 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFewer Steps, Better Performance: Efficient Cross-Modal Clip Trimming for Video Moment Retrieval Using Language
May 28, 2026Given an untrimmed video and a sentence query, video moment retrieval using language (VMR) aims to locate a target query-relevant moment. Since the untrimmed video is overlong, almost all existing VMR methods first sparsely down-sample each untrimmed video into multiple fixed-length video clips and then conduct multi-modal interactions with the query feature and expensive clip features for reasoning, which is infeasible for long real-world videos that span hours. Since the video is downsampled into fixed-length clips, some query-related frames may be filtered out, which will blur the specific boundary of the target moment, take the adjacent irrelevant frames as new boundaries, easily leading to cross-modal misalignment and introducing both boundary-bias and reasoning-bias. To this end, in this paper, we propose an efficient approach, SpotVMR, to trim the query-relevant clip. Besides, our proposed SpotVMR can serve as plug-and-play module, which achieves efficiency for state-of-the-art VMR methods while maintaining good retrieval performance. Especially, we first design a novel clip search model that learns to identify promising video regions to search conditioned on the language query. Then, we introduce a set of low-cost semantic indexing features to capture the context of objects and interactions that suggest where to search the query-relevant moment. Also, the distillation loss is utilized to address the optimization issues arising from end-to-end joint training of the clip selector and VMR model. Extensive experiments on three challenging datasets demonstrate its effectiveness.
The Fourth Challenge on Image Super-Resolution ($\times$4) at NTIRE 2026: Benchmark Results and Method Overview
Apr 16, 2026This paper presents the NTIRE 2026 image super-resolution ($\times$4) challenge, one of the associated competitions of the NTIRE 2026 Workshop at CVPR 2026. The challenge aims to reconstruct high-resolution (HR) images from low-resolution (LR) inputs generated through bicubic downsampling with a $\times$4 scaling factor. The objective is to develop effective super-resolution solutions and analyze recent advances in the field. To reflect the evolving objectives of image super-resolution, the challenge includes two tracks: (1) a restoration track, which emphasizes pixel-wise fidelity and ranks submissions based on PSNR; and (2) a perceptual track, which focuses on visual realism and evaluates results using a perceptual score. A total of 194 participants registered for the challenge, with 31 teams submitting valid entries. This report summarizes the challenge design, datasets, evaluation protocol, main results, and methods of participating teams. The challenge provides a unified benchmark and offers insights into current progress and future directions in image super-resolution.
NTIRE 2026 Challenge on Short-form UGC Video Restoration in the Wild with Generative Models: Datasets, Methods and Results
Apr 12, 2026This paper presents an overview of the NTIRE 2026 Challenge on Short-form UGC Video Restoration in the Wild with Generative Models. This challenge utilizes a new short-form UGC (S-UGC) video restoration benchmark, termed KwaiVIR, which is contributed by USTC and Kuaishou Technology. It contains both synthetically distorted videos and real-world short-form UGC videos in the wild. For this edition, the released data include 200 synthetic training videos, 48 wild training videos, 11 validation videos, and 20 testing videos. The primary goal of this challenge is to establish a strong and practical benchmark for restoring short-form UGC videos under complex real-world degradations, especially in the emerging paradigm of generative-model-based S-UGC video restoration. This challenge has two tracks: (i) the primary track is a subjective track, where the evaluation is based on a user study; (ii) the second track is an objective track. These two tracks enable a comprehensive assessment of restoration quality. In total, 95 teams have registered for this competition. And 12 teams submitted valid final solutions and fact sheets for the testing phase. The submitted methods achieved strong performance on the KwaiVIR benchmark, demonstrating encouraging progress in short-form UGC video restoration in the wild.
LoGoSeg: Integrating Local and Global Features for Open-Vocabulary Semantic Segmentation
Feb 05, 2026Open-vocabulary semantic segmentation (OVSS) extends traditional closed-set segmentation by enabling pixel-wise annotation for both seen and unseen categories using arbitrary textual descriptions. While existing methods leverage vision-language models (VLMs) like CLIP, their reliance on image-level pretraining often results in imprecise spatial alignment, leading to mismatched segmentations in ambiguous or cluttered scenes. However, most existing approaches lack strong object priors and region-level constraints, which can lead to object hallucination or missed detections, further degrading performance. To address these challenges, we propose LoGoSeg, an efficient single-stage framework that integrates three key innovations: (i) an object existence prior that dynamically weights relevant categories through global image-text similarity, effectively reducing hallucinations; (ii) a region-aware alignment module that establishes precise region-level visual-textual correspondences; and (iii) a dual-stream fusion mechanism that optimally combines local structural information with global semantic context. Unlike prior works, LoGoSeg eliminates the need for external mask proposals, additional backbones, or extra datasets, ensuring efficiency. Extensive experiments on six benchmarks (A-847, PC-459, A-150, PC-59, PAS-20, and PAS-20b) demonstrate its competitive performance and strong generalization in open-vocabulary settings.
Positive-Unlabeled Reinforcement Learning Distillation for On-Premise Small Models
Jan 28, 2026Due to constraints on privacy, cost, and latency, on-premise deployment of small models is increasingly common. However, most practical pipelines stop at supervised fine-tuning (SFT) and fail to reach the reinforcement learning (RL) alignment stage. The main reason is that RL alignment typically requires either expensive human preference annotation or heavy reliance on high-quality reward models with large-scale API usage and ongoing engineering maintenance, both of which are ill-suited to on-premise settings. To bridge this gap, we propose a positive-unlabeled (PU) RL distillation method for on-premise small-model deployment. Without human-labeled preferences or a reward model, our method distills the teacher's preference-optimization capability from black-box generations into a locally trainable student. For each prompt, we query the teacher once to obtain an anchor response, locally sample multiple student candidates, and perform anchor-conditioned self-ranking to induce pairwise or listwise preferences, enabling a fully local training loop via direct preference optimization or group relative policy optimization. Theoretical analysis justifies that the induced preference signal by our method is order-consistent and concentrates on near-optimal candidates, supporting its stability for preference optimization. Experiments demonstrate that our method achieves consistently strong performance under a low-cost setting.
Bridging Fidelity-Reality with Controllable One-Step Diffusion for Image Super-Resolution
Dec 16, 2025



Recent diffusion-based one-step methods have shown remarkable progress in the field of image super-resolution, yet they remain constrained by three critical limitations: (1) inferior fidelity performance caused by the information loss from compression encoding of low-quality (LQ) inputs; (2) insufficient region-discriminative activation of generative priors; (3) misalignment between text prompts and their corresponding semantic regions. To address these limitations, we propose CODSR, a controllable one-step diffusion network for image super-resolution. First, we propose an LQ-guided feature modulation module that leverages original uncompressed information from LQ inputs to provide high-fidelity conditioning for the diffusion process. We then develop a region-adaptive generative prior activation method to effectively enhance perceptual richness without sacrificing local structural fidelity. Finally, we employ a text-matching guidance strategy to fully harness the conditioning potential of text prompts. Extensive experiments demonstrate that CODSR achieves superior perceptual quality and competitive fidelity compared with state-of-the-art methods with efficient one-step inference.
FBA$^2$D: Frequency-based Black-box Attack for AI-generated Image Detection
Dec 10, 2025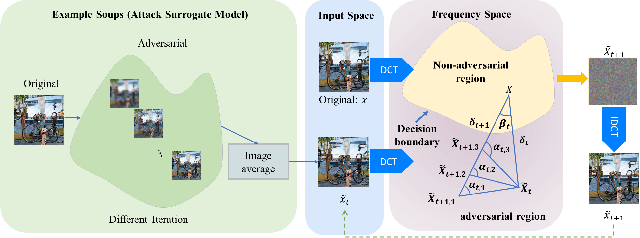
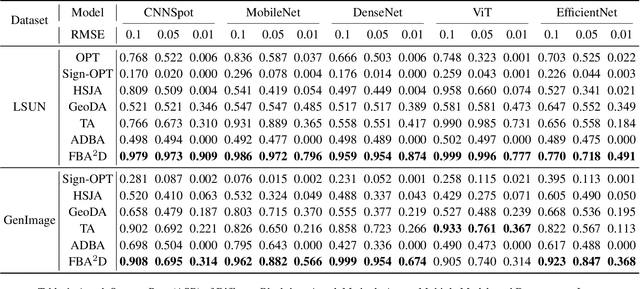
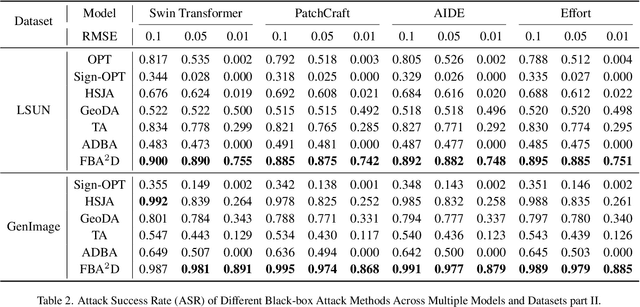

The prosperous development of Artificial Intelligence-Generated Content (AIGC) has brought people's anxiety about the spread of false information on social media. Designing detectors for filtering is an effective defense method, but most detectors will be compromised by adversarial samples. Currently, most studies exposing AIGC security issues assume information on model structure and data distribution. In real applications, attackers query and interfere with models that provide services in the form of application programming interfaces (APIs), which constitutes the black-box decision-based attack paradigm. However, to the best of our knowledge, decision-based attacks on AIGC detectors remain unexplored. In this study, we propose \textbf{FBA$^2$D}: a frequency-based black-box attack method for AIGC detection to fill the research gap. Motivated by frequency-domain discrepancies between generated and real images, we develop a decision-based attack that leverages the Discrete Cosine Transform (DCT) for fine-grained spectral partitioning and selects frequency bands as query subspaces, improving both query efficiency and image quality. Moreover, attacks on AIGC detectors should mitigate initialization failures, preserve image quality, and operate under strict query budgets. To address these issues, we adopt an ``adversarial example soup'' method, averaging candidates from successive surrogate iterations and using the result as the initialization to accelerate the query-based attack. The empirical study on the Synthetic LSUN dataset and GenImage dataset demonstrate the effectiveness of our prosed method. This study shows the urgency of addressing practical AIGC security problems.
SeniorTalk: A Chinese Conversation Dataset with Rich Annotations for Super-Aged Seniors
Mar 20, 2025While voice technologies increasingly serve aging populations, current systems exhibit significant performance gaps due to inadequate training data capturing elderly-specific vocal characteristics like presbyphonia and dialectal variations. The limited data available on super-aged individuals in existing elderly speech datasets, coupled with overly simple recording styles and annotation dimensions, exacerbates this issue. To address the critical scarcity of speech data from individuals aged 75 and above, we introduce SeniorTalk, a carefully annotated Chinese spoken dialogue dataset. This dataset contains 55.53 hours of speech from 101 natural conversations involving 202 participants, ensuring a strategic balance across gender, region, and age. Through detailed annotation across multiple dimensions, it can support a wide range of speech tasks. We perform extensive experiments on speaker verification, speaker diarization, speech recognition, and speech editing tasks, offering crucial insights for the development of speech technologies targeting this age group.
HLV-1K: A Large-scale Hour-Long Video Benchmark for Time-Specific Long Video Understanding
Jan 03, 2025



Multimodal large language models have become a popular topic in deep visual understanding due to many promising real-world applications. However, hour-long video understanding, spanning over one hour and containing tens of thousands of visual frames, remains under-explored because of 1) challenging long-term video analyses, 2) inefficient large-model approaches, and 3) lack of large-scale benchmark datasets. Among them, in this paper, we focus on building a large-scale hour-long long video benchmark, HLV-1K, designed to evaluate long video understanding models. HLV-1K comprises 1009 hour-long videos with 14,847 high-quality question answering (QA) and multi-choice question asnwering (MCQA) pairs with time-aware query and diverse annotations, covering frame-level, within-event-level, cross-event-level, and long-term reasoning tasks. We evaluate our benchmark using existing state-of-the-art methods and demonstrate its value for testing deep long video understanding capabilities at different levels and for various tasks. This includes promoting future long video understanding tasks at a granular level, such as deep understanding of long live videos, meeting recordings, and movies.
FaithDiff: Unleashing Diffusion Priors for Faithful Image Super-resolution
Nov 27, 2024



Faithful image super-resolution (SR) not only needs to recover images that appear realistic, similar to image generation tasks, but also requires that the restored images maintain fidelity and structural consistency with the input. To this end, we propose a simple and effective method, named FaithDiff, to fully harness the impressive power of latent diffusion models (LDMs) for faithful image SR. In contrast to existing diffusion-based SR methods that freeze the diffusion model pre-trained on high-quality images, we propose to unleash the diffusion prior to identify useful information and recover faithful structures. As there exists a significant gap between the features of degraded inputs and the noisy latent from the diffusion model, we then develop an effective alignment module to explore useful features from degraded inputs to align well with the diffusion process. Considering the indispensable roles and interplay of the encoder and diffusion model in LDMs, we jointly fine-tune them in a unified optimization framework, facilitating the encoder to extract useful features that coincide with diffusion process. Extensive experimental results demonstrate that FaithDiff outperforms state-of-the-art methods, providing high-quality and faithful SR results.