 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Beyond Deep Residual Learning for Image Restoration: Persistent Homology-Guided Manifold Simplification
Jun 08, 2017
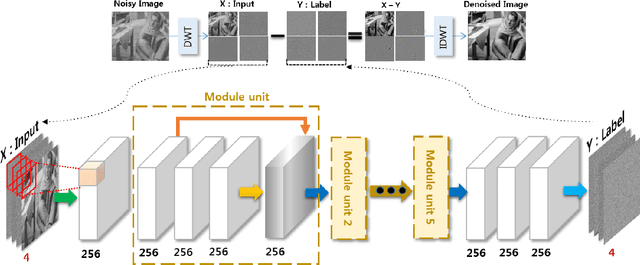
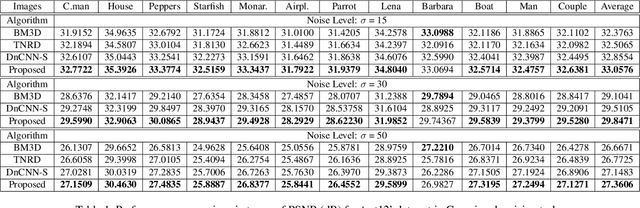
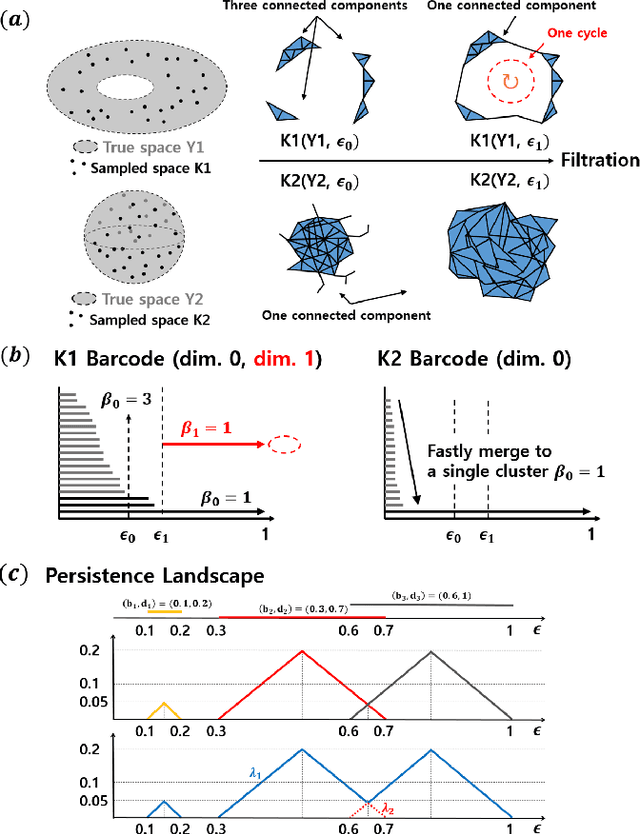
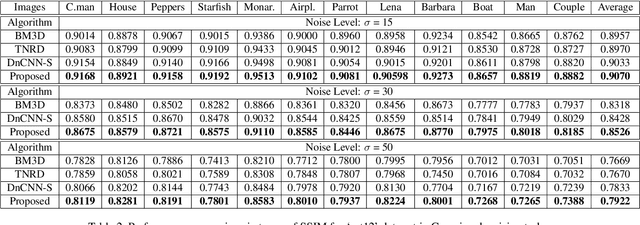
The latest deep learning approaches perform better than the state-of-the-art signal processing approaches in various image restoration tasks. However, if an image contains many patterns and structures, the performance of these CNNs is still inferior. To address this issue, here we propose a novel feature space deep residual learning algorithm that outperforms the existing residual learning. The main idea is originated from the observation that the performance of a learning algorithm can be improved if the input and/or label manifolds can be made topologically simpler by an analytic mapping to a feature space. Our extensive numerical studies using denoising experiments and NTIRE single-image super-resolution (SISR) competition demonstrate that the proposed feature space residual learning outperforms the existing state-of-the-art approaches. Moreover, our algorithm was ranked third in NTIRE competition with 5-10 times faster computational time compared to the top ranked teams. The source code is available on page : https://github.com/iorism/CNN.git
Content-Based Image Retrieval Using Multiresolution Analysis Of Shape-Based Classified Images
Oct 08, 2016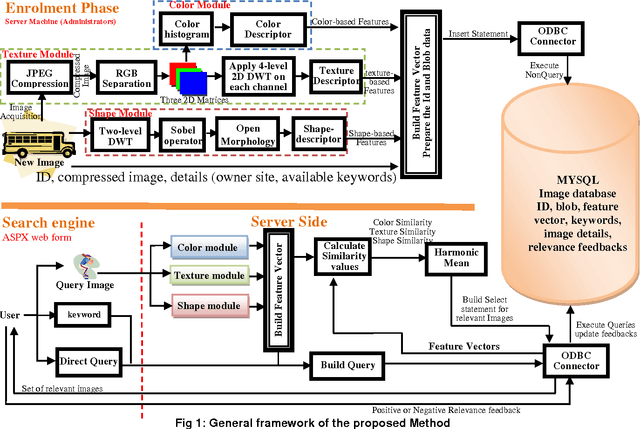
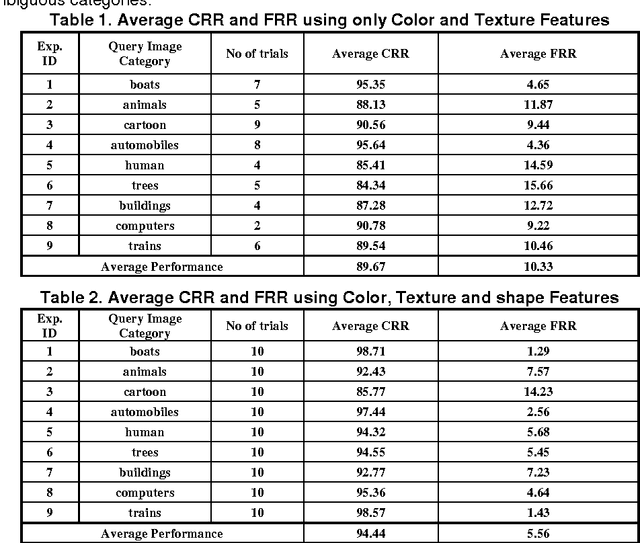


Content-Based Image Retrieval (CBIR) systems have been widely used for a wide range of applications such as Art collections, Crime prevention and Intellectual property. In this paper, a novel CBIR system, which utilizes visual contents (color, texture and shape) of an image to retrieve images, is proposed. The proposed system builds three feature vectors and stores them into MySQL database. The first feature vector uses descriptive statistics to describe the distribution of data in each channel of RGB channels of the image. The second feature vector describes the texture using eigenvalues of the 39 sub-bands that are generated after applying four levels 2D DWT in each channel (red, green and blue channels) of the image. These wavelets sub-bands perfectly describes the horizontal, vertical and diagonal edges that exist in the multi-resolution analysis of the image. The third feature vector describes the basic shapes that exist in the skeletonization version of the black and white representation of the image. Experimental results on a private MYSQL database that consists of 10000 images, using color, texture, shape and stored relevance feedbacks, showed 96.4% average correct retrieval rate in an efficient recovery time.
Synthetic Convolutional Features for Improved Semantic Segmentation
Sep 18, 2020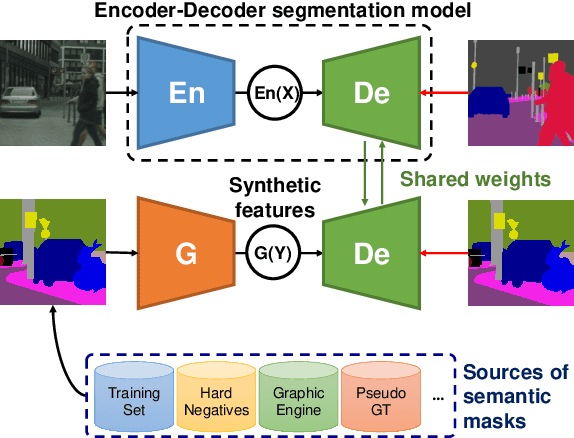
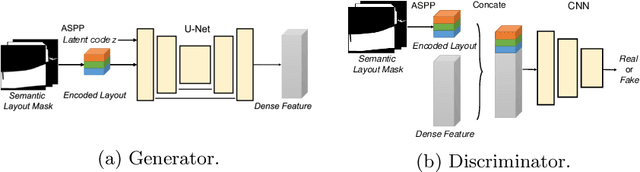
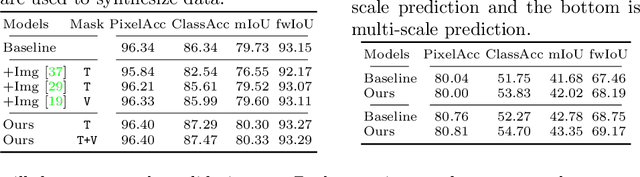

Recently, learning-based image synthesis has enabled to generate high-resolution images, either applying popular adversarial training or a powerful perceptual loss. However, it remains challenging to successfully leverage synthetic data for improving semantic segmentation with additional synthetic images. Therefore, we suggest to generate intermediate convolutional features and propose the first synthesis approach that is catered to such intermediate convolutional features. This allows us to generate new features from label masks and include them successfully into the training procedure in order to improve the performance of semantic segmentation. Experimental results and analysis on two challenging datasets Cityscapes and ADE20K show that our generated feature improves performance on segmentation tasks.
NTIRE 2020 Challenge on Perceptual Extreme Super-Resolution: Methods and Results
May 03, 2020
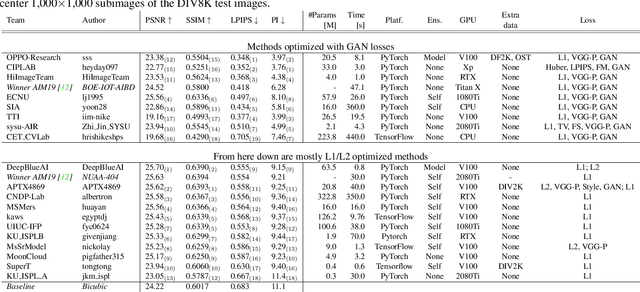

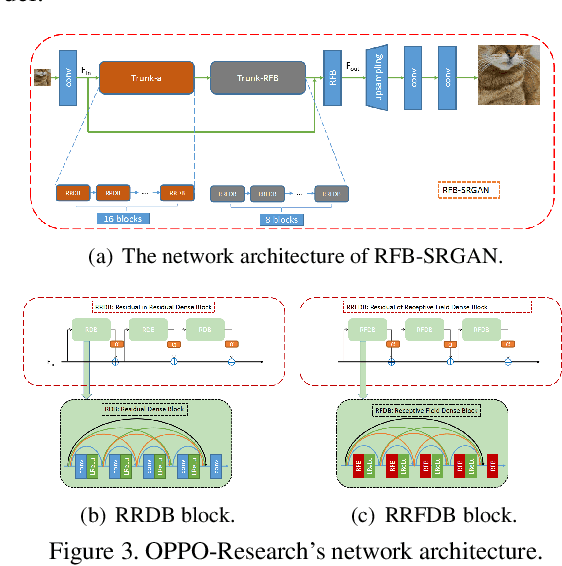
This paper reviews the NTIRE 2020 challenge on perceptual extreme super-resolution with focus on proposed solutions and results. The challenge task was to super-resolve an input image with a magnification factor 16 based on a set of prior examples of low and corresponding high resolution images. The goal is to obtain a network design capable to produce high resolution results with the best perceptual quality and similar to the ground truth. The track had 280 registered participants, and 19 teams submitted the final results. They gauge the state-of-the-art in single image super-resolution.
Textual Description for Mathematical Equations
Aug 07, 2020
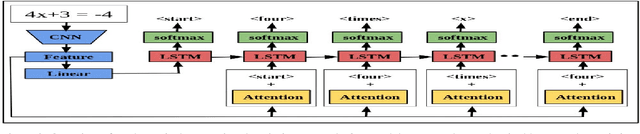


Reading of mathematical expression or equation in the document images is very challenging due to the large variability of mathematical symbols and expressions. In this paper, we pose reading of mathematical equation as a task of generation of the textual description which interprets the internal meaning of this equation. Inspired by the natural image captioning problem in computer vision, we present a mathematical equation description (MED) model, a novel end-to-end trainable deep neural network based approach that learns to generate a textual description for reading mathematical equation images. Our MED model consists of a convolution neural network as an encoder that extracts features of input mathematical equation images and a recurrent neural network with attention mechanism which generates description related to the input mathematical equation images. Due to the unavailability of mathematical equation image data sets with their textual descriptions, we generate two data sets for experimental purpose. To validate the effectiveness of our MED model, we conduct a real-world experiment to see whether the students are able to write equations by only reading or listening their textual descriptions or not. Experiments conclude that the students are able to write most of the equations correctly by reading their textual descriptions only.
* 8
Understanding How Image Quality Affects Deep Neural Networks
Apr 21, 2016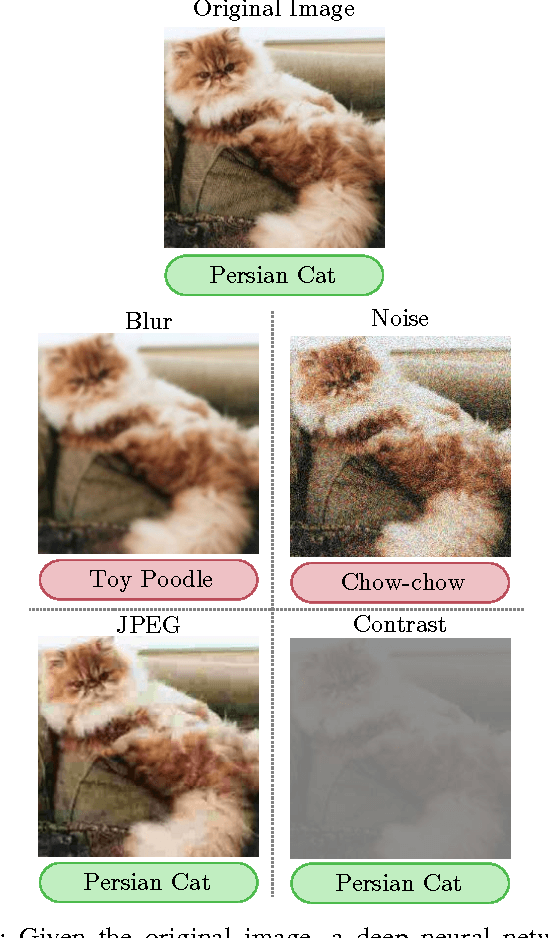
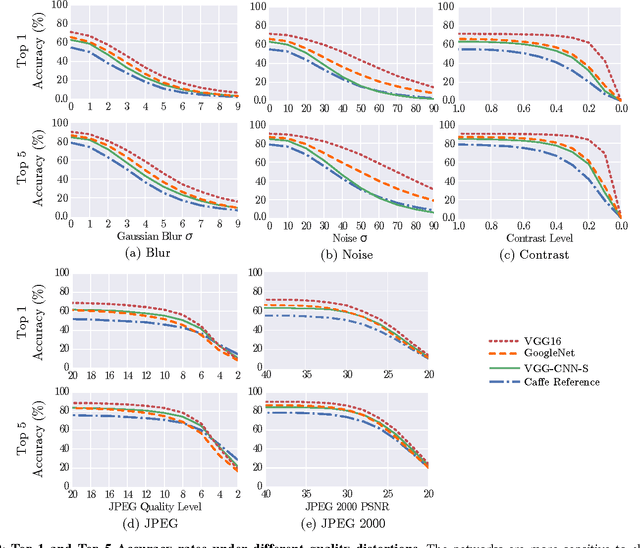

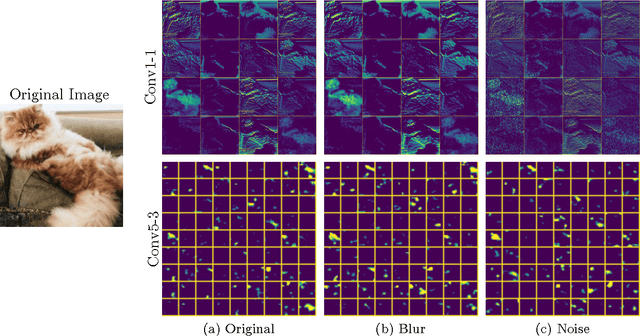
Image quality is an important practical challenge that is often overlooked in the design of machine vision systems. Commonly, machine vision systems are trained and tested on high quality image datasets, yet in practical applications the input images can not be assumed to be of high quality. Recently, deep neural networks have obtained state-of-the-art performance on many machine vision tasks. In this paper we provide an evaluation of 4 state-of-the-art deep neural network models for image classification under quality distortions. We consider five types of quality distortions: blur, noise, contrast, JPEG, and JPEG2000 compression. We show that the existing networks are susceptible to these quality distortions, particularly to blur and noise. These results enable future work in developing deep neural networks that are more invariant to quality distortions.
Diagnosis of Autism in Children using Facial Analysis and Deep Learning
Aug 06, 2020
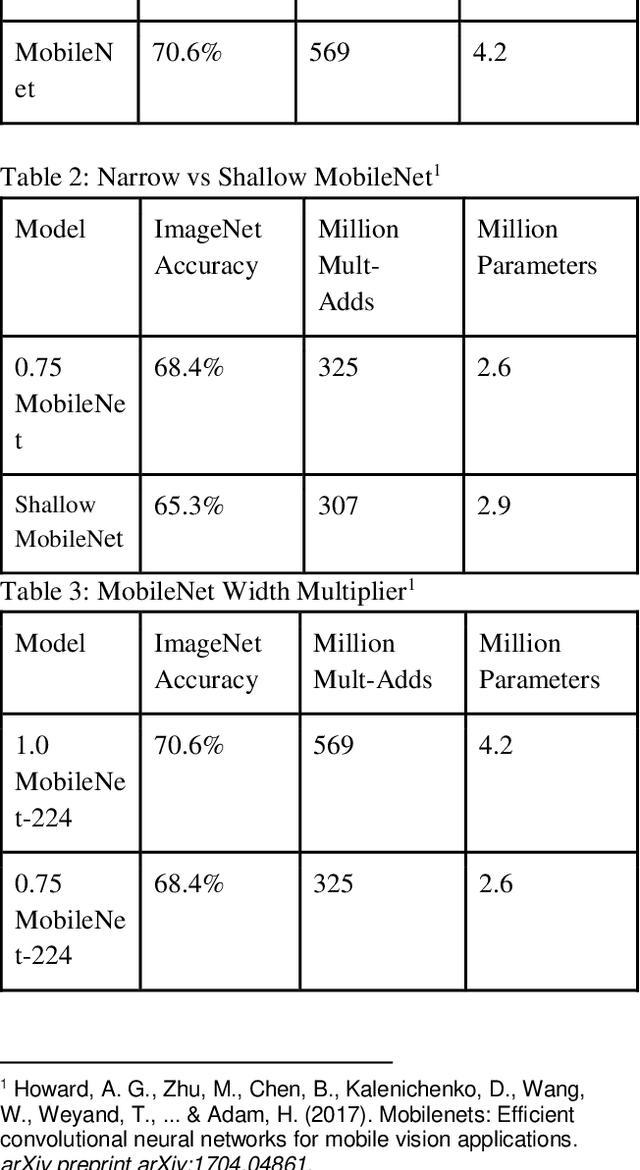
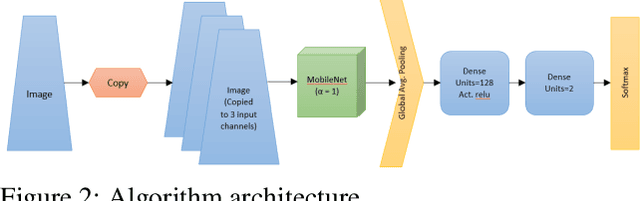
In this paper, we introduce a deep learning model to classify children as either healthy or potentially autistic with 94.6% accuracy using Deep Learning. Autistic patients struggle with social skills, repetitive behaviors, and communication, both verbal and nonverbal. Although the disease is considered to be genetic, the highest rates of accurate diagnosis occur when the child is tested on behavioral characteristics and facial features. Patients have a common pattern of distinct facial deformities, allowing researchers to analyze only an image of the child to determine if the child has the disease. While there are other techniques and models used for facial analysis and autism classification on their own, our proposal bridges these two ideas allowing classification in a cheaper, more efficient method. Our deep learning model uses MobileNet and two dense layers in order to perform feature extraction and image classification. The model is trained and tested using 3,014 images, evenly split between children with autism and children without it. 90% of the data is used for training, and 10% is used for testing. Based on our accuracy, we propose that the diagnosis of autism can be done effectively using only a picture. Additionally, there may be other diseases that are similarly diagnosable.
Learning Data-driven Reflectance Priors for Intrinsic Image Decomposition
Oct 08, 2015
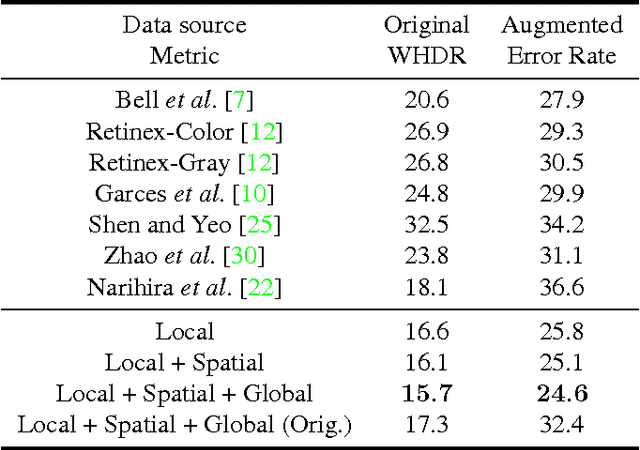
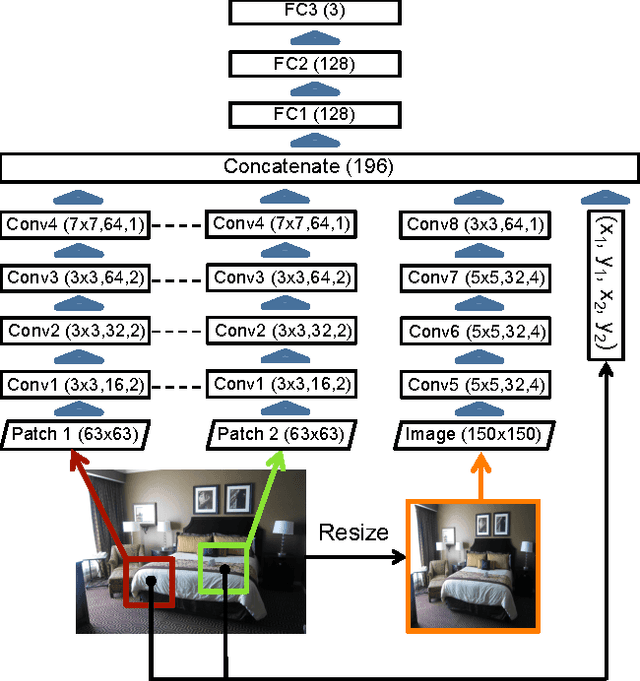

We propose a data-driven approach for intrinsic image decomposition, which is the process of inferring the confounding factors of reflectance and shading in an image. We pose this as a two-stage learning problem. First, we train a model to predict relative reflectance ordering between image patches (`brighter', `darker', `same') from large-scale human annotations, producing a data-driven reflectance prior. Second, we show how to naturally integrate this learned prior into existing energy minimization frameworks for intrinsic image decomposition. We compare our method to the state-of-the-art approach of Bell et al. on both decomposition and image relighting tasks, demonstrating the benefits of the simple relative reflectance prior, especially for scenes under challenging lighting conditions.
HATNet: An End-to-End Holistic Attention Network for Diagnosis of Breast Biopsy Images
Jul 25, 2020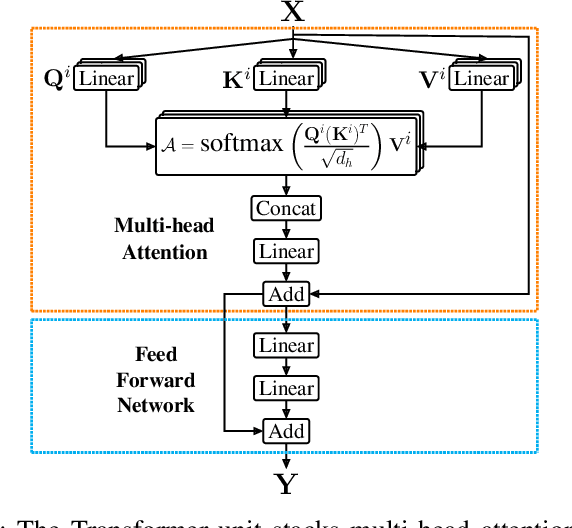
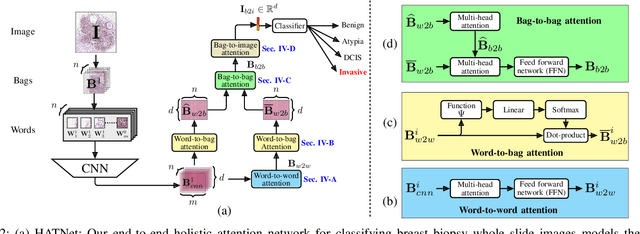
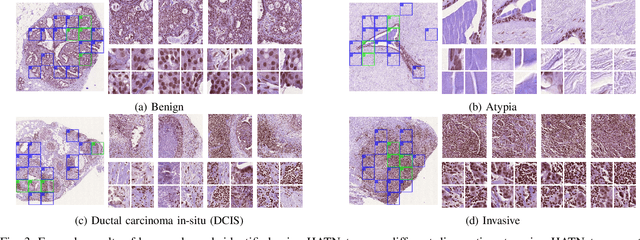
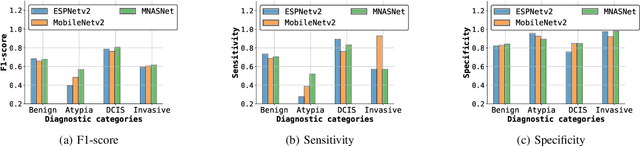
Training end-to-end networks for classifying gigapixel size histopathological images is computationally intractable. Most approaches are patch-based and first learn local representations (patch-wise) before combining these local representations to produce image-level decisions. However, dividing large tissue structures into patches limits the context available to these networks, which may reduce their ability to learn representations from clinically relevant structures. In this paper, we introduce a novel attention-based network, the Holistic ATtention Network (HATNet) to classify breast biopsy images. We streamline the histopathological image classification pipeline and show how to learn representations from gigapixel size images end-to-end. HATNet extends the bag-of-words approach and uses self-attention to encode global information, allowing it to learn representations from clinically relevant tissue structures without any explicit supervision. It outperforms the previous best network Y-Net, which uses supervision in the form of tissue-level segmentation masks, by 8%. Importantly, our analysis reveals that HATNet learns representations from clinically relevant structures, and it matches the classification accuracy of human pathologists for this challenging test set. Our source code is available at \url{https://github.com/sacmehta/HATNet}
Joint Self-Attention and Scale-Aggregation for Self-Calibrated Deraining Network
Aug 06, 2020
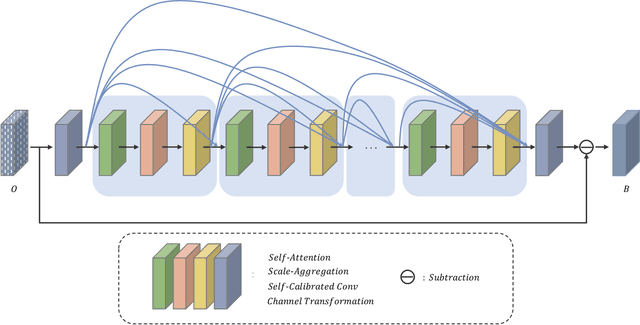
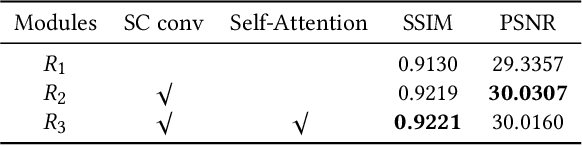
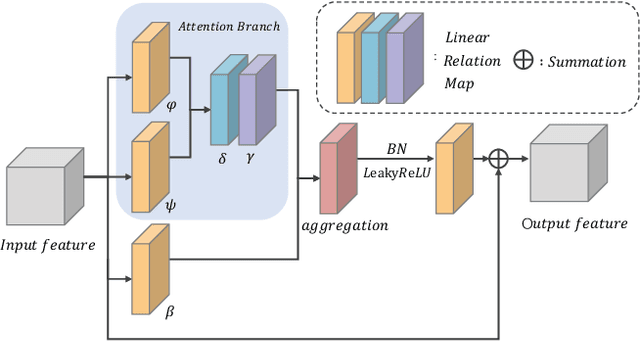
In the field of multimedia, single image deraining is a basic pre-processing work, which can greatly improve the visual effect of subsequent high-level tasks in rainy conditions. In this paper, we propose an effective algorithm, called JDNet, to solve the single image deraining problem and conduct the segmentation and detection task for applications. Specifically, considering the important information on multi-scale features, we propose a Scale-Aggregation module to learn the features with different scales. Simultaneously, Self-Attention module is introduced to match or outperform their convolutional counterparts, which allows the feature aggregation to adapt to each channel. Furthermore, to improve the basic convolutional feature transformation process of Convolutional Neural Networks (CNNs), Self-Calibrated convolution is applied to build long-range spatial and inter-channel dependencies around each spatial location that explicitly expand fields-of-view of each convolutional layer through internal communications and hence enriches the output features. By designing the Scale-Aggregation and Self-Attention modules with Self-Calibrated convolution skillfully, the proposed model has better deraining results both on real-world and synthetic datasets. Extensive experiments are conducted to demonstrate the superiority of our method compared with state-of-the-art methods. The source code will be available at \url{https://supercong94.wixsite.com/supercong94}.