 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFLAG: Flow Policy MaxEnt-RL by Latent Augmented Guidance
May 29, 2026Maximum entropy reinforcement learning (MaxEnt-RL) enables robust exploration, yet practical implementations often restrict policies to simple Gaussians. While recent approaches incorporate expressive generative policies via importance-weighted supervised learning, they are prone to importance weight collapse, which limits their scalability in high-dimensional action spaces. Our key insight is to mitigate this limitation by localizing the sampling region, avoiding the weight degeneracy induced by importance sampling over the entire action space. To instantiate this insight, we introduce \textbf{FLAG} (\textbf{F}low policy with \textbf{L}atent-\textbf{A}ugmented \textbf{G}uidance). FLAG augments the state space with a flow latent variable and optimizes a provably consistent proxy MaxEnt-RL objective. We empirically demonstrate that FLAG enables expressive policy optimization with limited importance samples and scales to high-dimensional control tasks. Furthermore, FLAG achieves state-of-the-art performance across challenging benchmarks. Our project webpage: https://flag-rl.github.io/
Domain-Adaptive Health Indicator Learning with Degradation-Stage Synchronized Sampling and Cross-Domain Autoencoder
Mar 11, 2026The construction of high quality health indicators (HIs) is crucial for effective prognostics and health management. Although deep learning has significantly advanced HI modeling, existing approaches often struggle with distribution mismatches resulting from varying operating conditions. Although domain adaptation is typically employed to mitigate these shifts, two critical challenges remain: (1) the misalignment of degradation stages during random mini-batch sampling, resulting in misleading discrepancy losses, and (2) the structural limitations of small-kernel 1D-CNNs in capturing long-range temporal dependencies within complex vibration signals. To address these issues, we propose a domain-adaptive framework comprising degradation stage synchronized batch sampling (DSSBS) and the cross-domain aligned fusion large autoencoder (CAFLAE). DSSBS utilizes kernel change-point detection to segment degradation stages, ensuring that source and target mini-batches are synchronized by their failure phases during alignment. Complementing this, CAFLAE integrates large-kernel temporal feature extraction with cross-attention mechanisms to learn superior domain-invariant representations. The proposed framework was rigorously validated on a Korean defense system dataset and the XJTU-SY bearing dataset, achieving an average performance enhancement of 24.1% over state-of-the-art methods. These results demonstrate that DSSBS improves cross-domain alignment through stage-consistent sampling, whereas CAFLAE offers a high-performance backbone for long-term industrial condition monitoring.
ACFormer: Mitigating Non-linearity with Auto Convolutional Encoder for Time Series Forecasting
Jan 28, 2026Time series forecasting (TSF) faces challenges in modeling complex intra-channel temporal dependencies and inter-channel correlations. Although recent research has highlighted the efficiency of linear architectures in capturing global trends, these models often struggle with non-linear signals. To address this gap, we conducted a systematic receptive field analysis of convolutional neural network (CNN) TSF models. We introduce the "individual receptive field" to uncover granular structural dependencies, revealing that convolutional layers act as feature extractors that mirror channel-wise attention while exhibiting superior robustness to non-linear fluctuations. Based on these insights, we propose ACFormer, an architecture designed to reconcile the efficiency of linear projections with the non-linear feature-extraction power of convolutions. ACFormer captures fine-grained information through a shared compression module, preserves temporal locality via gated attention, and reconstructs variable-specific temporal patterns using an independent patch expansion layer. Extensive experiments on multiple benchmark datasets demonstrate that ACFormer consistently achieves state-of-the-art performance, effectively mitigating the inherent drawbacks of linear models in capturing high-frequency components.
mCLM: A Function-Infused and Synthesis-Friendly Modular Chemical Language Model
May 18, 2025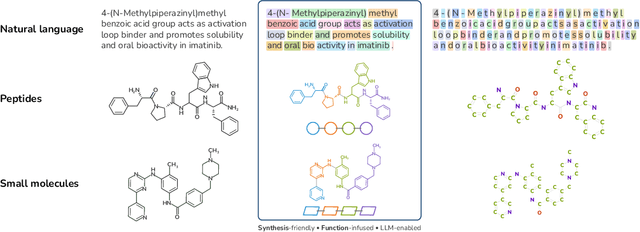
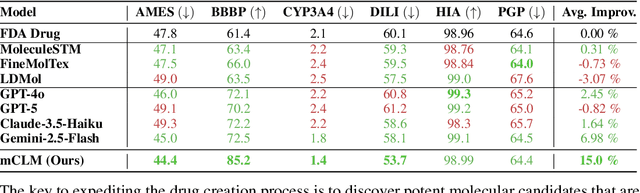
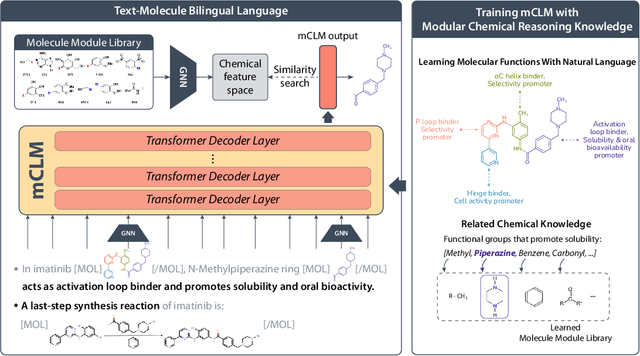
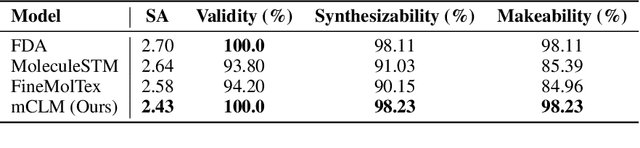
Despite their ability to understand chemical knowledge and accurately generate sequential representations, large language models (LLMs) remain limited in their capacity to propose novel molecules with drug-like properties. In addition, the molecules that LLMs propose can often be challenging to make in the lab. To more effectively enable the discovery of functional small molecules, LLMs need to learn a molecular language. However, LLMs are currently limited by encoding molecules from atoms. In this paper, we argue that just like tokenizing texts into (sub-)word tokens instead of characters, molecules should be decomposed and reassembled at the level of functional building blocks, i.e., parts of molecules that bring unique functions and serve as effective building blocks for real-world automated laboratory synthesis. This motivates us to propose mCLM, a modular Chemical-Language Model tokenizing molecules into building blocks and learning a bilingual language model of both natural language descriptions of functions and molecule building blocks. By reasoning on such functional building blocks, mCLM guarantees to generate efficiently synthesizable molecules thanks to recent progress in block-based chemistry, while also improving the functions of molecules in a principled manner. In experiments on 430 FDA-approved drugs, we find mCLM capable of significantly improving 5 out of 6 chemical functions critical to determining drug potentials. More importantly, mCLM can reason on multiple functions and improve the FDA-rejected drugs (``fallen angels'') over multiple iterations to greatly improve their shortcomings.