-specific (e.g., working only in text), problem-specific (e.g., verifiable domains like math and coding), or require additional supervision/training on top of unsupervised pretraining (e.g., verifiers or verifiable rewards). In this paper, we ask the question "Is it possible to generalize these System 2 Thinking approaches, and develop models that learn to think solely from unsupervised learning?" Interestingly, we find the answer is yes, by learning to explicitly verify the compatibility between inputs and candidate-predictions, and then re-framing prediction problems as optimization with respect to this verifier. Specifically, we train Energy-Based Transformers (EBTs) -- a new class of Energy-Based Models (EBMs) -- to assign an energy value to every input and candidate-prediction pair, enabling predictions through gradient descent-based energy minimization until convergence. Across both discrete (text) and continuous (visual) modalities, we find EBTs scale faster than the dominant Transformer++ approach during training, achieving an up to 35% higher scaling rate with respect to data, batch size, parameters, FLOPs, and depth. During inference, EBTs improve performance with System 2 Thinking by 29% more than the Transformer++ on language tasks, and EBTs outperform Diffusion Transformers on image denoising while using fewer forward passes. Further, we find that EBTs achieve better results than existing models on most downstream tasks given the same or worse pretraining performance, suggesting that EBTs generalize better than existing approaches. Consequently, EBTs are a promising new paradigm for scaling both the learning and thinking capabilities of models.
PARTONOMY: Large Multimodal Models with Part-Level Visual Understanding
May 27, 2025Real-world objects are composed of distinctive, object-specific parts. Identifying these parts is key to performing fine-grained, compositional reasoning-yet, large multimodal models (LMMs) struggle to perform this seemingly straightforward task. In this work, we introduce PARTONOMY, an LMM benchmark designed for pixel-level part grounding. We construct PARTONOMY from existing part datasets and our own rigorously annotated set of images, encompassing 862 part labels and 534 object labels for evaluation. Unlike existing datasets that simply ask models to identify generic parts, PARTONOMY uses specialized concepts (e.g., agricultural airplane), and challenges models to compare objects' parts, consider part-whole relationships, and justify textual predictions with visual segmentations. Our experiments demonstrate significant limitations in state-of-the-art LMMs (e.g., LISA-13B achieves only 5.9% gIoU), highlighting a critical gap in their part grounding abilities. We note that existing segmentation-enabled LMMs (segmenting LMMs) have two key architectural shortcomings: they use special [SEG] tokens not seen during pretraining which induce distribution shift, and they discard predicted segmentations instead of using past predictions to guide future ones. To address these deficiencies, we train several part-centric LMMs and propose PLUM, a novel segmenting LMM that uses span tagging instead of segmentation tokens and that conditions on prior predictions in a feedback loop. We find that pretrained PLUM outperforms existing segmenting LMMs on reasoning segmentation, VQA, and visual hallucination benchmarks. In addition, PLUM finetuned on our proposed Explanatory Part Segmentation task is competitive with segmenting LMMs trained on significantly more segmentation data. Our work opens up new avenues towards enabling fine-grained, grounded visual understanding in LMMs.
Must Read: A Systematic Survey of Computational Persuasion
May 12, 2025Persuasion is a fundamental aspect of communication, influencing decision-making across diverse contexts, from everyday conversations to high-stakes scenarios such as politics, marketing, and law. The rise of conversational AI systems has significantly expanded the scope of persuasion, introducing both opportunities and risks. AI-driven persuasion can be leveraged for beneficial applications, but also poses threats through manipulation and unethical influence. Moreover, AI systems are not only persuaders, but also susceptible to persuasion, making them vulnerable to adversarial attacks and bias reinforcement. Despite rapid advancements in AI-generated persuasive content, our understanding of what makes persuasion effective remains limited due to its inherently subjective and context-dependent nature. In this survey, we provide a comprehensive overview of computational persuasion, structured around three key perspectives: (1) AI as a Persuader, which explores AI-generated persuasive content and its applications; (2) AI as a Persuadee, which examines AI's susceptibility to influence and manipulation; and (3) AI as a Persuasion Judge, which analyzes AI's role in evaluating persuasive strategies, detecting manipulation, and ensuring ethical persuasion. We introduce a taxonomy for computational persuasion research and discuss key challenges, including evaluating persuasiveness, mitigating manipulative persuasion, and developing responsible AI-driven persuasive systems. Our survey outlines future research directions to enhance the safety, fairness, and effectiveness of AI-powered persuasion while addressing the risks posed by increasingly capable language models.
Synthia: Novel Concept Design with Affordance Composition
Feb 25, 2025Text-to-image (T2I) models enable rapid concept design, making them widely used in AI-driven design. While recent studies focus on generating semantic and stylistic variations of given design concepts, functional coherence--the integration of multiple affordances into a single coherent concept--remains largely overlooked. In this paper, we introduce SYNTHIA, a framework for generating novel, functionally coherent designs based on desired affordances. Our approach leverages a hierarchical concept ontology that decomposes concepts into parts and affordances, serving as a crucial building block for functionally coherent design. We also develop a curriculum learning scheme based on our ontology that contrastively fine-tunes T2I models to progressively learn affordance composition while maintaining visual novelty. To elaborate, we (i) gradually increase affordance distance, guiding models from basic concept-affordance association to complex affordance compositions that integrate parts of distinct affordances into a single, coherent form, and (ii) enforce visual novelty by employing contrastive objectives to push learned representations away from existing concepts. Experimental results show that SYNTHIA outperforms state-of-the-art T2I models, demonstrating absolute gains of 25.1% and 14.7% for novelty and functional coherence in human evaluation, respectively.